0-DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation
DS - TransUNet:用于医学图像分割的双 Swin Transformer U - Net

JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, JUNE 2021
arXiv:2106.06716v1 [cs.CV] 12 Jun 2021
背景
医学图像分割是临床应用关键环节,如息肉、病变、细胞分割等,对辅助诊断和病理研究意义重大。深度学习虽推动其发展,但现有基于卷积神经网络(CNNs)的方法因卷积固有局限,难以构建长距离依赖和全局上下文连接,限制性能提升。
Transformer 在自然语言处理中成果丰硕,其自注意力机制可有效构建长距离上下文信息,在计算机视觉任务渐受关注。Vision Transformer(ViT)及分层结构的 Swin Transformer 在图像识别、检测和分割任务有出色表现,但在医学图像分割领域关注度不足。部分研究将 Transformer 用于医学图像分割编码器,在解码器应用及多尺度特征利用方面仍有挖掘空间。
因此作者提出双 Swin Transformer U - Net(DS - TransUNet)医学图像分割框架,将 Swin Transformer 优势融入 U - Net 架构的编码器和解码器,提升医学图像语义分割质量,有效利用多尺度特征表示,建立特征间全局依赖,克服 CNN 固有局限。
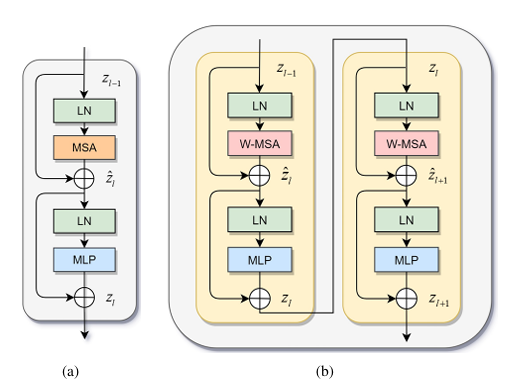
标准 Transformer 块的架构(1);(b) Swin Transformer 块的架构(2)和(3) 。
实验方法
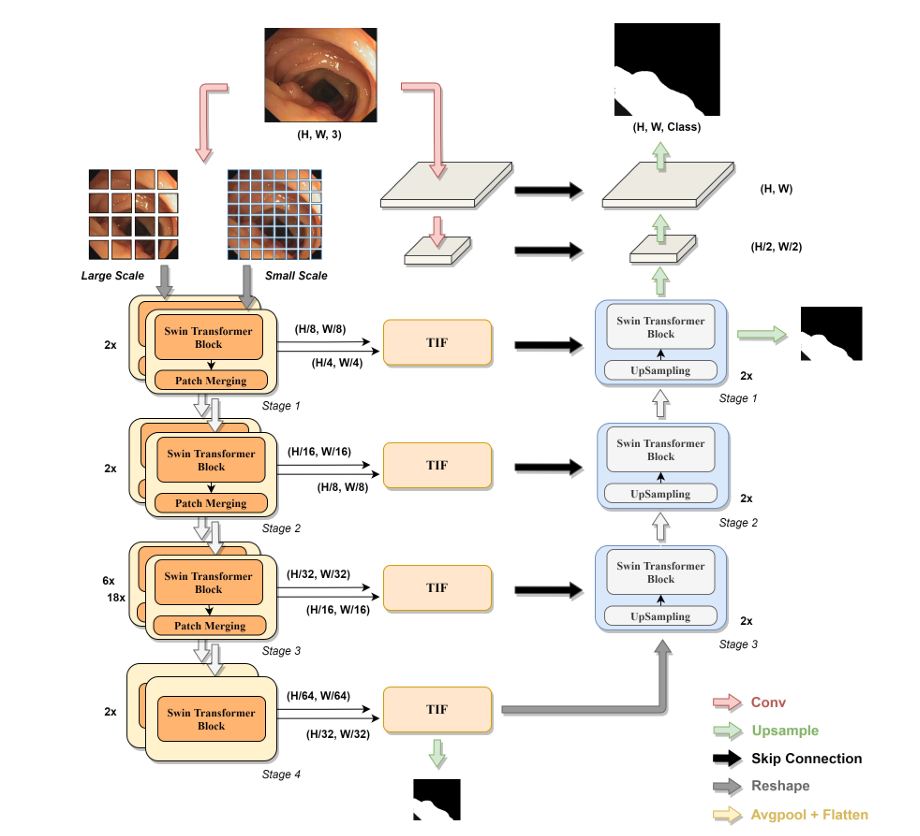
给定一个输入的医学图像,首先将其分成两个尺度的非重叠补丁,分别将它们馈送到编码器的两个分支中,然后通过 Transformer Inter-active Fusion (TIF) 模块融合不同尺度的输出特征表示。最后,在基于 Swin Transformer 模块的上采样过程后,融合特征恢复到与输入图像相同的分辨率,从而获得最终的掩码预测。
Swin Transformer 块
标准 Transformer 编码器含多头自注意力(MSA)和多层感知器(MLP)模块,计算复杂度高。Swin Transformer 采用窗口多头自注意力(W - MSA)和移位窗口多头自注意力(SW - MSA)解决此问题,W - MSA 在局部窗口计算自注意力,SW - MSA 通过循环移位引入跨窗口交互,计算相似性时考虑相对位置偏差,提升计算效率。
编码器
