0-Self-Prompting Large Vision Models for Few-Shot Medical Image Segmentation
用于少量医学图像分割的自提示大型视觉模型

arXiv:2308.07624v1 [cs.CV] 15 Aug 2023
背景
现有方法依赖于调整策略,这需要大量数据或针对特定任务量身定制的事先提示,这使得当只有有限数量的数据样本可用时具有挑战性。本文提出了一种关于医疗视觉应用中自我提示的新方法。利用 SAM 的嵌入空间通过一个简单而有效的线性像素分类器进行自我提示。通过保留大型模型的编码能力、来自其解码器的上下文信息,并利用其交互式提示性,最终在多个数据集上取得了有竞争力的结果(与使用少量图像单独调整掩码解码器相比,提高了 15% 以上)。
小样本学习是通过从少量样本中学习,将模型推广到一个新的类别中。但这样的方法很难学习新类别的上下文信息,因为上下文信息可能是复杂和多方面的,并且很容易受到噪声的影响。
实验方法
设计一个即插即用的自我提示单元,只需少量标记数据(GT),即可为 SAM 提供分割目标的位置和大小信息,如图所示,粉红色块是原SAM。
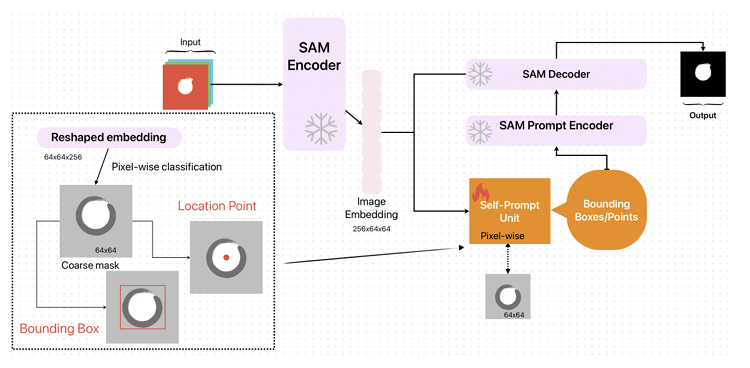
❄️标志表示在训练期间冻结了模块。自提示单元(“🔥”标志)使用 SAM 编码器中的图像嵌入和调整大小的 GT 标签进行训练。该单元预测一个粗略掩码,用于获取提示 SAM 的边界框和位置点。
自提示单元
要了解目标的位置和大小信息,一种直观的方法是获取粗略掩码作为参考。通过 SAM 编码器,输入图像被编码为矢量 $z_n ∈ R^{256× 64× 64}$。为了将蒙版与编码的图像嵌入对齐,将其下采样到 64×64,然后执行逻辑回归,将每个像素分类为背景或掩码以获得粗略掩码。此外,使用逻辑回归而不是神经网络将最大限度地减少推理速度的影响。最后从预测的低分辨率掩码中,可以使用形态学和图像处理技术获得位置点和边界框。
位置点
距离变换是一种图像处理技术,用于计算图像中每个像素到其最近边界的距离。
距离变换后,每个像素的值将替换为其到最近边界的欧几里得距离。可以通过找到距离最大的像素来获得离边界最远的点。
边界框
边界框是使用线性像素分类器生成的预测掩码的最小和最大 X、Y 坐标生成的,并由 0-20 像素的扰动添加。由于线性层的简单性,原始输出的质量不高。遮罩中出现噪音和孔洞。为了克服这个问题,在线性分类器的输出上添加了一些简单的形态过程,即侵蚀和膨胀。优化后的掩码用于生成提示。
训练目标
首先将图像馈送到图像编码器,得到图像嵌入 $z_q ∈ R^{256×64×64}$,然后重塑为 $z_q ∈ R^{64×64×256}$,对应形状为 $t_q ∈ R^{64×64} $的掩码。按照逻辑回归的损失函数为:
$$
L=\frac{1}{k}\sum^k_q\sum_{1≤m,n≤64}-(t^q_{m,n}log\hat t^q_{m,n}+(1-t^q_{m,n}log(1-\hat t^q_{m,n})))
$$
其中,$t^q_{m,n}$ 是子集 $D_k$ 中第 q 个掩码的像素 (m,n) 值,$\hat t^q_{m,n}= 1_{σ(w^Tz^q_{m,n}+b)}>0.5$,其中$z^q_{m,n},w,b ∈ R256$,σ 是 Sigmoid 函数
实验结果
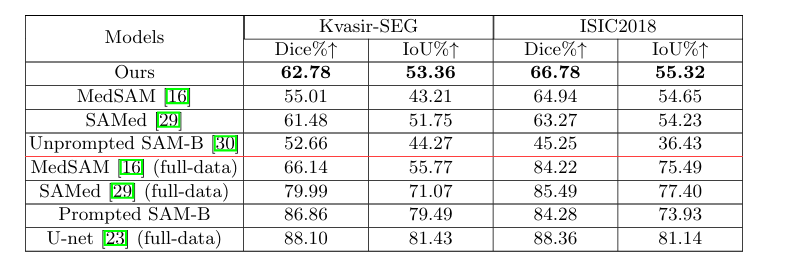
同时使用边界框和点与少量设置中的其他微调方法的比较。
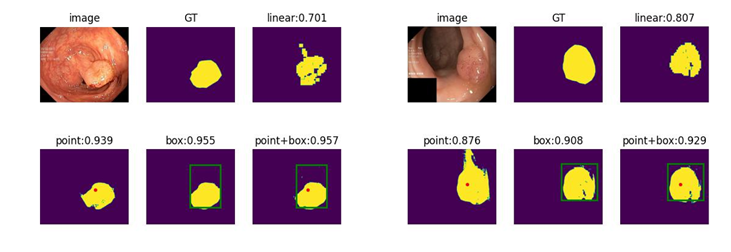
在 Kvasir-SEG 数据集上使用不同方法的一些示例。图中的黄色物体表示分割的息肉。这里的 “Linear” 是线性像素分类器的粗略掩码。这里的分数是 Dice 分数。
总结
本文的研究证明了利用大规模视觉基础模型的自我提示进行医学图像分割的潜力和可行性。提出了一个简单而有效的想法,使用一些图像来训练线性像素分类器来生成 SAM 的提示。由于 SAM 的可提示功能,本文的方法可以比传统的小样本学习模型更加用户友好,并且需要的数据比那些 SAM 微调模型少得多,整个过程需要的计算资源和时间很少,因此所得输出也可以看作是原始掩码,可以作为医疗专业人员更精确地生成提示和数据标记的工具。未来的研究可以更加强调从 SAM 的输出中获得更准确的提示。还可以探索将自我提示与其他微调方法相结合。