0-EfficientViT: Lightweight Multi-Scale Attention for High-Resolution Dense Prediction
EfficientViT:轻量级多尺度注意力用于高分辨率密集预测

背景
巨大的计算成本使得在硬件设备上部署最先进的高分辨率密集预测模型变得困难。本文提出了EfficientViT,通过创新的轻量级多尺度注意力机制,显著提升了高分辨率密集预测任务的效率与实用性:其核心贡献在于将传统Transformer的二次复杂度自注意力替换为ReLU线性注意力,结合硬件友好的小核卷积实现线性计算复杂度,同时通过多尺度令牌聚合捕获全局与局部特征,在语义分割、超分辨率等任务中(如Cityscapes数据集)相比SegFormer等模型实现3.8-8.8倍GPU加速。
实验方法
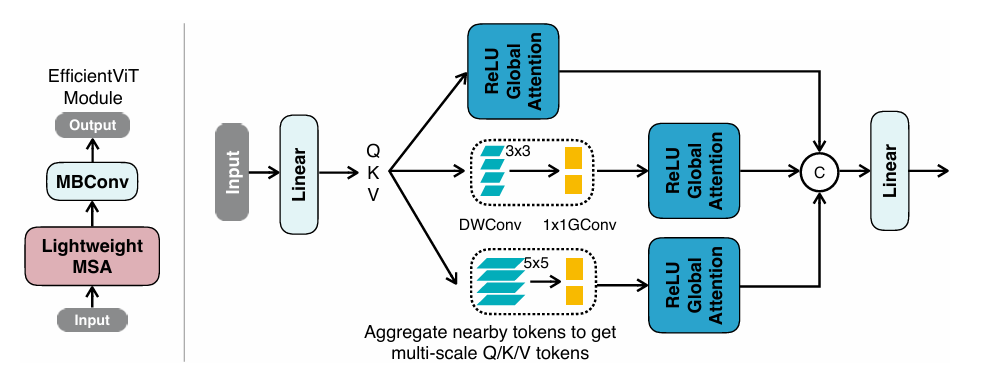
Left:EfficityVit的构建块(左)一个效率的构建块由轻巧的MSA模块和MBCONV组成。轻巧的MSA模块负责捕获上下文信息,而MBCONV则用于捕获本地信息。 Right:轻量多尺度注意力(右)通过线性投影层 获得Q/K/V令牌后,通过通过轻质小内核卷积聚集附近令牌来生成多尺度令牌。基于RELU的全局注意力应用 于多尺度令牌,输出是串联并馈送到最终线性投影层以进行特征融合。
轻量多尺度注意力
多尺度令牌生成:仅基于RELU的注意力就具有有限的模型能力。首先通过深度卷积来增强它,以提高其本地信息提取能力;仅使用小内核卷积 来进行信息聚合,以避免损害硬件效率。
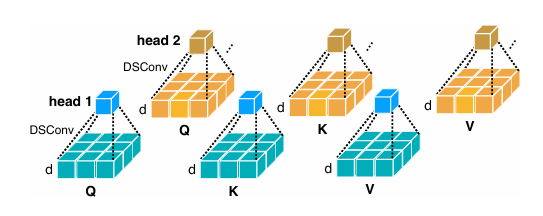
生成多尺度令牌的过程。
MSA模块:平衡了有效高分辨率致密预测的两个至关重要的算法,即性能和效率。这项改进的重点是优化了全局注意力涉及的硬件不友好的操作,比如Soft-Max,从而使其在硬件上更有效。
EfficientViT结构