模型基于 U - Net 架构,编码器用 Swin Transformer 提取特征。输入医学图像切分为重叠块并投影为 “令牌”,输入 Swin Transformer 的四个阶段,各阶段含多个 Swin Transformer 块(含 W - MSA 和 SW - MSA)。随网络加深,令牌数减少,前三个阶段经 patch merging 层降低特征分辨率、增加维度,实现层次化特征表示。
解码器
解码器含三个阶段,与传统 U - Net 及变体不同,各阶段有上采样、跳跃连接和 Swin Transformer 块。编码器第 4 阶段输出为解码器初始输入,经上采样与跳跃连接特征图拼接后输入 Swin Transformer 块,充分利用编码器特征并构建长距离依赖和全局上下文交互,提升解码性能。最后下采样输入图像获取低级别特征辅助最终掩码预测。
多尺度特征表示
考虑到自注意力机制对补丁内像素级结构特征的忽视及 ViT 在细粒度补丁上的优势,采用多尺度 Swin Transformer 提取特征。用不同尺度(如和)分支互补提取粗、细粒度特征,增强模型分割性能与鲁棒性。
Transformer 交互融合模块(TIF)
为融合双分支编码器输出的多尺度特征,提出 TIF 模块。其基于标准 Transformer 块的多头自注意力机制,实现多尺度特征高效交互。将不同分支特征重塑、拼接为令牌序列计算自注意力,建立不同尺度特征全局依赖,使细粒度特征获取粗粒度信息,提升分割性能。
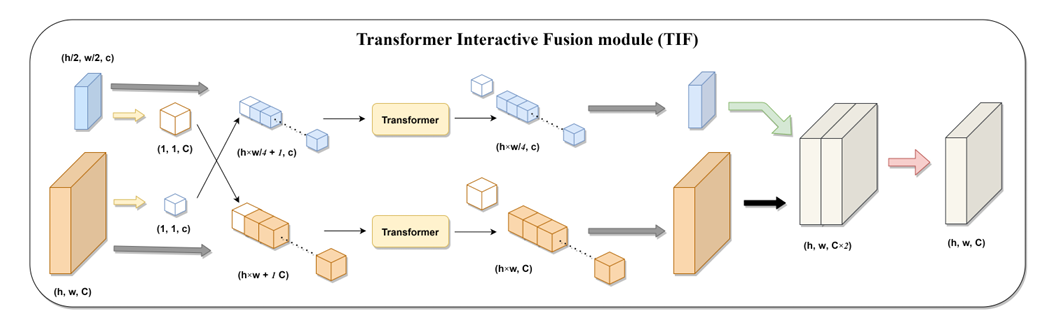
Transformer 交互式融合模块 (TIF) 的示意图,该模块在多尺度特征融合过程中作为 DS-TransUNet 的核心组件。
实验结果
在息肉分割、ISIC 2018 皮肤病变分析、GLAS 腺体分割和 2018 数据科学碗细胞核检测四个医学图像分割任务中使用多个公开数据集,如息肉分割的 Kvasir、CVC - ColonDB 等五个数据集,各数据集按不同方式划分训练集、验证集和测试集,并统一图像分辨率。
所有实验采用多尺度训练策略而非数据增强,损失函数为加权 IoU 损失和二元交叉熵损失,并通过深度监督辅助模型训练,最终损失函数为不同阶段输出损失加权和。用 SGD 优化器训练模型,设置动量、权重衰减和学习率,训练 100 个 epoch 并采用早期停止和余弦退火策略。模型基于 PyTorch 框架,在 NVIDIA RTX 3090 GPU 上训练,有基础版本(DS - TransUNet - B)和大版本(DS - TransUNet - L),分别使用 Swin - Base 和 Swin - Large 为主要尺度分支编码器,均以 Swin - Tiny 为互补尺度分支,且使用预训练权重。
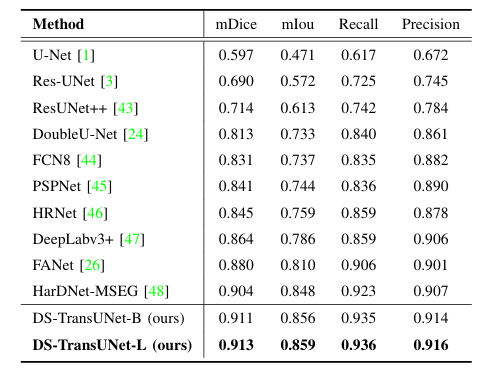
