0-SAM-UNet: Enhancing Zero-Shot Segmentation of SAM for Universal Medical Images
SAM-UNet: Enhancing Zero-Shot Segmentation of SAM for Universal Medical Images

arXiv:2408.09886v1 [cs.CV] 19 Aug 2024
SAM-UNet:增强通用医学图像的 SAM 零样本分割
背景
初始SAM在医学图像上并不适配,本文作者受到 U-Net 的模型在医学图像分割中的卓越性能的启发,提出了 SAM-UNet,这是一种将 U-Net 整合到原始 SAM 的新基础模型,以充分利用卷积强大的上下文建模能力。在图像编码器中并行了一个卷积分支,该分支是用 vision Transformer 分支冻结独立训练的。此外,在掩码解码器中采用了多尺度融合,以促进对不同尺度目标的准确分割。 SA-Med2D-16M 上训练 SAM-UNet,产生了一个通用的医学图像预训练模型。在零镜头分割实验中,模型不仅在所有模态中都明显优于以前的大型医用 SAM 模型,而且还大大减轻了在看不见的模态上看到的性能下降。SAM-UNet 是一种高效且可扩展的基础模型,可以针对医学界的其他下游任务进一步微调。
- 具体来说,作者分别介绍了图像编码器和掩码解码器中的两种架构设计。首先,在图像编码器中加入一个并行卷积神经网络 (CNN) 分支,原始的 Vision Transformer (ViT) 分支完全冻结,以保留 SAM 的自然图像编码能力,利用多尺度融合策略来实现多尺度目标的准确分割,并进一步采用了输出令牌设计,使掩码解码器更专门用于医疗领域。
- 介绍了架构创新,包括在图像编码器中集成并行 CNN 分支,在掩码解码器中集成多尺度融合设计,这构成了部分参数的新方法SAM 的微调,这两者都已被证明可以有效提高分段性能。
- 提出了 SAM-UNet,这是一个在 SA-Med2D-16M 上训练的强大基础模型,增强了 SAM 在通用医学图像上的零镜头分割能力。SAM-UNet 在各种医学影像模态中均具有卓越的性能(SA-Med2D-16M 测试集的 DSC 评分为 0.883)。
