0-SAM2POINT: SEGMENT ANY 3D AS VIDEOS IN ZERO-SHOT AND PROMPTABLE MANNERS
SAM2POINT: SEGMENT ANY 3D AS VIDEOS IN ZERO-SHOT AND PROMPTABLE MANNERS

arXiv:2408.16768v1 [cs.CV] 29 Aug 2024
SAM2POINT:以零镜头和提示的方式将任何 3D 分割为视频
背景
SAM2有Zero-shot和可提示的3D分割,本文作者提出SAM2POINT将任何3D数据解释为多向视频,利用SAM2进行空间分割,支持3D点,蒙版,框提示进行分割,并且泛化到3D 对象、室内场景、室外场景和原始激光雷达各种场景。
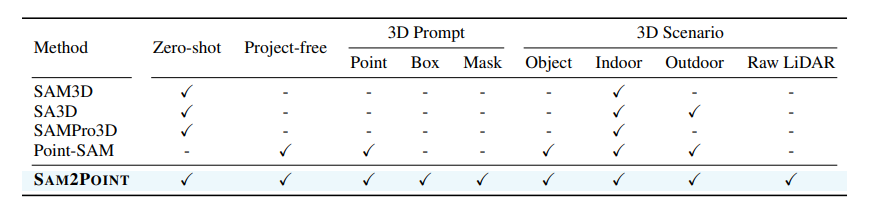
SAM自被提出后,在各个领域有广泛的应用,但是有效地调整 SAM 以适应 3D 分割仍然是一个尚未解决的挑战,存在的问题有:2D-3D 投影效率低下、3D 空间信息退化、失去提示灵活性、有限的域可转移性,本文提出的SAM2POINT展示在不同环境中有效的分割潜力,具体是:将任何 3D 分割为视频,支持多个 3D 提示、可推广到各种场景的优点。
实验方法
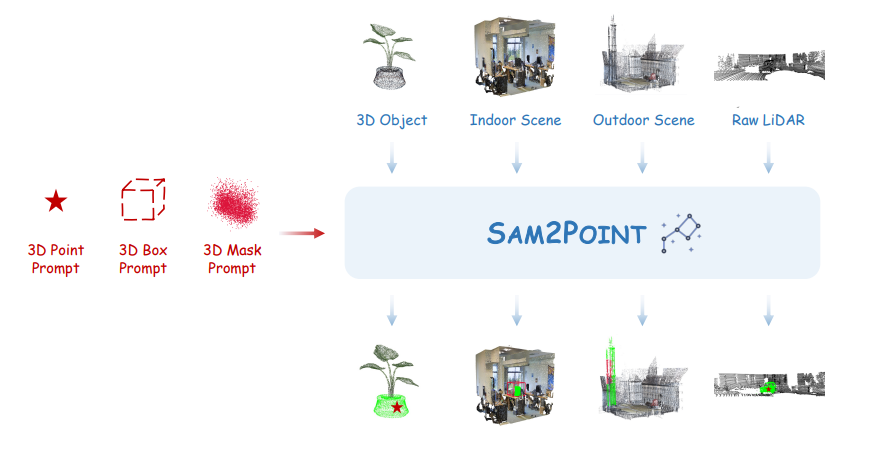
图1:SAM2POINT 的分割范式。引入了一个零镜头和可提示的框架,用于通过 SAM 2 进行稳健的 3D 分割。它支持各种用户提供的 3D 提示,并且可以泛化到不同的 3D 场景。3D 提示和分段结果分别以红色和绿色突出显示
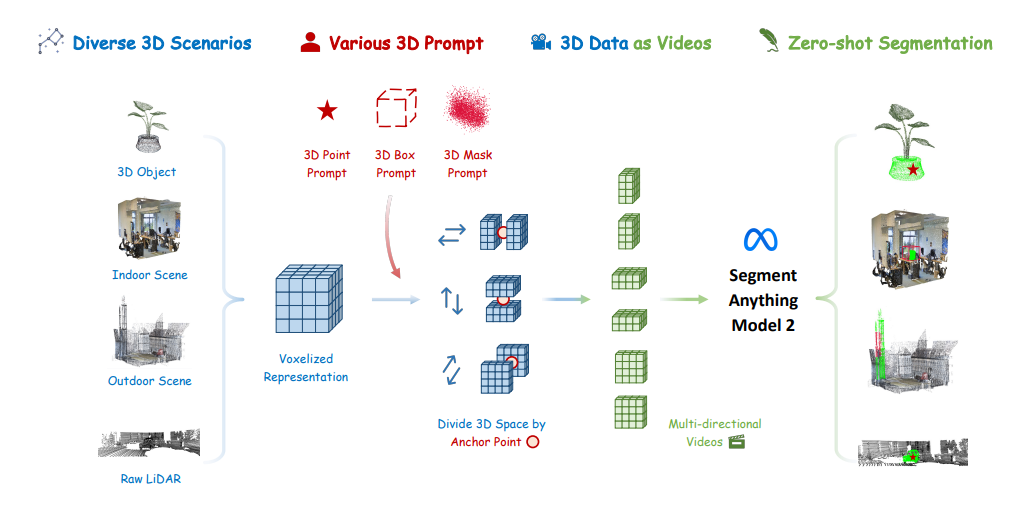
图 2:SAM2POINT 的详细方法。将任何输入的 3D 数据转换为体素化表示,并利用用户提供的 3D 提示沿六个方向划分 3D 空间,从而有效地模拟 SAM 2 的六个不同视频以执行零镜头分割。
1.将3D数据视为视频
将3D的一个点视为$P=(x,y,z,r,g,b)$,将P表示为一种数据格式,很好的保留细粒度的空间几何图形,采用3D体索化技术(在之前的工作中,体索化在3D空间中避免信息退化和繁琐的后处理)。
3D体索化表示为$v \in R ^{w\times h\times l \times l}$,每个体索为$v=(r,g,b)$,根据在最近的体索中心位置设置v的值,此格式与视频很类似,视频数据包含t帧的时间依赖性,作者将体索表示为一系列的多向视频,从而让SAM2以与视频相同的方式分割3D。
2.可提示的分割
SAM2POINT支持3种不同的提示方式进行分割:
- 3D点提示:$p_p=(x_p,y_p,z_p)$,为空间中的锚点,以此点分为F、B、L、R、U、D六个面,然后将其视为6个不同的视频,该点作为第一帧,$P_p$作为2D投影点提示,应用SAM2进行并发分割,最后将6个视频整合为最终的3D蒙版预测。
- 3D框提示:$b_p=(x_p,y_p,z_p,w_p,h_p,l_p)$,使用$b_p$的几何中心为锚点,进行3D点提示,对于6个面的其中一个面,使用$b_p$投影到目标2D面,作为分割的框点,另外还支持$(\alpha p,\beta p,\gamma p)$的旋转角度的3D框,原理同上。

