0-Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Hiera:一种去除繁杂结构的分层视觉 Transformer

Facebook Meat 2023
背景
Vision Transformers(ViTs)在计算机视觉领域广泛应用,但存在参数利用效率低的问题。分层设计的 Vision Transformers 虽提高了参数效率,但为追求 ImageNet - 1K 上的监督分类性能,添加了许多复杂组件,导致模型变慢。掩码自编码器(MAE)等自监督学习方法可有效训练 Vision Transformers,但将其应用于分层模型时存在挑战,如破坏 2D 网格布局、训练效率低等。
所以作者提出一种简单高效的多尺度视觉 Transformer——Hiera,通过去除分层 Transformer 中的非必要组件,结合 MAE 预训练,在不损失准确性的前提下提高模型速度和效率。
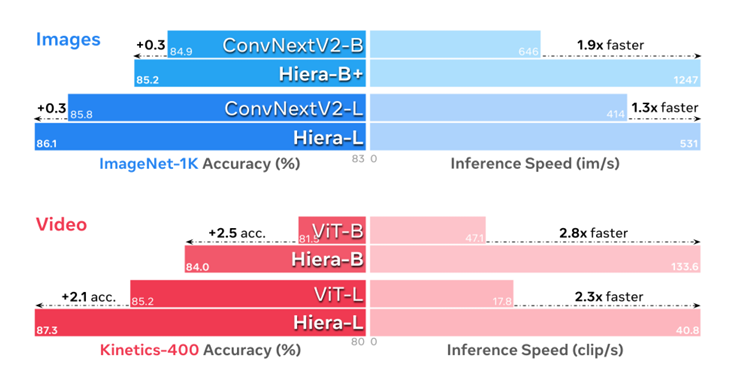
Hiera 从分层转换器中省去了昂贵的专业操作(例如 convs),以创建一个简单、高效且准确的模型,该模型可在许多图像和视频任务中快速完成。
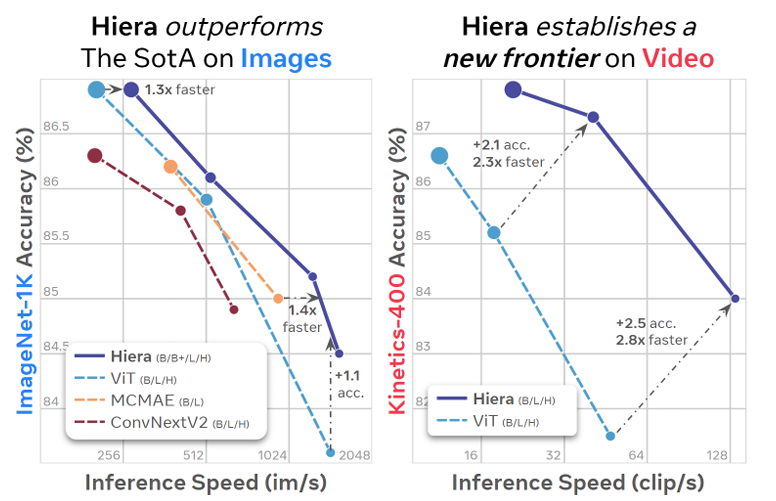
Hiera 与使用类似 MAE 的预训练的 SotA 模型的 B、L 和 H 变体进行了比较。在图像上,Hiera 甚至比最新的 SotA 更快、更准确,与每个规模的最佳模型相比,速度提高了 30-40%。在视频方面,Hiera 代表了一种新的性能等级,显著提高了准确性,同时比流行的 ViT 型号快 2× 以上。标记大小与 FLOP 计数成正比。
实验方法
模型设计
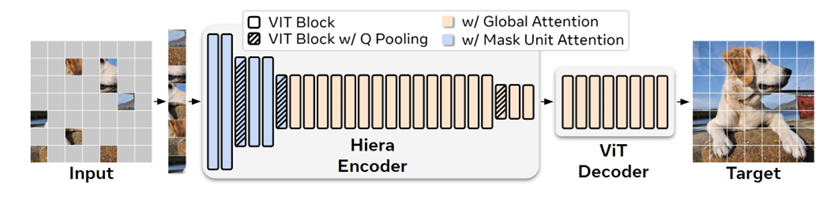
像 Swin 或 MViT 这样的现代分层转换器比普通的 ViT更具有参数效率,但由于通过视觉特定模块(如移位窗口或 convs)添加空间偏差的开销,最终速度变慢。相比之下,Hiera 设计得尽可能简单。为了增加空间偏差,选择通过像掩码自编码器(这里有图示)这样的强 pretext 任务来教给模型。Hiera 完全由标准 ViT 块组成。为了提高效率,在前两个阶段使用 “掩码单元” 内的局部注意力,其余阶段使用全局注意力。在每个阶段转换中,Q 和 skip connection 的特征被线性层和空间维度加倍,由 2 × 2 maxpool 共用。