- 开发了两个版本的 SAM-UNet,即 SAM-UNet-34 和 SAM-UNet-50,其中 SAM-UNet-50 具有更大的参数规模,表现出特别强的性能。
- 在 7 个外部数据集上进行了零镜头分割实验,证明 SAM-UNet 的性能明显优于现有的基于 SAM 的模型。SAM-UNet 在训练集中充分代表的模态(如 CT 和 MR)中表现出卓越的性能,并在不太常见的模态中保持稳健的性能而不会显着退化。
实验方法
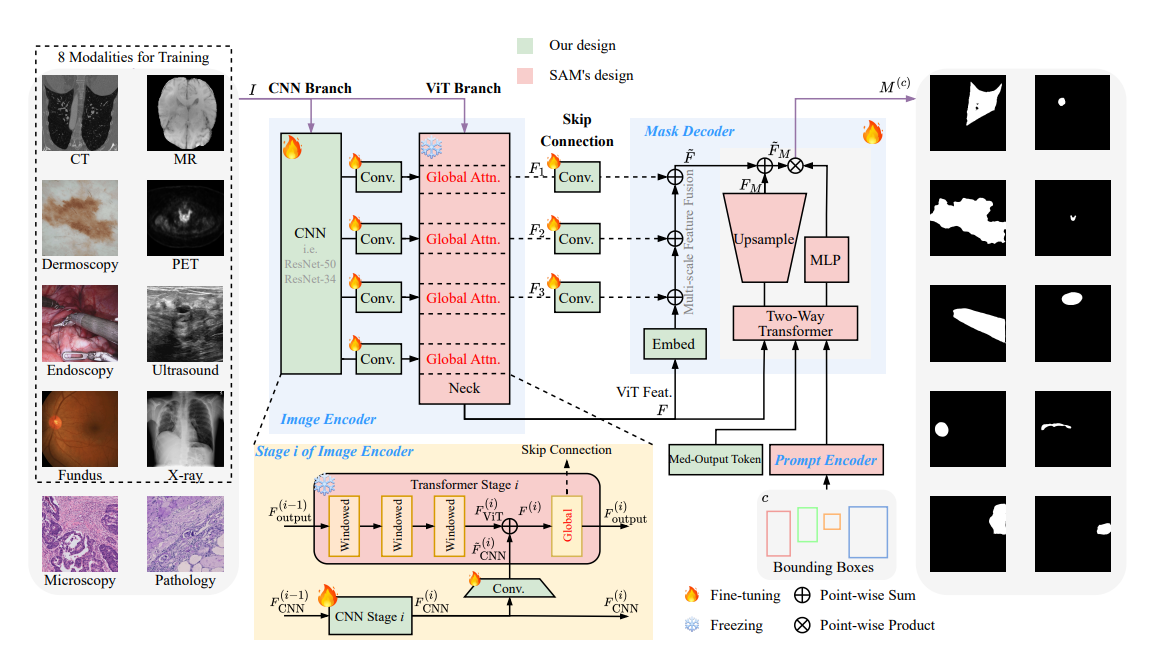
SAM-UNet。该模型由一个双分支图像编码器和一个多尺度融合掩码解码器组成。它是在包含图中所示的八种模态的大型数据集上使用边界框作为提示进行训练的,并在所有十种模态上进行了测试。该图还说明了图像编码器中每个阶段的详细信息。
SAM:SAM 由三个组件组成:大规模图像编码器、提示编码器和轻量级掩码解码器。图像编码器利用 ViT 来处理高分辨率图像,并以原始图像的 1/16 比例生成特征图。提示编码器接受稀疏和密集提示,包括点、边界框或掩码,将它们转换为 256 维向量。然后,掩码解码器采用轻量级交叉注意力机制来集成来自图像和提示编码器的嵌入,从而允许 SAM 根据不同的提示为同一图像生成不同的掩码。
双分支图像编码器:将 CNN 分支合并到原始 ViT 分支中。在训练阶段只训练参数明显较少的 CNN 分支,而 ViT 分支被冻结。需要注意的是,所有版本的 SAM 中的图像编码器都由四个阶段组成,每个阶段由几个窗口注意力 Transformer 模块和一个全局注意力 Transformer 模块组成。为了优化内存使用并加速推理过程,SAM-UNet 使用 SAM 的 ViT-B 版本作为初始模型。为了匹配 ViT 的四级设计,集成的并行 CNN 也由四个级组成。

提示编码器:SAM-UNet 中的提示编码器与 SAM 保持一致。对于每个边界框,提示编码器使用位置编码对“左上角”和“右下角”像素的中心位置进行编码,生成两个 256 维向量。
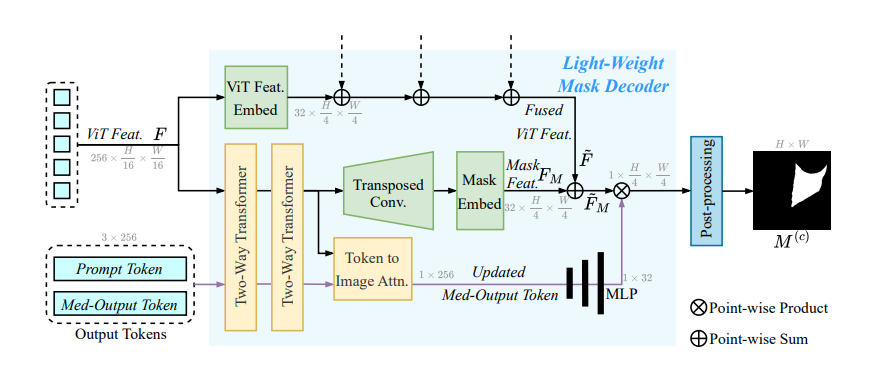