在不同数据集划分下,DS - TransUNet 均取得 SOTA 性能。在 Kvasir 数据集上,DS - TransUNet - L 在 mDice、mIoU、召回率和精度指标上优于此前 SOTA 方法 HarDNet - MSEG;在 CVC - ClinicDB 数据集上,DS - TransUNet - L 在多数指标达 SOTA,召回率提升显著;在综合多个数据集的实验中,DS - TransUNet 在所有数据集表现优异,尤其在未见过的数据集上优势明显,平均 mDice 得分相比 TransFuse 提升约 1.9%,能精准分割模糊息肉及大面积息肉。

DS-TransUNet 息肉分割任务与其他模型的定性结果。模型显示出更好的学习和泛化能力,这导致了更高质量的分割性能。
定性结果。
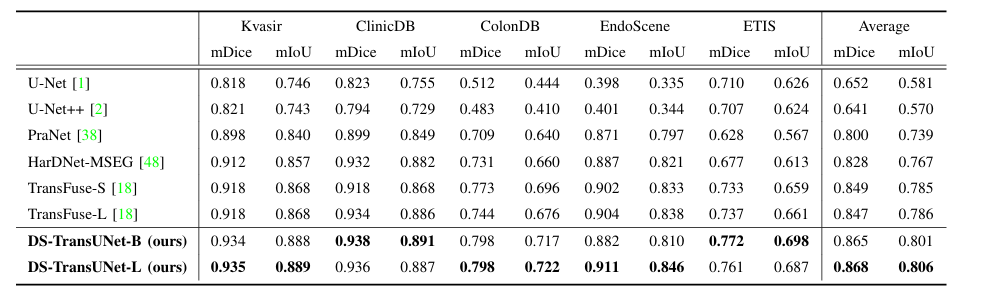
五个息肉分割数据集的定量结果与以前的 SOTA 方法相比。对于每一列,最佳结果都以粗体突出显示
消融研究
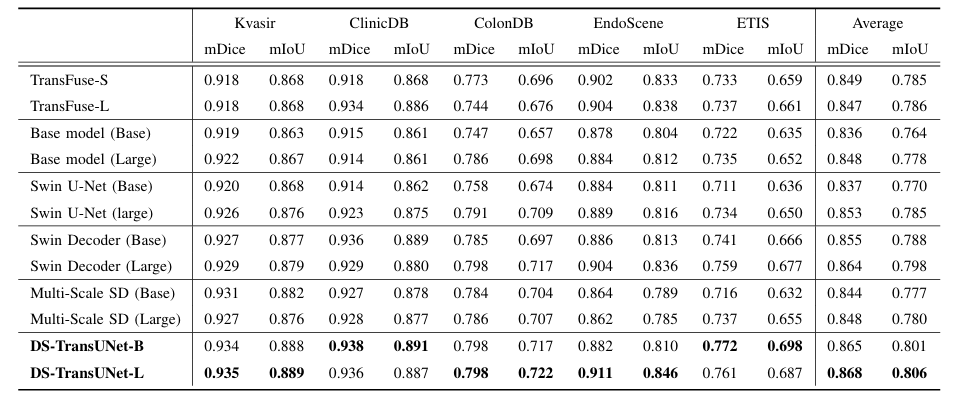
Swin Transformer 的影响:以 Base 模型探究 Swin Transformer 作为编码器的特征提取能力,虽总体性能略逊于 TransFuse,但在部分数据集(如 Kvasir 和 ColonDB)的 mDice 指标有提升,证明其作为编码器的有效性。
解码器中 Swin Transformer 块的影响:基于 Swin Transformer 编码器设计的 Swin U - Net 和 Swin Decoder 模型表明,U - 形编码器 - 解码器架构可提升分割性能,Swin Decoder 在平均 mDice 得分上比 TransFuse 提升 1.5%,能有效构建解码器中的长距离依赖和全局上下文连接5。
多尺度特征表示和 TIF 的影响:Multi - Scale SD 通过卷积融合多尺度特征未提升性能,因卷积难以有效融合多尺度特征且影响模型收敛。加入 TIF 模块的 DS - TransUNet 性能最佳,相比 Swin Decoder 在多个数据集的 mDice 和 mIoU 指标有提升,TIF 模块实现多尺度特征高效交互融合,提升分割效果。
总结
提出的 DS - TransUNet 框架基于分层 Swin Transformer,在编码器采用双分支提取多尺度特征,解码器创新加入 Swin Transformer 块,并通过 TIF 模块融合多尺度特征,有效构建长距离依赖。在四个医学图像分割任务中显著优于其他 SOTA 方法,尤其在息肉分割表现突出。未来将聚焦设计更轻量化 Transformer 模型及学习视觉 Transformer 补丁划分产生的像素级内在结构特征。