0-Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Grounding DINO

arXiv:2303.05499v5 [cs.CV] 19 Jul 2024
背景
Grounding DINO 是一款通过将基于 Transformer 的检测器 DINO 与接地预训练相结合开发的开集目标检测器,能借助类别名称或指代表达等人类输入检测任意目标;其核心是通过紧密模态融合(含特征增强器、语言引导查询选择、跨模态解码器)和大规模接地预训练实现开集概念泛化,还提出子句级文本特征解决类别间无关影响问题;在多个基准测试中表现优异,如 COCO 零样本检测达52.5 AP、ODinW 零样本基准创26.1 AP新纪录,且可与 Stable Diffusion 结合用于图像编辑,同时也存在无法用于分割任务、部分场景假阳性等局限。
- 定位:一款面向开集场景的目标检测器,可将 AGI 系统在开世界场景的处理能力落地于目标检测任务。
- 核心目标:实现基于人类语言输入(如类别名称、指代表达)检测任意目标,即开集目标检测(文中将开集、开世界、开放词汇目标检测视为同一任务)。
实验方法
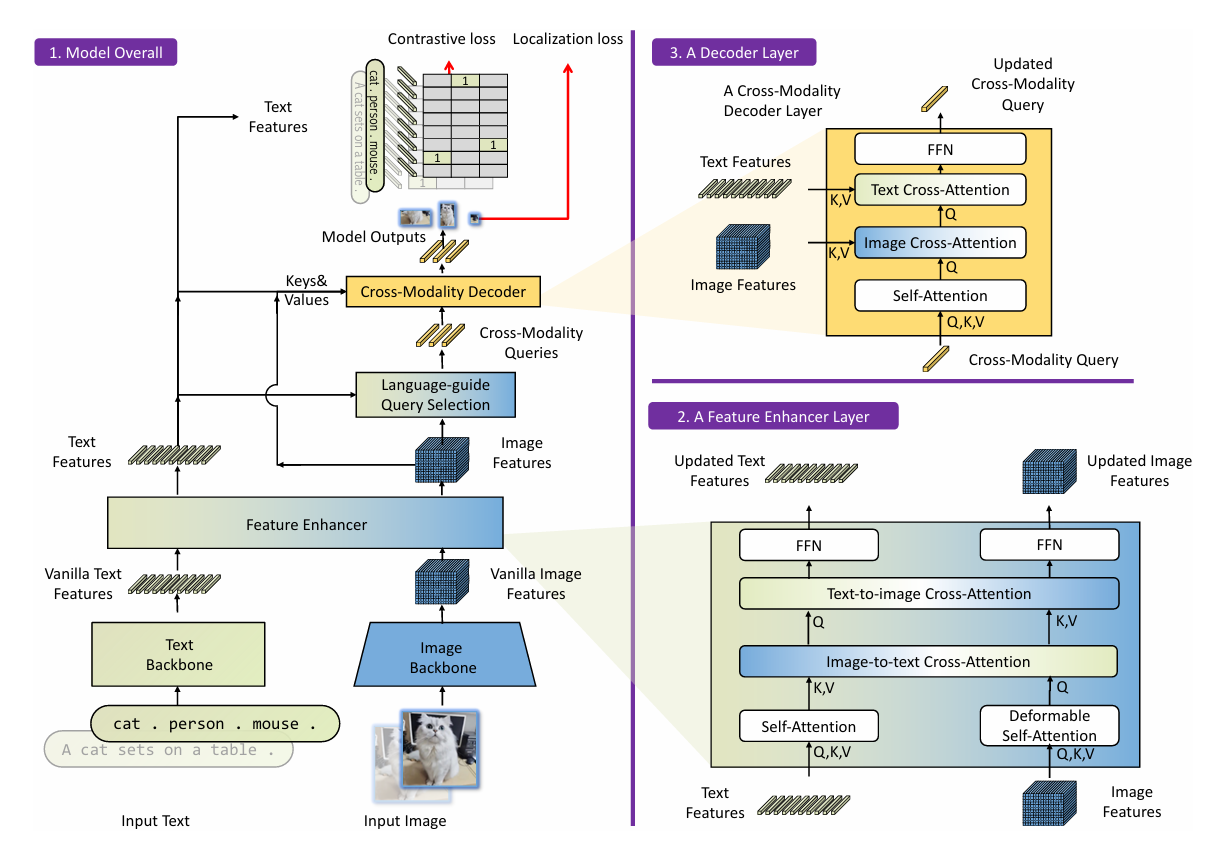
架构
Grounding DINO 为双编码器 - 单解码器架构,包含图像 backbone(如 Swin Transformer)、文本 backbone(如 BERT)、特征增强器、语言引导查询选择模块、跨模态解码器,处理流程如下:
- 图像与文本 backbone 分别提取原始图像特征和原始文本特征;
- 特征增强器对两类特征进行跨模态融合;
- 语言引导查询选择模块从融合后的图像特征中筛选跨模态查询;
- 跨模态解码器对查询优化,最终预测目标框与对应短语。
| 技术模块 | 核心设计 | 作用 |
|---|---|---|
