0-Fundus2Angio: A Conditional GAN Architecture for Generating Fluorescein Angiography Images from Retinal Fundus Photography
Fundus2Angio: A Conditional GAN Architecture for Generating Fluorescein Angiography Images from Retinal Fundus Photography

Fundus2Angio:一种从视网膜眼底摄影生成荧光素血管造影图像的条件 GAN 结构
arXiv:2005.05267v2 [eess.IV] 29 Sep 2020
背景
荧光素血管造影 ( Fluorescein Angiography FA) 进行视网膜血管变性的临床诊断是一个耗时的过程,并且会对患者造成重大不利影响。血管造影需要插入染料,有可能对人体健康产生影像。目前,没有能够生成荧光素血管造影图像的非侵入性系统。然而,基于眼底摄影的视网膜眼底成像是一种非侵入性成像技术,可以在几秒钟内完成。为了消除对 FA 的需求,本文提出了一种条件生成对抗网络 (GAN) 来将眼底图像转换为 FA 图像。所提出的 GAN 由一种能够生成高质量 FA 图像的新型残差块组成。这些图像是鉴别诊断视网膜疾病的重要工具,无需向患者注入荧光血素。实验表明,所提出的架构实现了 30.3 的低 FID 分数,并且优于其他最先进的生成网络。此外,提出的模型获得了与真实血管造影无法区分的更好的定性结果。
实验方法
一些方法使用多尺度判别器进行风格迁移。只将判别器与处理精细特征的生成器连接起来,而完全忽略了粗略生成器的判别器。为了在最粗尺度上学习有用的特征,需要单独的多尺度判别器。作者提出的架构将其用于粗略和精细生成器。为了实现高质量的图像合成,还提出了一种具有多对判别器和生成器的金字塔网络,称为SinGAN。尽管它可以生成高质量的合成图像,但该模型仅适用于未配对的图像。为了增加这个问题,每个生成器的输入都是前一个生成器生成的合成输出。因此,它不能用于满足条件的成对图像训练,为了缓解这个问题,需要建立一个可以将特征从 Coarse 扩展到 Fine 生成器的连接。在本文中,提出了这样一种架构,它在粗调生成器和精调生成器之间具有特征附加机制,使其成为一个具有多尺度判别器的两级金字塔网络。
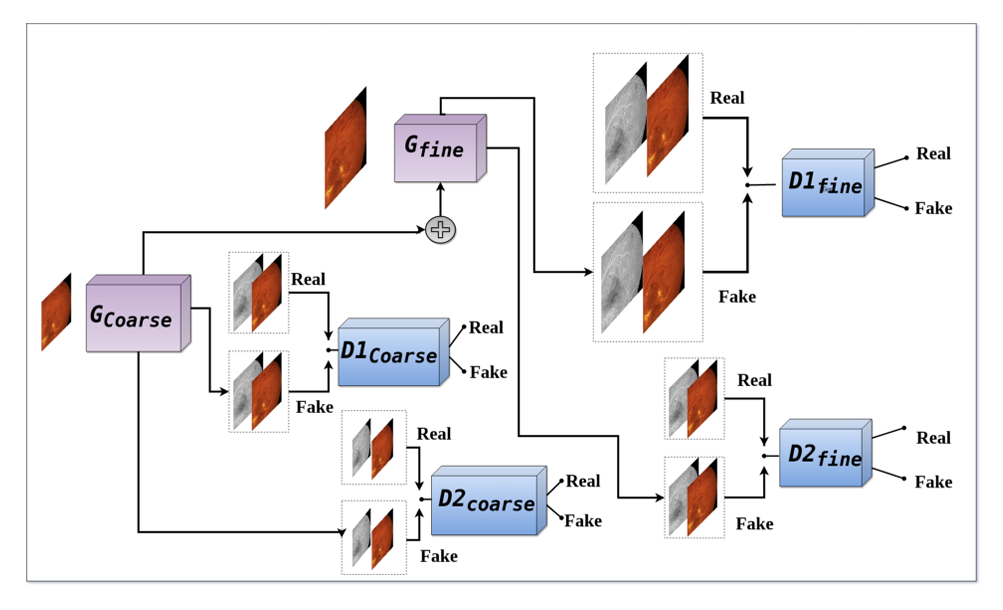