具有多尺度特征融合的掩码解码器:
- Med-Output 令牌。受 SAM-HQ 的启发,引入了 Med-Output Token(大小为 1×256),并丢弃了原始 SAM 中使用的 IoU 预测令牌和多个掩码令牌。SAM 采用 IoU 预测令牌和多个掩码令牌的原因是,基于点的提示可能会在自然图像中产生歧义。因此,生成多个掩码并根据 IoU 预测分数选择最合适的掩码是合理的。然而,在以边界框作为提示的医学图像分割场景中,这种歧义很少见,因此无需输出预测的 IoU 分数和多个掩码。消融研究也证明了这种变化的有效性。
- 多尺度融合分支。在编码器特征图中添加了一个类似 U-Net 的多尺度融合分支,与 CNN 类似,ViT 在早期的 Transformer 块中保留了更多的边缘信息,这可以提高分割精度——这也是类似 U-Net 的网络在分割任务中如此有效的原因。更新后的 Med-Output Token 已获取全局图像上下文和提示令牌信息,通过三层 MLP 进行处理,掩码解码器根据提示 成功生成掩码。
SAM-UNet 训练:训练数据集是 SA-Med2D-16M。
损失函数是:
$$
L = 20 × L_{Dice} + L_{Focal}
$$
实验结果
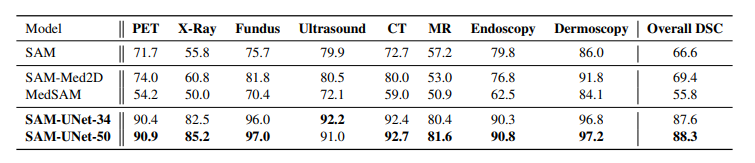
SAM-UNet-50、SAM-UNet-34、SAM-Med2D、MedSAM 和 SAM 在大规模测试集上各种模态的性能比较
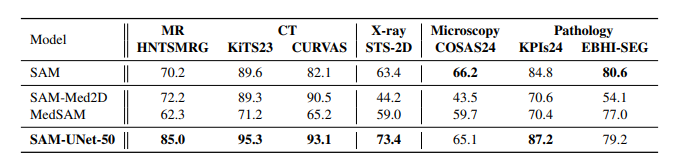
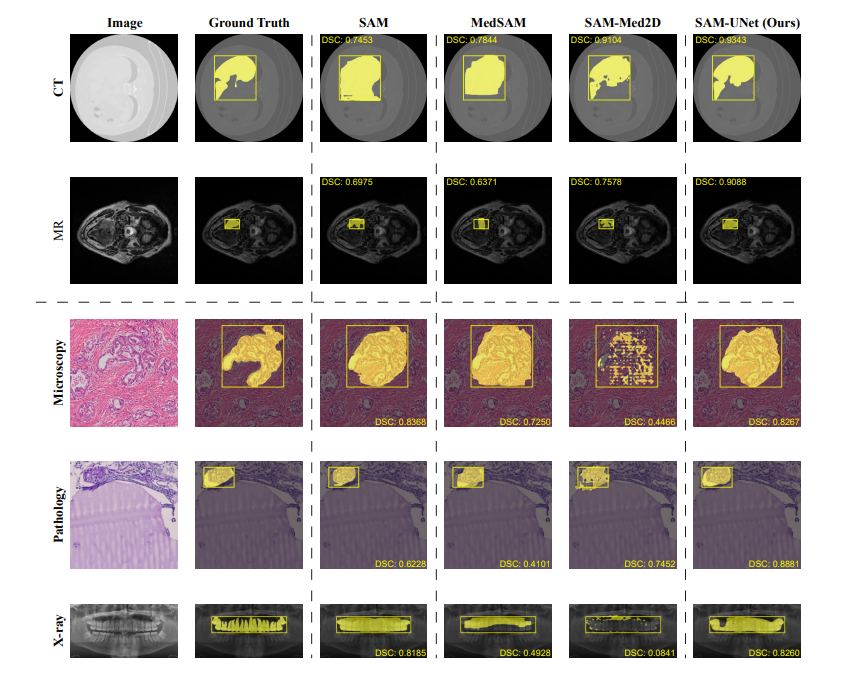
SAM-UNet-50、SAM-Med2D、MedSAM 和 SAM 在看不见的模态和数据集上的零镜头分割实验中的性能比较。
总结
本文介绍了一种新颖有效的 SAM 部分参数微调架构,并提出了一个基础模型 SAM-UNet,该模型在最大的可用医学图像分割数据集上进行了训练。架构创新包括一个双分支图像编码器和一个具有多尺度融合的掩码解码器。模型在测试集上实现了 SOTA 性能,并在 7 个外部数据集的零镜头分割中表现出更稳定和卓越的性能。