0-SAMedOCT: Adapting Segment Anything Model (SAM) for Retinal OCT
SAMedOCT: Adapting Segment Anything Model (SAM) for Retinal OCT

arXiv:2308.09331v2 [eess.IV] 31 Aug 2023
背景
SAM 已经在各个领域进行了广泛的评估,但它对视网膜 OCT (光学相干断层扫描)的适应性仍有待探索,因此本文作者改进了SAM,让其改编后的 SAM 成为在视网膜 OCT 扫描中作为强大分割模型,尽管在某些情况下仍然落后于既定方法,这些发现强调了 SAM 的适应性和稳健性,展示了其作为视网膜 OCT 图像分析中有价值的工具的实用性,并为该领域的进一步发展提供方法。(论文内并没有提供SAMedOCT的pipline,详见SAMed)
实验方法
LoRA(Low-Rank Adaptation)
大规模语言模型(LLMs)的微调(fine-tuning)成为适应特定任务的关键步骤。然而,微调完整模型参数(full fine-tuning)成本高昂,需要大量存储和计算资源。LoRA旨在通过低秩矩阵分解的方法,减少模型参数更新的规模,从而降低计算和存储成本,同时保持微调后的模型性能。(减少可训练参数、可插拔性、保持推理效率)
点提示的零样本 SAM
计算了手动参考分割掩码的每个连接分量的质心。为了模拟每个流体类别的 n 次点击,使用了 n 个最大连通分量的质心。如果连通分量的总数小于 n,则选择随机连通分量,并从以所选分量质心为中心的 2D 高斯分布生成随机坐标。如果生成的点落在蒙版边界之外,则重复随机选择过程。
SAM 解码器微调
SAM 模型使用与 SAMedOCT 模型相同的设置进行训练,但没有合并 LoRA 适配器。模型的解码器组件被细化,而编码器权重在训练过程中保持冻结。
实验结果
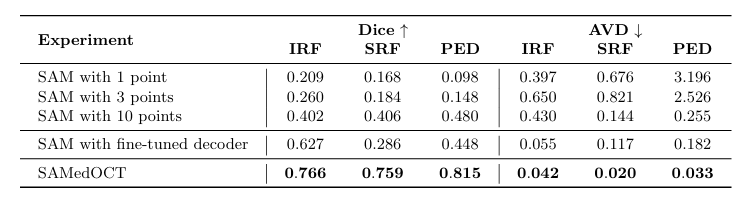
SAM的零样本性能总体上比对数据集进行部分微调的方法差。
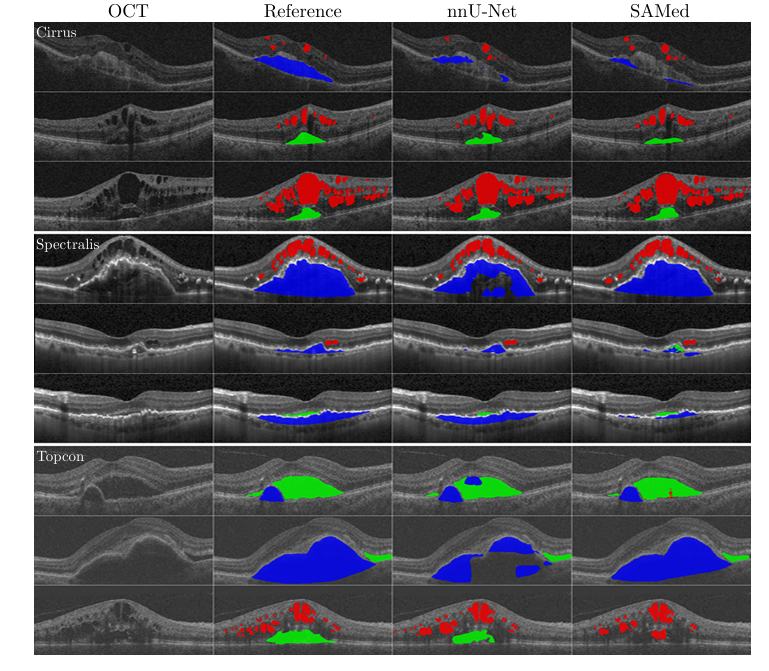
可视化结果。
结论
本文评估了 SAM 在视网膜 OCT 中生物标志物分割的适用性。结果表明,尽管实现了有竞争力的性能,但与专为医学图像分析设计的网络相比,适应性 SAM 的性能略逊一筹。尽管如此,考虑到 SAM 编码器仅在自然图像上进行训练,这仍然很了不起。编码器在 OCT 图像上的进一步自我监督微调有望进一步提高 SAM性能,可能超过使用 nnU-net 实现的性能。最后,SAM 的半交互式特性使其成为临床环境中以及半自动注释程序中特别有吸引力的方法,因为它允许调整复杂病理形态学表现中的分割并考虑用户主观性。