提出的生成对抗网络由两个生成器 Gcoarse、Gfine 和四个判别器 D1coarse、D1fine、D2fine、D2coarse 组成。生成器将 Fundus 图像作为输入并输出 FA 图像。然而,判别器将 Fundus 和 FA 图像作为输入和输出,无论这些图像对是Real的还是Fake。
1.创新的残差块(Novel Residual Block)
研究表明,穿插卷积层可以实现更高效、更准确的网络。将这个想法结合起来,设计了一种新的残差块来保留深度和空间信息,降低计算复杂性并确保高效的内存使用。

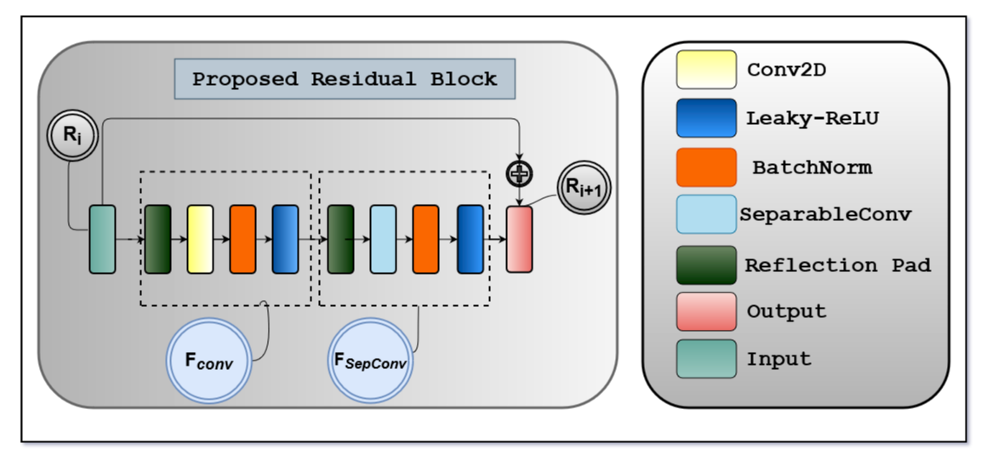
建议的残差块由两个残差单元 Fconv 和 FSepConv 组成。第一个是 Reflection padding、Convolution、Batch-Normalization 和 Leaky ReLU 层。第二个版本有一些层,除了具有 Separable Convolution 而不是 Vanilla Convolution。Ri 和 Ri+1 表示残差块的输入和输出。
还使用 Batch-normalization 和 Leaky-ReLU 作为 post卷积层和可分离卷积层之后的激活机制。为了获得更好的结果,在每次卷积操作之前都加入了反射填充,而不是零填充。
2.粗生成器和精生成器( Coarse and Fine Generators)
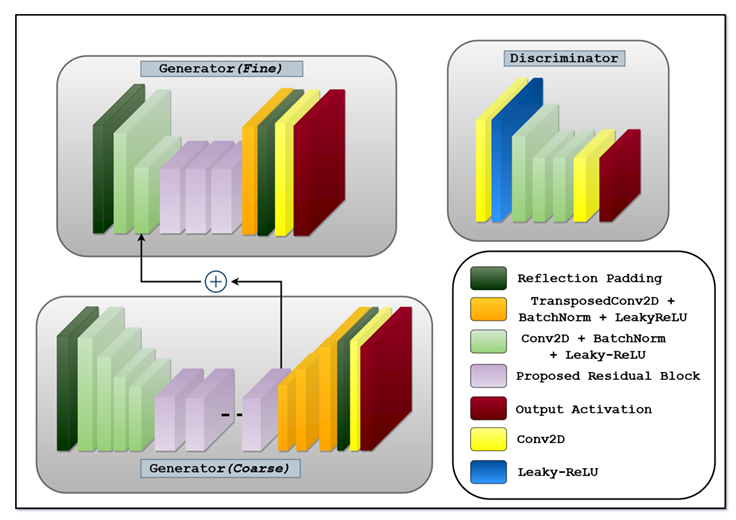
Gfine 由两个编码块(浅绿色)组成,然后是三个残差块(紫色)和一个解码块(橙色)。Gcoarse 由 4 个编码块(浅绿色)组成,然后是 9 个残差块(紫色)和 3 个解码块(橙色)。判别器由三个编码块(浅绿色)组成。两个发生器都有中间 Conv2D、反射填充层和 TanH 作为输出激活函数。而判别器具有中间 Conv2D、Leaky-ReLU 层和 Sigmoid 作为输出激活。
生成器 Gfine 通过学习局部信息(包括视网膜小静脉、小动脉、出血、渗出物和微动脉瘤),从眼底图像中合成精细血管造影。另一方面,生成器 Gcoarse 试图提取和保留全局信息,例如黄斑的结构、视盘、颜色、对比度和亮度,同时生成粗略的血管造影。
生成器 Gfine 获取大小为 512x512 的输入图像,并生成具有相同分辨率的输出图像。同样,生成器 Gcoarse 网络获取大小为一半 (256x256) 的图像,并输出与输入大小相同的图像。此外,Gcoarse 还输出大小为 256x256x64 的特征向量,该向量最终与 Gfine 的中间层之一相加。
3.多尺度 PatchGAN 作为判别器
