0-Lite-SAM Is Actually What You Need for Segment Everything
Lite-SAM Is Actually What You Need for Segment Everything

arXiv:2407.08965v1 [cs.CV] 12 Jul 2024
Lite-SAM 实际上是你实现万物分割所需的模型
背景
SAM凭借其卓越的性能为分割领域带来了重大变革,但其对计算资源的大量需求仍是一个限制因素。许多研究,如MobileSAM、Edge-SAM和MobileSAM-v2,都探索了轻量化解决方案。然而,它们采用的传统网格搜索采样策略或两阶段拼接方法无法进行端到端训练,这严重限制了SegEvery的性能。
传统网格搜索采样策略:在图像上均匀撒点(如 SAM 的 64×64 网格),或生成密集边界框,作为掩码解码器的输入提示。例如:
- SAM-B 在 SegEvery 中使用 64×64 的网格点(共 4096 个点),每个点生成 3 个掩码,总计 12288 个掩码,再通过 NMS 过滤冗余。
- MobileSAM 和 Edge-SAM 沿用类似策略,仅调整网格密度(如 32×32),但未改变 “穷举 - 过滤” 的本质。
网格点覆盖全图,包括背景和重复区域,导致大量冗余计算。例如:一张包含 5 个目标的图像,网格搜索可能生成数百个背景点提示,对应掩码均为无效。
对 SegEvery 的限制:
- 速度瓶颈:SAM-B 的 SegEvery 耗时 2084ms,其中 85% 时间用于网格点对应的掩码生成与过滤(如 Lite-SAM 论文表 3)。
