0-EfficientViT-SAM:AcceleratedSegmentAnythingModel WithoutAccuracyLoss
EfficientViT-SAM:无损加速SAM

arXiv:2402.05008v2 [cs.CV] 16 May 2024
背景
尽管SAM有良好的效果,但是SAM计算却极其密集,这限制了它在时间敏感场景中的适用性。特别是,SAM的主要计算瓶颈是其图像编码器,它在推理时每张图像需要2973GMAC的计算。有类似Mobilesam、EDGESAM等方法轻量化图像编码器,降低了计算成本,但都遭受了大量的性能下降。
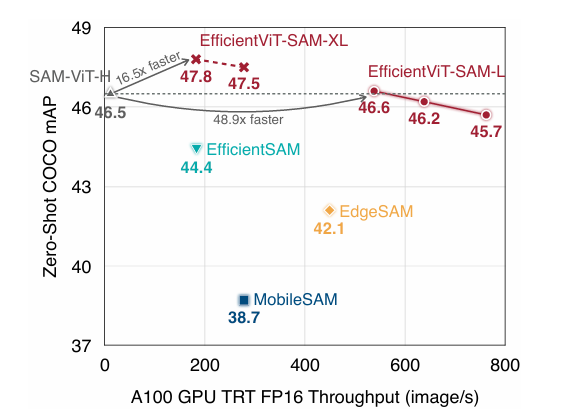
EfficientViT-SAM与其他轻量化SAM的准确率、效率对比。
本文提出的EfficientViT-SAM通过将SAM的庞大ViT图像编码器替换为高效的EfficientViT模型,并采用两阶段训练策略(知识蒸馏+端到端微调),成功实现了对Segment Anything Model(SAM)的加速与优化。该模型在保持SAM强大的零样本泛化能力(如在COCO/LVIS上DSC达86.4%)的同时,将A100 GPU的推理吞吐量提升48.9倍,且通过C++部署优化进一步降低边缘设备延迟至1秒内。其创新性地结合轻量级ReLU线性注意力与多尺度特征融合机制,为图像分割的实时化部署提供了新的架构范式。
实验方法
方法保留了SAM的提示编码器和掩码解码器架构,同时用EfficientViT替换图像编码器 。作者设计了两个系列型号,例如EfficientViT SAM-L和EfficientViTSAM-XL,在速度和性能之间提供了平衡的权衡 。
EfficientViT
详见EfficientViT。
EfficientViT-SAM
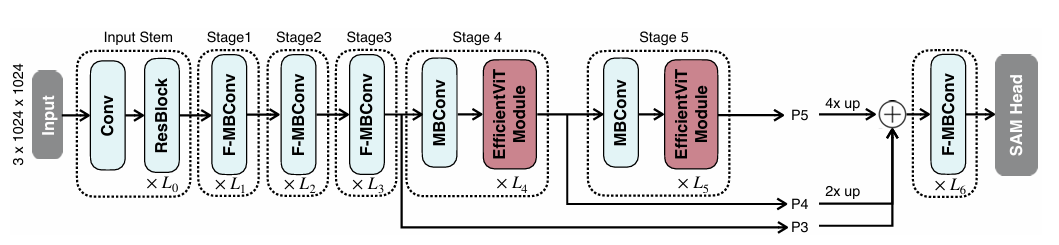
“ Resblock”是指RESNET34的基本构建块。 “ F-MBCONV”是指的MBCONV块。
在早期阶段使用卷积块,同时在最后两个阶段使用EfficientViT模块。通过上采样和添加来融合最近三个阶段的功能。融合功能被馈入Neck,其中包括几个融合的MBCONV块,然后喂到Sam Head。
训练
将SAM-VIT H嵌入图像嵌入到Efficientvit中。利用L2损失作为损失函数。ADAMW优化器的动量为β1= 0.9和 β2= 0.999。对于EfficientViTSAM-L/XL,初始学习率设置 为2e−6/1e−6,该学习率使用余弦衰减学习率计划将其衰减至0。关于数据增强,使用随机水平翻转
实验结果
运行时效率。
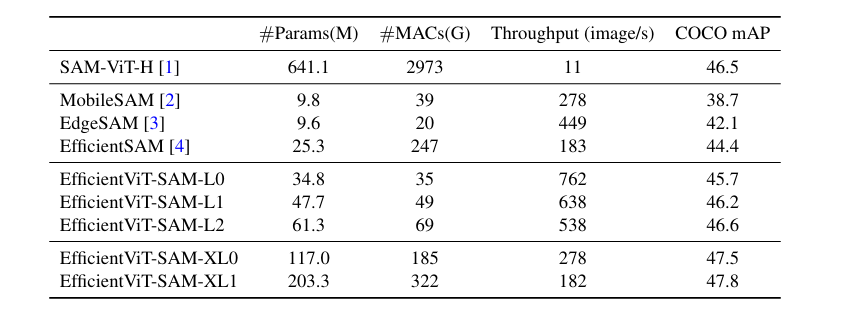
运行时效率比较。
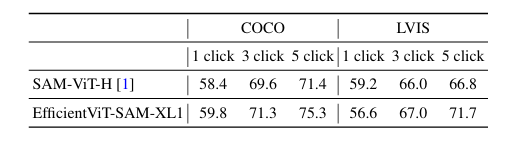
Zero-Shot点提示的分割结果。
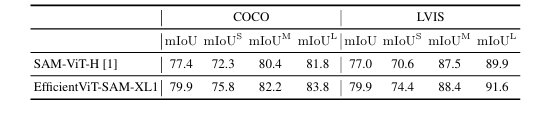
Zero-Shot框(GT)提示的分割结果。
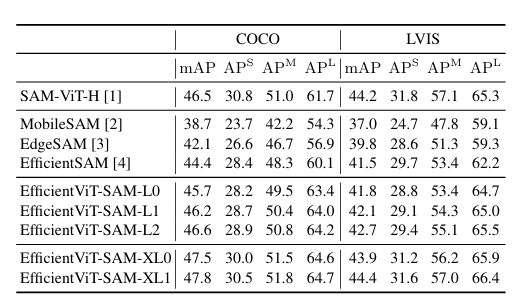
Zero-Shot对象检测器Vit-det框提示的分割结果。
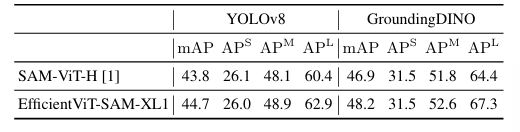
Zero-Shot YOLOv8/Grounding DINO 框提示的分割结果。
总结
这项工作介绍了 EfficientViT-SAM,它利用 EfficientViT 替代了 SAM 的图像编码器。EfficientViT-SAM 在不牺牲性能的情况下,在各种 zero-shot 分割任务中实现了对 SAM 的显著效率提升。