去除非必要组件
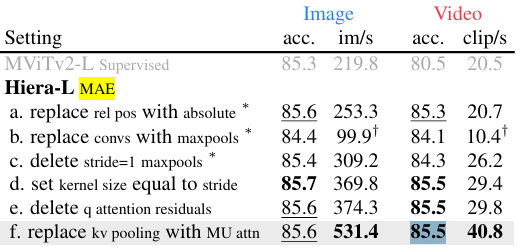
MViTv2 采用了多种架构调整,以便在监督训练中表现良好。通过在逐步删除它们,发现这些花里胡哨的东西在使用强借口任务 (MAE) 进行训练时是不必要的。在这个过程中,创建了一个非常简单的模型(图 #Hiera),该模型既准确又明显更快。
相对位置嵌入:用绝对位置嵌入替代 MViTv2 中的相对位置嵌入,简化模型且提高速度,同时不影响 MAE 预训练效果。
卷积层:尝试用最大池化层替代卷积层,发现虽会降低精度,但删除额外的 stride = 1 最大池化层后,能接近原有精度并提升速度。进一步将最大池化层的核大小设置为与步长相等,避免了使用复杂的 “分离和填充” 技巧,再次提高了速度和精度。
注意力残差连接:去除 MViTv2 中注意力层的残差连接,简化模型结构,同时不影响模型学习能力。
池化注意力:将前两个阶段的 KV 池化注意力替换为掩码单元注意力(Mask Unit Attention),在不增加计算开销的情况下,提高了模型的吞吐量,且能适应不同分辨率的掩码单元。

Mask Unit Attention。MViTv2 使用池化注意力 (a),它使用池化版本的 K 和 V 执行全局注意力。对于较大的输入(例如,对于视频),这可能会变得昂贵,因此选择将其替换为 “Mask Unit Attention” (b),它在掩模单元内执行局部注意。这没有开销,因为已经将令牌分组到要屏蔽的单元中。不必像 Swin 那样担心转移,因为在第 3 阶段和第 4 阶段使用全局注意力(图 #Hiera)。

Mask Unit Attn vs. Window Attn (a) 在固定大小的窗口内执行局部注意力。这样做可能会与稀疏 MAE 预训练期间删除的标记重叠。相比之下,掩码单元注意力 (b) 在单个掩码单元内执行局部注意力,无论它们的大小如何。
Hiera 架构特点
Hiera 是一个纯粹的分层 ViT 模型,仅由标准 ViT 块组成。在前两个阶段使用掩码单元内的局部注意力,其余阶段使用全局注意力。在阶段转换时,通过线性层加倍 Q 和跳跃连接的特征,并使用 2×2 最大池化降低空间维度。
MAE 预训练设置调整
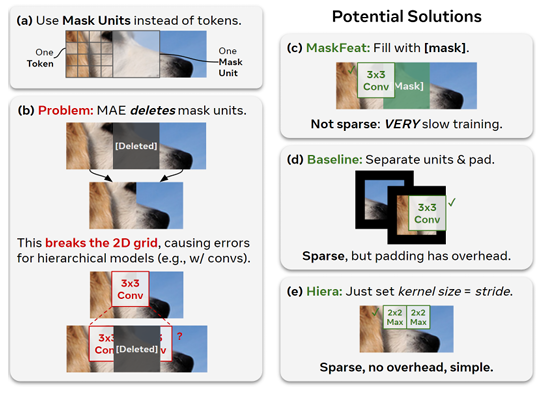
