0-Sam2Rad: A Segmentation Model for Medical Images with Learnable Prompts
Sam2Rad:具有可学习提示的医学图像分割模型

arXiv:2409.06821v1 [cs.CV] 10 Sep 2024
加拿大麦吉尔大学计算机科学学院
背景
SAM 和其系列医学图像分割模型无法分割超声图像(US)中的分割目标,这可能是由于在US看到的成像伪影的独特性质,例如当相邻散射之间的距离小于细胞分辨率时发生的散斑干涉图案。因此作者引入了一种带有轻量级交叉注意力模块的提示预测器网络 (PPN),以增强现有的提示编码器,直接从图像编码器提取的特征中预测提示嵌入。PPN 为感兴趣区域输出边界框和掩码提示以及256维嵌入。还允许可选的手动提示作为掩码解码器的输入(同时也支持自动提示)。PPN 和掩码解码器可以使用参数高效微调 (PEFT) 方法进行端到端训练。通过冻结 SAM 中的所有参数并实现与微调掩码解码器证明了提示预测器网络的有效性。
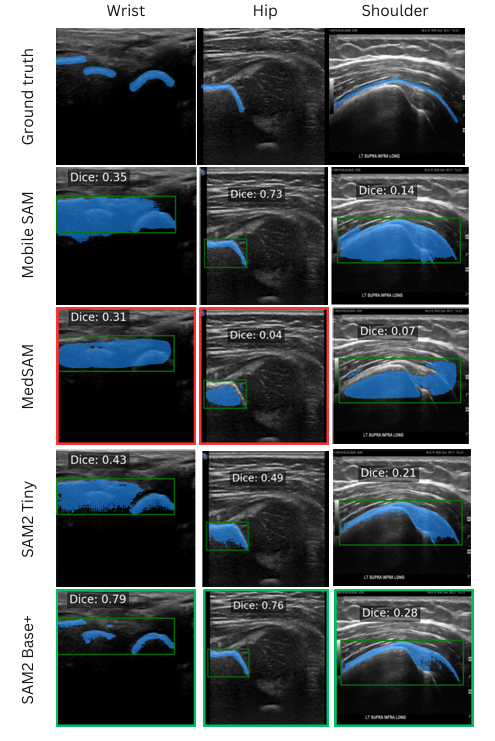
SAM系列模型在分割US图像中的效果。
实验方法
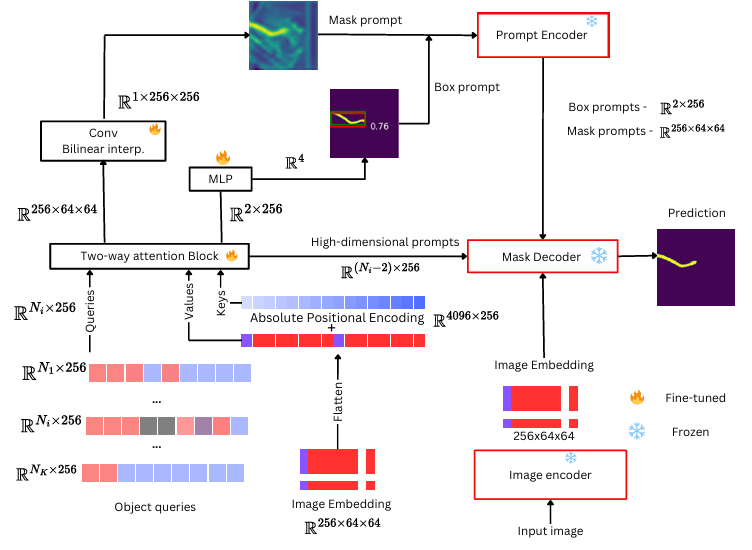
Sam2Rad 架构。一个轻量级的双向注意力模块来预测查询对象的提示。每个对象 有256个可学习提示。这些类提示以从预训练的 SAM 图像编码器获得的特征为条件。在推理过程中,可以移除提示编码器以自主运行模型,也可以将其与提示预测器网络结合使用,以实现人机交互。