GAN 判别器需要适应粗生成和精细生成的图像,以区分真假图像。作者利用了使用两个马尔可夫判别器的想法,该判别器最初是在一种称为 PatchGAN 的技术中引入的,以解决更深架构、更宽感受野内核带来的过度拟合并增加参数数量问题。
尽管判别器具有相似的网络结构,但以较低分辨率学习特征的判别器具有更宽的感受野。它尝试提取和保留更多的全局特征,如黄斑、视盘、颜色和亮度等,以生成更好的粗糙图像。相比之下,以原始分辨率学习特征的判别器指示生成器产生精细特征,例如视网膜静脉和动脉、渗出物等。通过这样,将全局和局部尺度的特征信息结合起来,同时独立地训练生成器及其成对的多尺度判别器。
4.加权对象函数和对抗性损失
使用 LSGAN来计算损失并训练条件 GAN。
判别器首先在真实眼底 x 和真实血管造影图像 Y 上进行训练,然后在真实眼底 x 和假血管造影图像 G(x) 上进行训练。首先训练判别器 Dfine 和 Dcoarse,对随机批次的图像进行几次迭代。接下来,在保持判别器权重冻结的同时训练 Gcoarse。之后,以类似的方式在一批随机样本上训练 Gfine。使用均方误差 (MSE) 来计算生成器的单个损耗,
实验结果
数据集
使用 Hajeb 等人提供的 funuds 和血管造影数据集。该数据集包括来自 59 名患者的 30 对糖尿病视网膜病变和 29 对正常血管造影和眼底图像。因为,并非所有对都完全对齐,所以根据对齐选择了 17 对进行实验。图像要么完全对齐,要么几乎对齐。眼底和血管造影的分辨率如下 576 720。眼底照片为 RGB 格式,而血管造影为灰度格式。由于数据短缺,从每张图像中随机提取 50 个 512 512 大小的裁剪来训练模型。因此,训练样本的总数为 850 (17x50)。
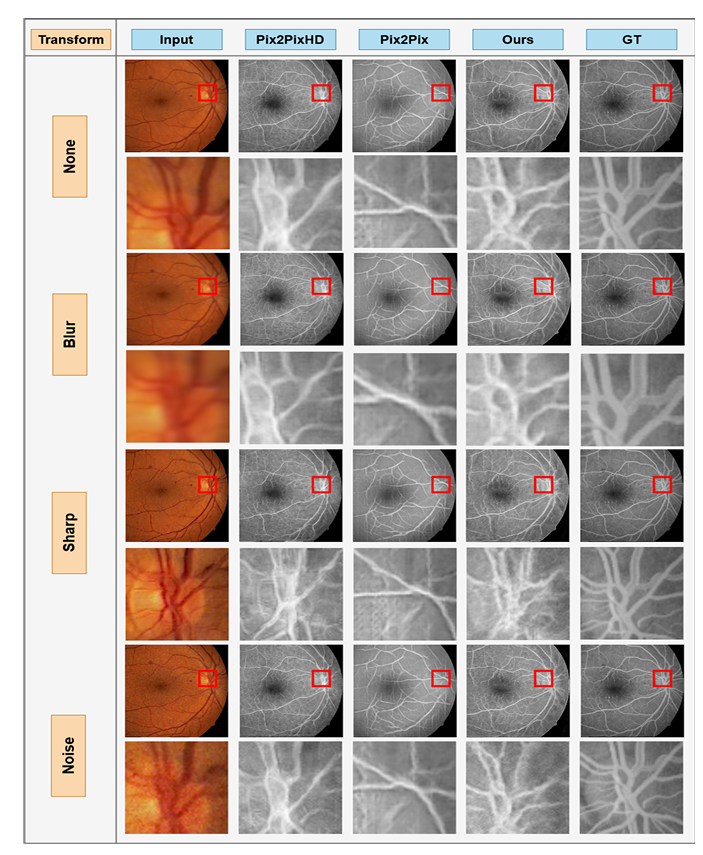
从转换后的眼底图像生成的血管造影。第一行显示原始图像、眼底实况和从不同架构生成的血管造影。第二行显示所选区域的封闭版本。红色边界框表示该特定区域。每行对说明的 None、Blur、Sharp 和 Noise 变换。
总结
本文介绍了 Fundus2Angio,这是一种新颖的条件生成结构,能够从视网膜眼底图像生成血管造影。通过从转换和扭曲的眼底图像中合成高质量的血管造影,进一步证明了它的稳健性、适应性和可重复性。此外,生物标志物的变化如何不会影响合成血管造影的适应性和可重复性。这确保了所提出的结构有效地保留了已知的生物标志物(例如 血管模式和结构)。因此,所提出的网络可以有效地用于生成准确的 FA 图像对于同一患者,从眼底图像随时间的变化。这样可以更好地控制患者的疾病进展监测或帮助发现新开发的疾病或病症。这项工作的一个未来方向是改进这项工作,以结合视网膜血管分割和渗出物定位。