- 3D蒙版提示:$M_p\in R^{n\times 1}$,其中1或0表示蒙版或未蒙版区域,以蒙版的重心作为提示点,分割为6个面的视频,3D 蒙版提示与每个部分之间的交集用作分段的 2D 蒙版提示。这种类型的提示还可以用作后优化步骤,以提高先前预测的 3D 掩码的准确性。

3.任何3D场景
3D 对象:具有广泛的类别,在不同实例中具有独特的特征,包括颜色、形状和几何形状。对象的相邻组件可能会相互重叠、遮挡或集成,这需要模型准确识别零件分割的细微差异。
室内场景:通常以多个对象布置在密闭空间(如房间)内为特征。复杂的空间布局、外观的相似性以及对象之间的不同方向给模型从背景中分割它们带来了挑战。
室外场:与室内场景不同,主要是由于物体(建筑物、车辆和人类)的鲜明尺寸对比和更大比例的点云(从一个房间到整条街道)。这些变化使对象的分割变得复杂,无论是在全局范围内还是在细粒度级别。
原始激光雷达(Raw LiDAR):例如自动驾驶中,与典型的点云不同,因为它分布稀疏且缺乏 RGB 信息。稀疏性要求模型推断缺失的语义来理解场景,而缺乏颜色迫使模型仅依靠几何线索来区分对象。在 SAM2POINT 中,直接通过 LiDAR 强度设置 3D 体素的 RGB 值。
实验结果
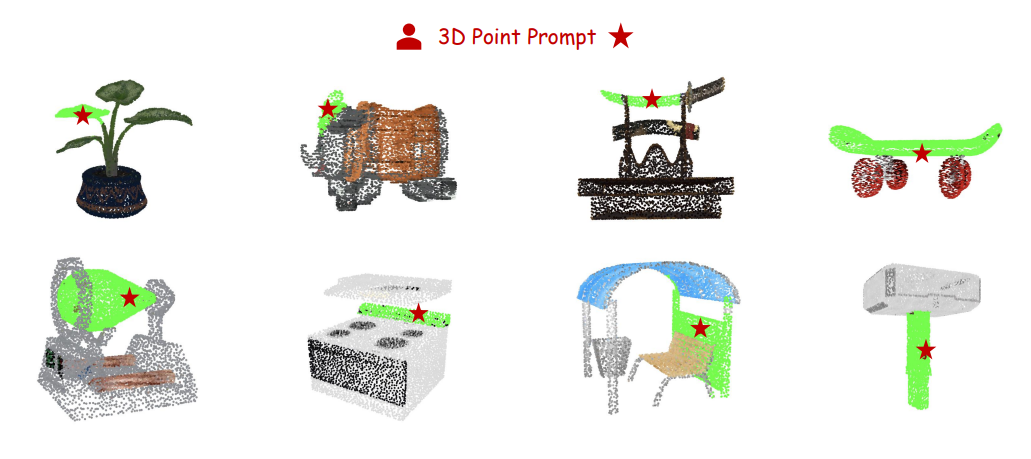
论文仅展示了3种分割方式在4种数据上的分割结果,并未对分割的准确率进行展示,上文展示了3种分割结果在3D对象分割的结果,其余3种数据详见原文4DEMOS部分。
总结
SAM2POINT利用 Segment Anything 2 到 3D 分割,具有零镜头和可提示的框架。通过将 3D 数据表示为多向视频,SAM2POINT 支持各种类型的用户提供的提示(3D 点、框和掩码),并在各种 3D 场景(3D 对象、室内场景、室外环境和原始稀疏 LiDAR)中表现出强大的泛化能力。SAM2POINT 为调整 SAM 2 以实现有效和高效的 3D 理解提供了独特的见解。作者希望方法可以作为可快速 3D 分割的基础基线,鼓励进一步研究以充分利用 SAM 2 在 3D 领域的潜力。