- 精度损失:密集网格可能引入噪声提示(如背景点生成假阳性掩码),或稀疏网格漏掉细粒度目标(如物体部件)。
两阶段拼接方法:目标检测生成提示,使用独立目标检测模型(如 YOLOv8、Grounding DINO)生成边界框或点提示。例如:MobileSAM-v2 先通过 YOLOv8 检测目标框,再输入 SAM 解码器生成掩码。
将检测提示输入 SAM 解码器,生成掩码后拼接。两阶段独立训练,检测模型不感知分割需求。
Lite-SAM是一种用于SegEvery任务的高效端到端解决方案,旨在降低计算成本和冗余。
实验方法
Lite-SAM架构由四个主要组件构成:LiteViT编码器、AutoPPN网络、标准提示编码器以及SAM中的掩码解码器。全新的AutoPPN模块是专门为简化自动提示任务而设计的。它以端到端的方式同时对边界框提示和点提示进行回归,与以往研究中的密集位置编码方案相比,显著缩短了SegEvery任务的推理时间。这一进步是实现实时分割的关键。
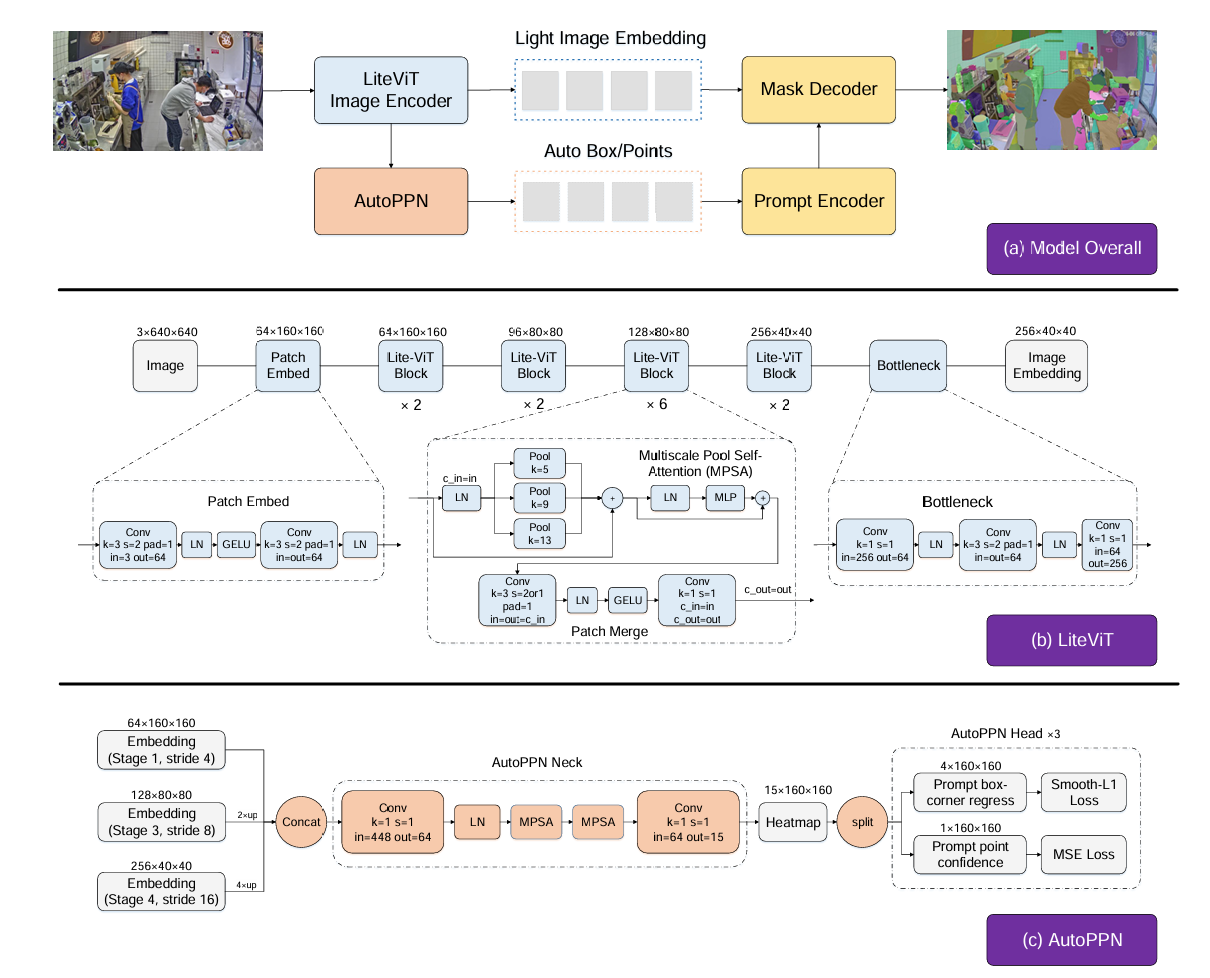
LiteViT
以 PoolFormer-S12 为基础,引入多尺度池化模块(MSPA) 增强网络各阶段的感受野,有效捕捉局部特征;LiteViT Block 内部通过 “MSPM 模块→卷积 MLP 模块→残差连接” 的流程处理输入,同时通过 Patch Merge 模块实现下采样与通道调整。
AutoPPN
端到端生成提示框与提示点,替代传统 Grid Search 采样方法,解决 SegEvery 任务的推理速度瓶颈。
