0-MEDICAL SAM 2: SEGMENT MEDICAL IMAGES AS VIDEO VIA SEGMENT ANYTHING MODEL 2
MEDICAL SAM 2: SEGMENT MEDICAL IMAGES AS VIDEO VIA SEGMENT ANYTHING MODEL 2

MEDSAM2 arXiv:2408.00874v1 2024年8月
背景
Meat公司在23年发表了SAM(segment anyting),有一定颠覆传统CV任务的趋势,在24年4月Meat公司继续发表了SAM2模型,基于SAM模型良好的zero-shot能力、实时检测能力、适应管理复杂场景下的物体遮挡问题,MedSAM2将连续的医学图像看作视频进行分割,取得了非常好的效果。
医学图像分割的一个重大挑战是模型泛化。具体来说,在特定目标上训练的模型无法轻松适应其他目标。MedSam2模型实现了One-Prompt功能,允许在模型处理数据时随时随地在任何帧上优化分割目标,极大提高了临床医学的便捷性,这是之前的模型难以处理的。
- 采用了一种新颖的医学图像即视频理念,这激发了设计一种独特的管道,以解锁 MedSAM-2 中的一键分割功能,这是以前的方法几乎无法实现的功能。
- 开发了独特的模块和管道,结合了置信度内存库和加权拾取,以在技术上促进这一能力。
- 根据 15 个不同的基准(包括 26 个不同的任务)评估了 MedSAM-2,在这些基准测试中,该模型实现了卓越的性能。
实验方法
3D图像
将连续的2D医学图像视为一个序列来提供上下文信息,以减小在拍摄病人时因患者的移动或者设备的晃动产生的影响。
iVOS的单点提示分割
iVOS 的目标是让模型在视频中对任意目标进行交互式分割,而不需要预先知道目标类别。
假设数据集S,图片标签对$<!–swig0–>$,学习函数$y_s=f_{\theta}^d(x_s)$ ,其中输入图像$y_s$分割图$x_s$ ,在iVOS任务
$$
y^k=f_{\theta}(x_u^k,P_u)
$$
$x_u^k$ 表示图像包含看不见的对象 u,而 $P_u$ 是目标看不见的对象 u 上的一组提示,以提示模型对包含该对象的任何可能的 x 进行泛化,这样看来iVOS和 One-Prompt Segmentation 在某些任务上是十分相似的。
将3D图像视为视频分割
核心概念包括使用过去预测和提示帧的记忆来调节帧嵌入、图像后编码器。为了让用户单点分割时的信息能传递到其他的输入图像流中,作者还使用了独特的内存机制,
与 SAM 2 中使用的临时先进先出队列不同,引入了一个“置信度优先”内存库来存储模型的模板。此方法可确保内存库中的模板是模型识别的最准确样本,从而最大限度地减少嘈杂模板的影响。在将图像添加到 SoundBank 时,还实现了图像多样性约束,确保内存包含各种图像,以更好地匹配传入的输入图像。
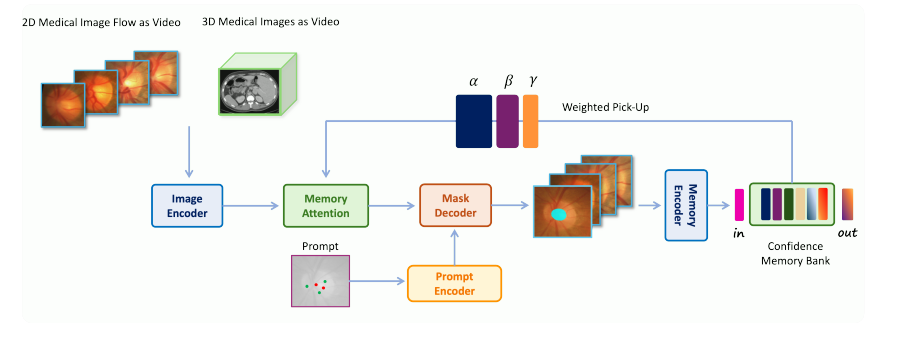
MedSAM2d的架构
Med-SAM2 具有一个将输入抽象为嵌入的图像编码器、一个抽象预测帧嵌入的内存编码器,以及一个使用存储在内存库中的内存来调节输入嵌入的内存注意机制。编码器由一个分层视觉转换器组成,解码器由一个轻量级双向转换器组成,该转换器将提示嵌入与图像嵌入集成在一起。提示嵌入由提示编码器生成,该编码器处理用户的提示以抽象相应的嵌入,记忆注意力组件由一系列堆叠的注意力块组成,每个注意力块都包含自我注意力块,后跟交叉注意力机制,因为内存注意力机制结合了用户提供的中间提示来优化分割结果。
实验结果
在实验中,MedSAM-2 在包括腹部器官、视神经、脑肿瘤和皮肤病变在内的15个不同医学数据集上表现出色。特别是在3D腹部器官分割中,MedSAM-2 达到了 88.6% 的 Dice 分数,比之前的最佳模型高出 0.7 个百分点。此外,该模型在视神经、脑肿瘤和甲状腺结节等2D图像分割中,也分别提高了2到3个百分点,并与最先进的SOTA进行比较。实验结果参考link。

总结
MedSAM-2 鼓励进一步的发展和在临床实践中的应用。这种模型不仅提升了医学图像分析的精度,也显著减少了手动标注的工作量,为未来的医学成像工作流带来了变革性的潜力。