MAE 与多阶段模型不兼容,但可以应用一些简单的技巧来解决这个问题。虽然 MAE 掩盖了单个令牌,但多级transformer中的令牌开始时非常小(例如,4 × 4 像素),每个阶段的大小都会翻倍。
(a) 因此,直接屏蔽较粗糙的“掩码单元”(32×32 像素)而不是标记。
(b) 为了提高效率,MAE 是稀疏的,这意味着它会删除它所屏蔽的内容(像 convs 这样的空间模块的一个问题)。
(c) 保留掩码令牌可以解决这个问题,但放弃了 MAE 潜在的 4 − 10× 训练加速。
(d) 作为基线,引入了一个技巧,将掩码单元视为 convs 的单独实体,解决了这个问题,但需要不需要的填充。
(e) 在 Hiera 中,通过改变架构来完全回避问题,这样内核就不能在掩码单元之间重叠。
多尺度解码器:利用 Hiera 的分层结构,融合所有阶段的表示进行解码,在图像和视频任务中均带来显著性能提升。
掩码比例:图像和视频任务的最佳掩码比例不同,图像为 0.6,视频为 0.9,与之前研究结果相符且受掩码单元大小影响。
重建目标:像素和 HOG(Histogram of Oriented Gradients)重建目标均能使模型达到较好性能,视频任务中长时间训练后两者性能相似,图像任务中像素目标略优。
随机失活路径(Drop Path)率:与原 MAE 预训练设置不同,Hiera - L 模型在预训练中应用 Drop Path 可显著提高性能,表明其可防止模型过拟合 MAE 任务,尤其在视频任务中效果明显。
解码器深度:视频任务中使用比之前更深的解码器可带来显著收益,使视频解码器与图像解码器性能一致。
预训练计划:Hiera 在更长的预训练计划中受益,与之前研究趋势相同,且在训练效率上表现更优,如在 Kinetics - 400 数据集上,较短预训练时间即可超越之前的 SOTA 结果。
实验结果
视频任务结果

在 Kinetics - 400、 - 600、 - 700 数据集上,Hiera 模型在准确率、FLOPs(浮点运算次数)和参数数量等方面表现优异,大幅超越之前的 SOTA 方法,如 Hiera - L 在 Kinetics - 400 上比之前的 SOTA 提高了 2.1% 的准确率,同时使用更少的 FLOPs,速度提升 2.3 倍。
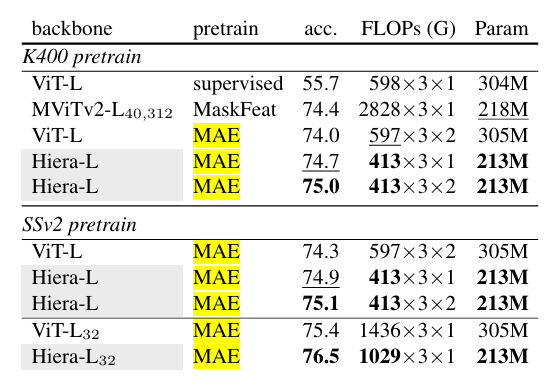