- 用 MSPA 网络替换基础 stem 卷积网络,整合多尺度空间信息,提升对天空、建筑等大尺度目标的检测召回率;
- 引入距离变换估计提示点置信度,通过计算点与掩码的距离生成 “前景 - 背景” 软标签,优先识别目标中心点而非边界框中心,缓解提示歧义;损失计算采用硬挖掘 MSE 损失(H-MSE)替代传统 Focal-Loss,边界框回归仍用 Smooth-L1 损失、;
- 按目标边界框尺寸将掩码区域分为大(max (h/H_img,w/W_img)≥0.25)、中(0.05<max (…) <0.25)、小(max (…) ≤0.05)三组,分组计算损失以优化不同尺度目标的分割效果。
注意力块的选择
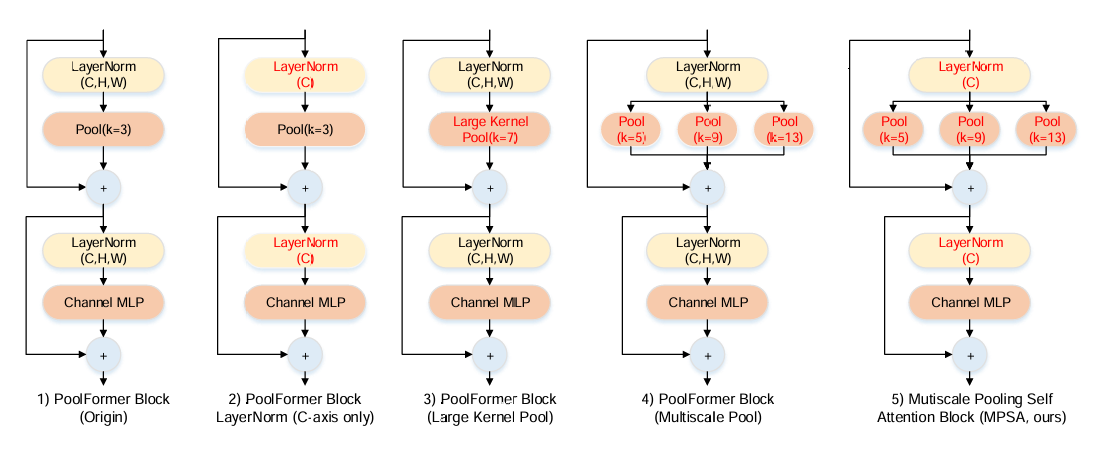
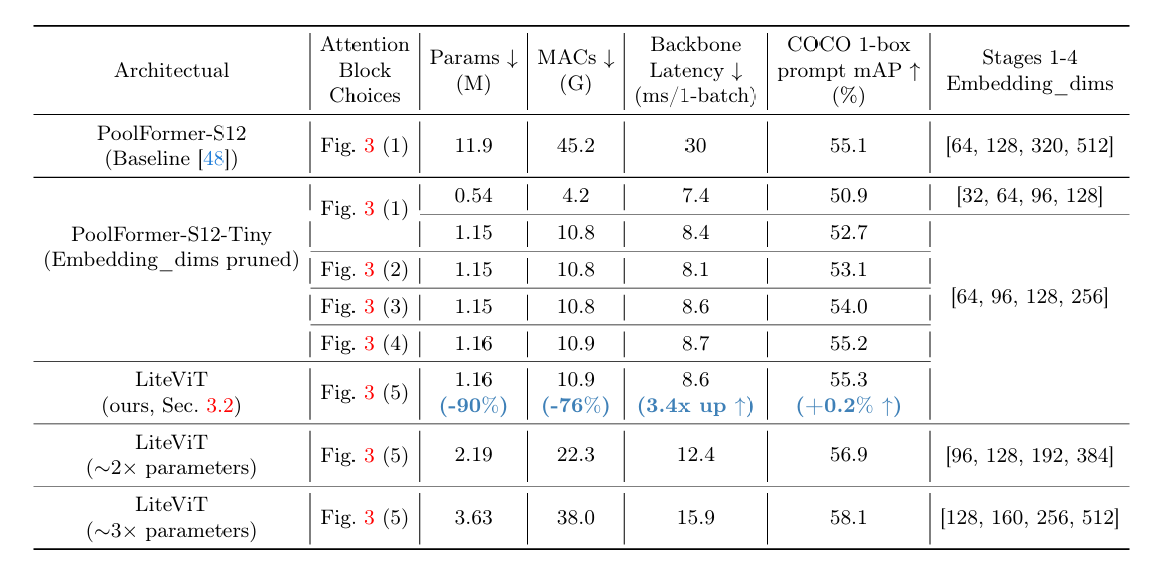
LiteViT在参数体积扩展到基准LiteViT网络的2倍和3倍时的性能指标,特别是其浮点运算次数(FLOPs)、延迟和评估指标。
实验结果
LiteSAM模块消融。
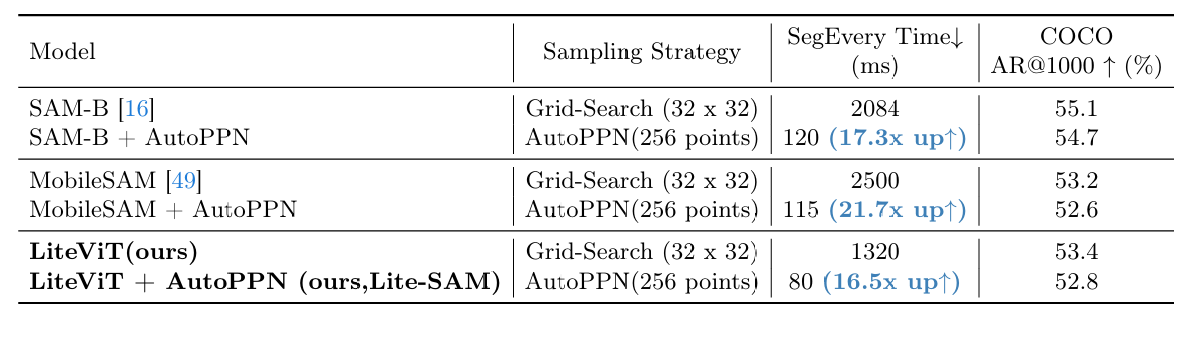
将模块与其他SAM模型结合的对比实验。
总结
本文提出的方法是对SAM的SegEvery模式的针对性性能和精度增强,有SegAny的能力,但是作者没有着重的将模型SegAny能力进行对比分析。Lite-SAM 解决了 SAM 系列模型在 SegEvery 任务中的计算冗余问题,满足移动设备、实时监控等资源受限场景的分割需求,为开放世界图像理解的实际应用提供可能。