| 特征增强器 | 每层含图像可变形自注意力(增强图像特征)、文本自注意力(增强文本特征)、图像 - 文本交叉注意力、文本 - 图像交叉注意力 | 实现图像与文本特征的早期融合与对齐,提升跨模态特征一致性 |
| 语言引导查询选择 | 计算图像特征与文本特征相似度,选取 Top-N(默认 900)相似图像特征作为解码器查询,查询含内容部分(可学习)和位置部分(动态锚框) | 确保初始化查询与文本输入高度相关,为后续目标检测提供精准引导 |
| 跨模态解码器 | 每层包含自注意力层、图像交叉注意力层、文本交叉注意力层、FFN 层,比 DINO 多文本交叉注意力层 | 持续融合图像与文本信息,优化查询表示,提升目标框预测与类别匹配精度 |
| 子句级文本特征 | 在文本编码时,通过注意力掩码阻断无关类别间的注意力交互 | 解决现有句子级(丢失细粒度信息)、单词级(类别间存在不必要依赖)文本表示的缺陷,提升特征提取准确性 |
损失函数
- 边界框回归:采用 L1 损失(衡量坐标误差)和 GIOU 损失(衡量框的重叠度);
- 分类:借鉴 GLIP,通过查询与文本特征的点积计算 logits,再用对比损失和 focal 损失优化;
- 辅助损失:在每个解码器层和编码器输出后添加辅助损失,稳定训练。
实验结果
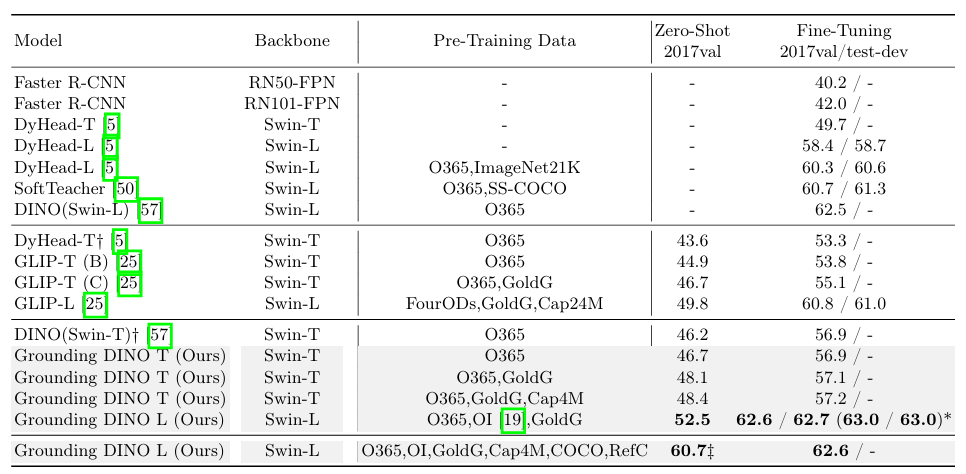
总结
限制:无法像 GLIPv2 一样用于分割任务;训练数据量少于大型 GLIP 模型,可能限制性能上限;部分场景会产生假阳性结果,存在 “幻觉” 问题。
首次在检测器的 “颈部(特征增强)- 查询初始化 - 头部(解码器)” 三阶段全流程融合语言信息,突破现有 “单阶段融合” 的局限,为跨模态检测提供新架构思路;子句级文本特征解决了 “多类别注意力干扰” 问题,比单词级表示提升 1.8~3.0 AP(LVIS 零样本),成为后续开集检测器的标准文本处理方案;首次在同一模型中验证三类任务的性能,证明开集检测器可通过接地预训练兼顾通用泛化与精细任务(如 REC),为后续研究提供评估基准。