图像编码器
图像编码器从输入图像中提取特征。它基于ViT架构,并使用掩码自动编码器 (MAE)进行预训练。对于大小为 3×1024×1024 的输入图像,图像编码器输出大小为 256×64×64的嵌入。
图像解码器
掩码解码器将图像嵌入和提示嵌入转换为最终掩码。
提示编码器
提示编码器处理稀疏提示(点和边界框)和密集提示。点被编码为 256 维嵌入,结合了位置嵌入和学习嵌入。边界框的编码方式类似,左上角使用位置编码,右下角使用学习的嵌入。掩码 (256× 256) 使用下采样卷积块转换为 256×64×64 嵌入。
为了将学习到的提示与 SAM 训练的手动提示保持一致,预测器网络输出边界框坐标、掩码提示和 N-256 维嵌入。
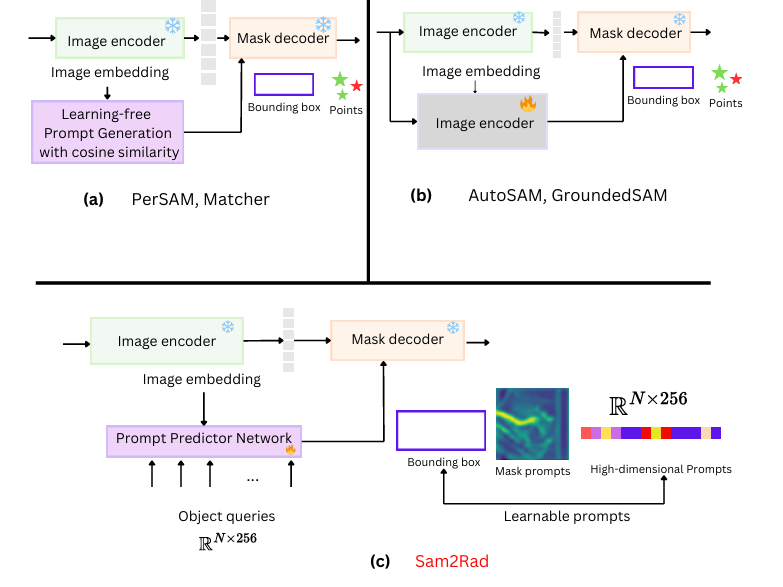
提示预测器网络与其他网络之间的比较。PerSAM和 Matcher使用免学习余弦相似度,通过比较参考图像和测试图像
(a) 之间的图像块来预测框和点坐标。给定图像特征,提示预测器网络预测查询对象的提示。预测器网络输出目标区域的边界框坐标、中间掩码提示和 N 个高维可学习嵌入 (R-N×256)。然后,所有预测的提示(可学习的提示)都被馈送到 SAM 的掩码解码器以生成掩码。提示预测器网络可以通过提供可学习的类查询 (c) 来处理多个类。相比之下,仅预测边界框或中间掩码,而 GroundedSAM 和 AutoSAM 使用独立的图像编码器 (b) 预测提示。