包括一个轻巧的MSA模块和MBCONV。轻巧的MSA模块用于上下文信息的推断,而MBCONV则用于本地信息提取 。
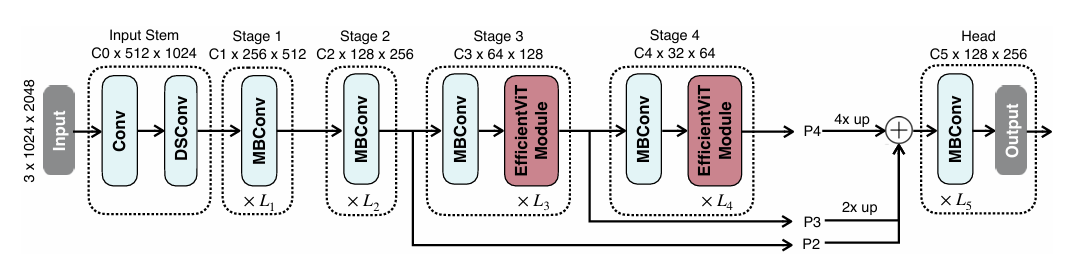
采用标准的backbone-head/encoder-decoder设计。在backbone中,将有效的模块插入第3和4stage。将特征从最近三个阶段(P2,P3和P4)馈入head部。采用了一个简单的头部设计,该设计由几个MBCONV块和输出层组成。
Backbone
该设计由输入茎和四个阶段组成,四个阶段逐渐减小了特征地图大小并逐渐增加了通道数。将EfficientViT模块插入第3阶段和第4阶段。对于下采样,使用带有步幅2的MBCONV。
Head
P2,P3和P4表示阶段2、3和4的输出,形成了特征图的金字塔。为了简化和效率,使用1x1卷积和标准的上采样操作(例如,双线性/双线性/双尺寸 UPPLING)来匹配它们的空间和通道大小,并通过添加来融合它们。由于Backbone已经具有很强的信息提取能力,因此采用了一个简单的Head部设计,该设计包括几个MBCONV块和输出层(即预测和UpSample)。
实验结果
在语义分割和超分辨率数据集上进行实验。
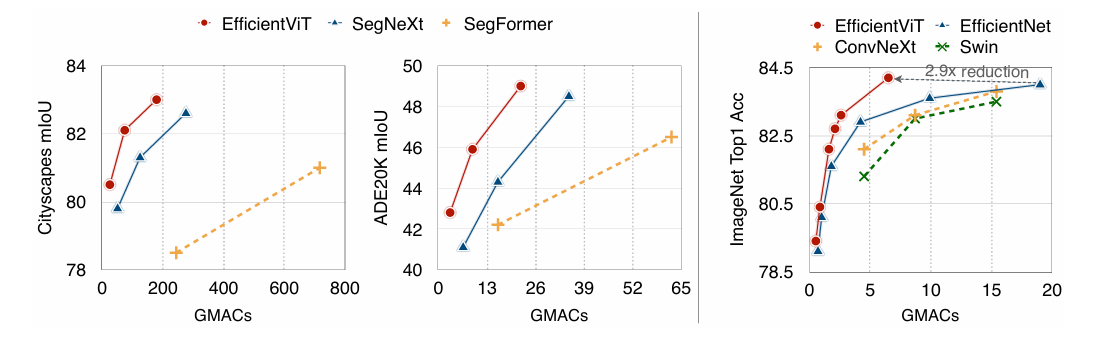
MAC与性能。与SOTA语义分割和图像分类模型相比,EfficientViT在MAC和性能之间提供了更好的权衡.
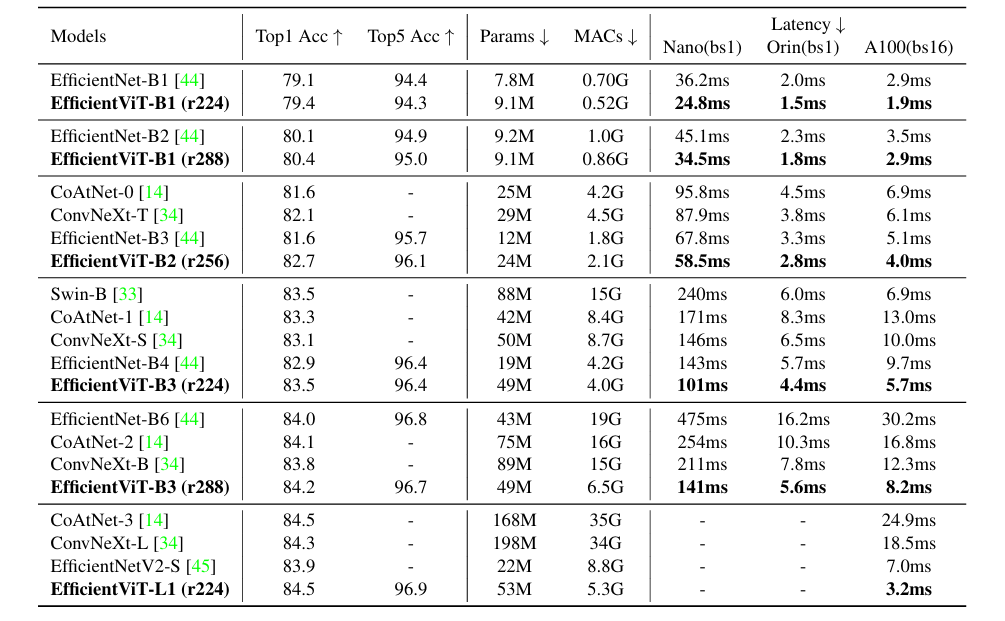
EfficientViT的backbone图像分类性能。
总结
这项工作中研究了用于高分辨率密集预测的高效架构设计。引入了一个轻量级多尺度注意力模块,该模块同时实现了全局感受野和轻量化、硬件高效的多尺度学习,从而在不同硬件设备上提供显著的速度提升,而不损失性能,相较于当前最先进的高分辨率密集预测模型。对于未来的工作,将探索将Efficient ViT应用于其他视觉任务,并进一步扩展Efficient ViT模型。