在 Something - Something - v2(SSv2)数据集上,Hiera - L 模型在不同预训练设置下均取得较好结果,与当前 SOTA 方法相比,准确率更高且计算效率更优。
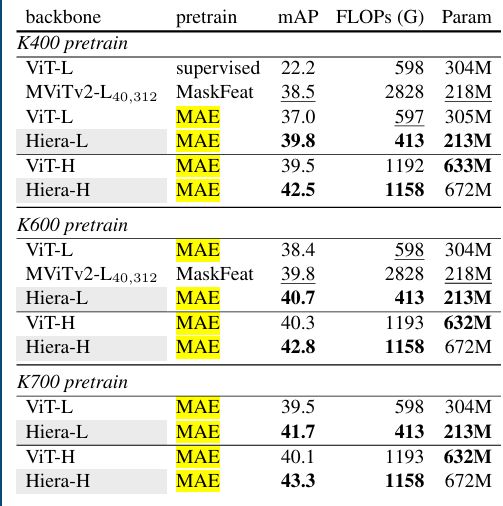
在 AVA v2.2 数据集上进行动作检测任务的迁移学习实验,Hiera 模型同样表现出色,超越之前的 SOTA 方法。
图像任务结果
ImageNet - 1K 性能
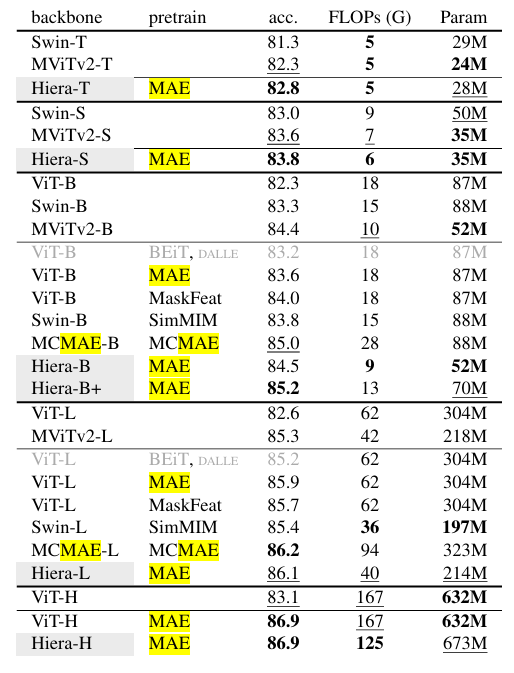
在 ImageNet - 1K 数据集上,Hiera 模型在不同规模下均表现出较强性能。与 MViTv2 相比,Hiera - B 在不使用复杂组件的情况下,准确率略高于 MViTv2 - B;Hiera - L 的准确率达到 86.1%,比 MViTv2 - L 高 0.8%,且比 ViT - L MAE 模型在准确率相当的情况下,参数减少 42%,FLOPs 降低 1.6 倍。
迁移学习实验
在 iNaturalists 和 Places 数据集上的分类任务:Hiera 模型在 iNaturalist 和 Places 数据集上进行微调时,始终优于 ViT MAE 模型,表明其在下游分类任务中的有效性和泛化能力。
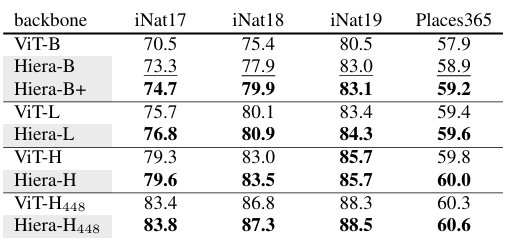
在 iNaturalists 和 Places 数据集上迁移学习。
在 COCO 数据集上的目标检测和实例分割任务:使用 Mask R - CNN 框架,Hiera 模型在 COCO 数据集上与 MViTv2 和 ViTDet 等方法相比,在准确率、推理时间和模型复杂度上取得了更好的平衡。例如,Hiera - L 在 APbox 上比 MViTv2 - L 高 1.8,推理时间减少 24%;与 ViTDet 相比,Hiera - B 在 APbox 上高 0.6,参数减少 34%,推理时间降低 15%。
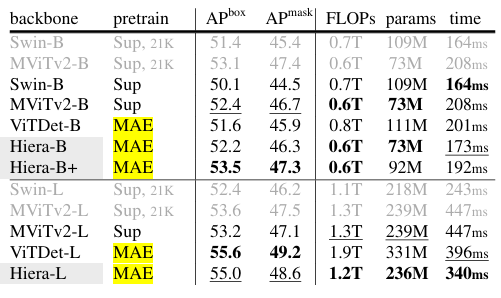
使用 Mask RCNN 进行 COCO 对象检测和分割。
总结
提出的 Hiera 模型通过去除分层视觉 Transformer 中的非必要组件,并结合 MAE 预训练学习空间偏差,在图像和视频识别任务中均取得了优异性能,超越了当前的 SOTA 方法。Hiera 模型的简单高效为未来视觉任务的研究提供了新的基础和方向,有望推动更多快速准确的模型开发。