提示预测变量网络(PPN)
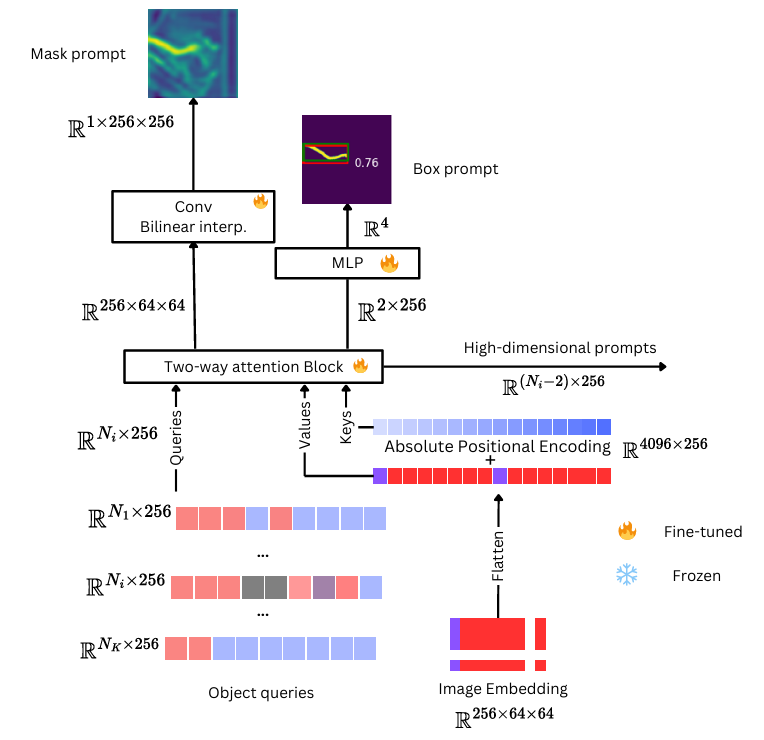
提示预测器网络架构。给定图像特征,提示预测器网络预测查询对象的提示。预测器网络输出目标对象的边界框坐标、中间掩码提示和 N-256 维可学习嵌入 。所有预测的(可学习的)提示都被馈送到 SAM 的掩码解码器以生成掩码。提示预测器网络可以通过提供不同的类查询来处理多个类。–学习非线性函数来预测中目标区域的位置,而不是使用余弦相似性来解决US图像中的特性。
实验结果
可视化。
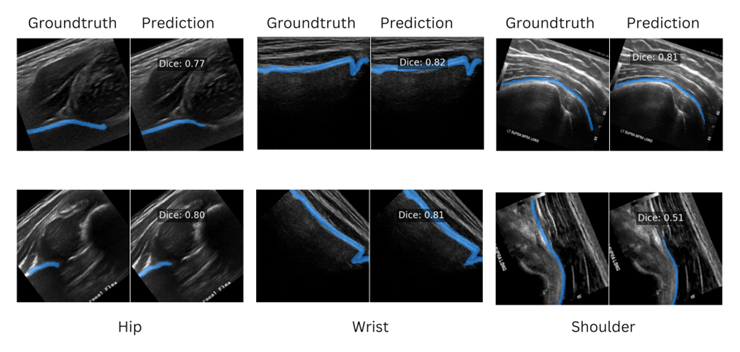
在三个数据集上的结果。
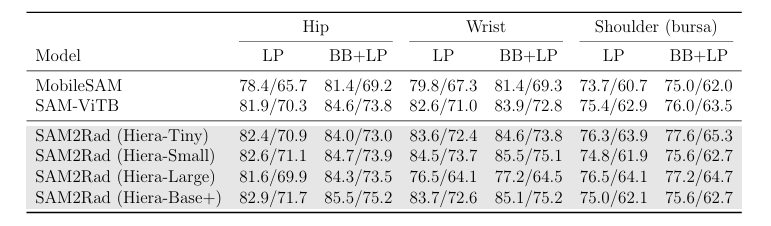
LP-学习提示。BB-边框提示。
总结
本文提出了 Sam2Rad,可显着提高 SAM/SAM2 及其变体在超声图像分割方面的性能。通过消除对手动提示的需求和提高各种数据集的分割准确性,解决了可提示模型的关键限制。Sam2Rad 在零发泛化方面优于所有 SAM 和 SAM2 变体,特别是对于超声病例。Sam2Rad 可以使用低至 10 张标记图像进行训练。通过利用 SAM 的图像编码器功能,网络与 SAM 的架构无缝集成,以生成高质量的提示。模型提供三种模式:自主、半自主人机协同和完全手动。与 SAM 架构的无缝集成以及与任何 SAM 变体的兼容性使 Sam2Rad 成为医学成像中自动分割的多功能且强大的工具。