0-SAM-SP: Self-Prompting Makes SAM Great Again
Makes SAM Great Again

arXiv:2408.12364v1 [cs.CV] 22 Aug 2024
浙江大学
背景
视觉基础模型 (VFM)SAM在跨不同自然图像数据集的零镜头分割取得了成功,但 SAM 在医学图像上的性能会明显下降。目前解决这个问题的努力涉及微调策略,增强原版 SAM 通用型。然而专家级提示限制了模型的实用性。本文引入了一种新的基于自我提示的微调方法,称为 SAM-SP。利用模型本身上一次迭代的输出作为提示来指导模型的后续迭代。这个自我提示模块致力于学习如何自主生成有用的提示,并在评估阶段消除对专家提示的依赖,从而显着拓宽了 SAM 的适用性。此外还集成了一个自蒸馏模块,以进一步改进自提示过程。跨各种特定领域数据集的广泛实验验证了所提出的 SAM-SP 的有效性。
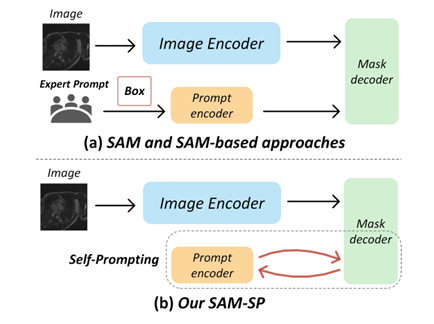
(a) SAM 和基于 SAM 的方法在推理过程中都依赖于专家提示。
(b) SAM-SP 构建了一个自提示模块,在推理过程中不依赖专家提示。
实验方法
SAM-SP 是一个基于标准SAM 构建的端到端框架,包含三个附加模块:基于 LoRA 的微调、Self-Prompt 模块和 Self-Distillation 模块。
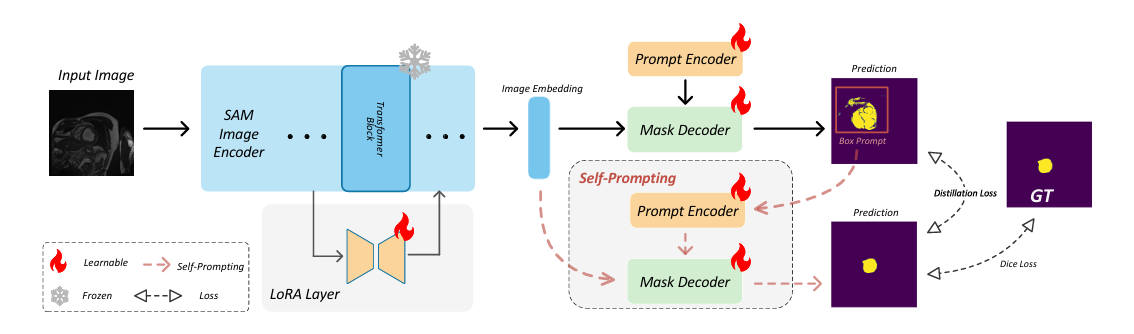
SAM-SP的整体训练架构,它继承自 SAM 并包含三个额外的模块:基于 LoRA 的微调、Self-Prompting 模块和 Self-Distillation 模块。SAM-SP显着增强了 SAM 在特定领域的分割能力,并减轻了推理过程中对专家提示的依赖。这里的两个提示编码器与参数共享,与两个掩码解码器相同。
基于 LoRA 的微调
医学图像和自然图像之间有明显的差距,为了缩小这些差距并提高 SAM 的泛化能力,已经有诸多工作展开来解决这个问题。图像编码器在 SAM 中占据了大多数(超过 95%)的计算开销,本文作者没有对 SAM 的所有参数进行微调 ,而是冻结了图像编码器,只微调提示编码器和掩码解码器以最小化计算成本。为了进一步提高图像编码器的图像嵌入质量,采用了基于低秩的微调策略 (LoRA),该策略近似于图像编码器中参数的低秩更新。LoRA 使 SAM 能够有效地适应下游任务,同时与完全微调相比保持训练效率。此外,LoRA 在部署时将可训练矩阵与冻结权重合并,不会引入额外的推理延迟。
对于 SAM 图像编码器中预训练的权重矩阵 $W ∈ R^{d\times k}$,假设其更新如下:
$\hat W=W+∆W=W+BA$,其中 $\hat W∈R^{d× k}$表示更新的权重矩阵,而低秩分解 $∆W = BA$,$A ∈ R^{r×d}$,$B ∈ R^{d×r}$ 对这个权重更新进行建模。
在实现中将 4 设置为低秩分解的默认秩。
自提示模块
引入了一个即插即用的 Self-Prompting 模块来减轻对专家提示的需求。以前的工作通常在训练阶段根据专家注释模拟用户提示,这可能会导致模型过度依赖提供的提示。为了减少这种依赖并,在训练和评估期间不使用任何用户提示。SAM 中的提示编码器可以在没有任何提示输入的情况下工作,并且会在训练期间更新默认嵌入。
给定图像x,首先获取图像嵌入E(x),通过低秩SAM图像编码器,没有给提示的原预测:
$\hat y_0 = M(E(x),P(null))$
为了进一步减轻对专家提示的需求,模型会自行生成提示,使用第一次迭代中的原版预测$\hat y_0 $来生成提示来指导后续迭代。并使用预测掩码$\hat y_0 $的最大和最小坐标生成框提示,将这个自提示过程表示为 SP( )。然后将模型自身产生的提示 SP($\hat y_0 $) 放入提示编码器 P( )中,将生成的自提示嵌入丁 P(SP($\hat y_0 $)) 与图像嵌入 E(x) 结合送入掩码解码器 M( ), $\hat y_1 $表示自我提示过程的预测结果。表示为:
$\hat y_1 = M(E(x),P(SP(\hat y_0 )) )$
获得的图像嵌入在自提示过程中被重复使用,而不会增加额外的计算成本。并且引入的自提示模块没有引入任何可学习的参数,保持了 SAM-SP 的效率。
自蒸馏模块
受知识蒸馏的启发,利用基于分割的自我蒸馏模块来进一步加强自我提示过程的训练。如前所述,最终的预测掩码$\hat y_1 $,原预测 $\hat y_0 $。采用最终预测 $\hat y_1 $ 作为教师模型,以学生指导前一个预测 $\hat y_0 $。自蒸馏过程表述为:
$ L_{SD} = KL( \hat y_0, \hat y_1)$,其中 $L_{SD} $表示知识蒸馏损失。自蒸馏模块也没有引入任何可学习的参数,并且在评估过程中被弃用,进一步保持了 SAM-SP 的效率。
训练和评估
损失函数:
$$
L= Dice (\hat y_1,y)+\alpha L_{SD}
$$
其中 y 表示真实值,α 用作加权因子。 SAM-SP 在训练和推理期间不使用任何用户提供的提示。
实验结果
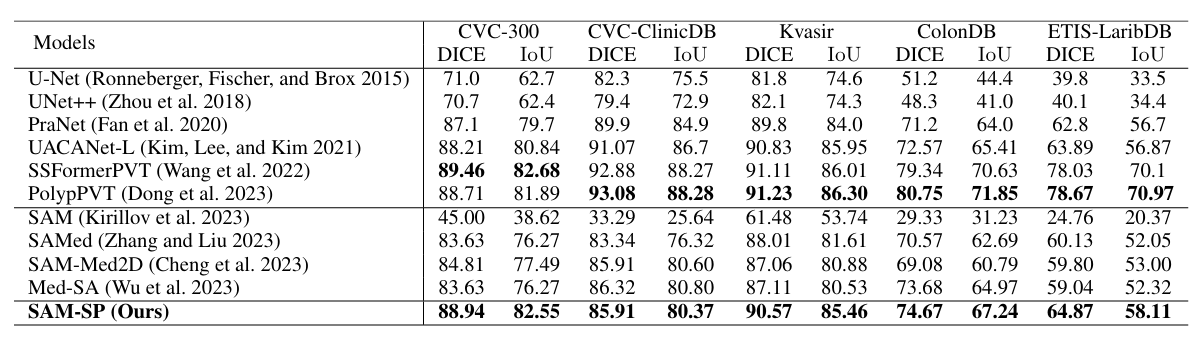
息肉分割定量分析。
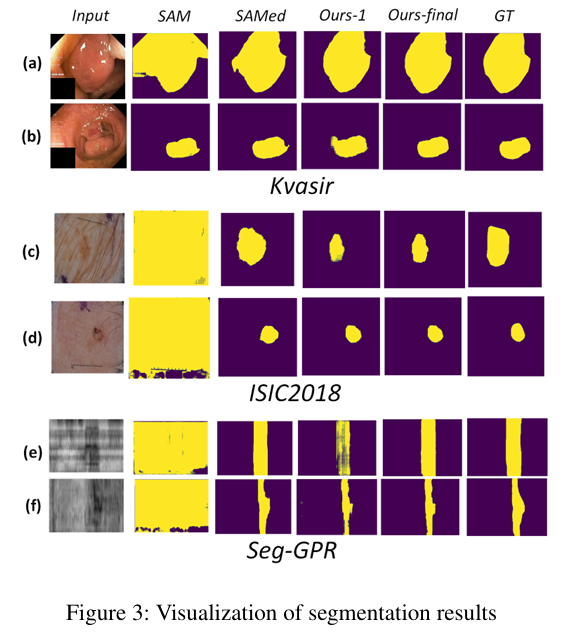
可视化分割结果。
总结
本文引入了一种基于自我提示的微调方法 SAM-SP,为扩展标准SAM模型的功能而制。SAM-SP 利用其自己在上一个迭代中的输出作为提示来指导模型的后续迭代。这个自我提示模块学习如何自主生成有效的提示,并减轻评估过程中对专家提示的依赖,大大拓宽了 SAM 的适用性,另外自蒸馏模增强自提示过程。广泛实验数据集验证了所提出的 SAM-SP 的有效性,表现出令人满意的性能。