0-Learnable Ophthalmology SAM
Learnable Ophthalmology SAM

arXiv:2304.13425v1 [cs.CV] 26 Apr 2023 可学习的眼科 SAM
背景
针对眼科图像分析中的分割问题,由于眼科图像的多模态特性,现有的分割算法大多依赖于大量标签的训练或者泛化能力较弱,导致其应用受限。
为了解决这一问题,本研究提出了一种适用于眼科多模态图像中多目标分割的方法,即可学习的眼科“分割任何物”(SAM)。
实验方法
1:多模态图像导致的分割目标差异问题
采用可学习提示层
- 由于眼科图像包括彩色眼底图、光学相干断层扫描(OCT)等多种模态,每种模态图像的分割目标(如血管、视网膜层)不同,现有单一模型难以适应。
- 通过引入可学习的提示层,使模型能够在不同模态图像中自动学习和识别分割目标,如在OCT图像中学习到视网膜层的特征,在彩色眼底图中学习到血管的特征,提高了模型的适应性和泛化能力。
比如有一组眼科图像,包括彩色眼底图和OCT图像。
彩色眼底图主要用于观察眼底的血管分布,而OCT图像则提供视网膜各层的详细结构。
传统的分割模型可能在彩色眼底图上表现良好,能够识别出血管,但在OCT图像上却难以分辨出视网膜的不同层次。
通过引入可学习的提示层,模型在处理OCT图像时能自动调整其学习重点,识别出视网膜的各个层次,而在处理彩色眼底图时则专注于血管的识别。
这种自适应能力显著提高了模型在多模态图像上的适用性和准确性。
2:现有基础视觉模型在医学图像上应用受限
一次性训练机制的引入
- 基于大型视觉模型如SAM或DINOv2进行医学图像分割时,直接应用这些模型往往不能有效分割医学图像中的血管或病变。
- 通过只对可学习的提示层和任务头进行一次性训练,而不是全模型微调,可以有效地将这些基础模型适配到医学图像分割任务上。
- 这种方法利用了基础视觉模型在特征提取上的优势,通过学习少量的医学先验知识来实现高效准确的分割。
在使用基于Transformer的大型视觉模型(如SAM)进行医学图像的血管分割时,直接应用通常结果不理想,因为这些模型未针对复杂的医学图像特征进行优化。
通过对SAM的提示层和任务头进行一次性训练,例如在一张具有明显血管结构的彩色眼底图上进行训练,模型能够学习到如何在医学图像中识别血管,而不需要在整个大规模数据集上重新训练。
这种方法不仅节省了大量的训练时间和资源,而且使模型能够有效地适用于特定的医学图像分割任务。
3:提高分割精度和泛化能力
子解法3:深度可分离卷积的应用
- 在构建可学习提示层时,采用了1x1卷积、层归一化、GELU非线性激活函数,以及深度可分离的3x3卷积来捕获特征的局部模式。
- 这种结构设计帮助模型更好地理解医学图像中的细节和结构,如通过深度可分离卷积提取血管或视网膜层的局部特征,从而提高了分割的精度和模型对不同数据集的泛化能力。
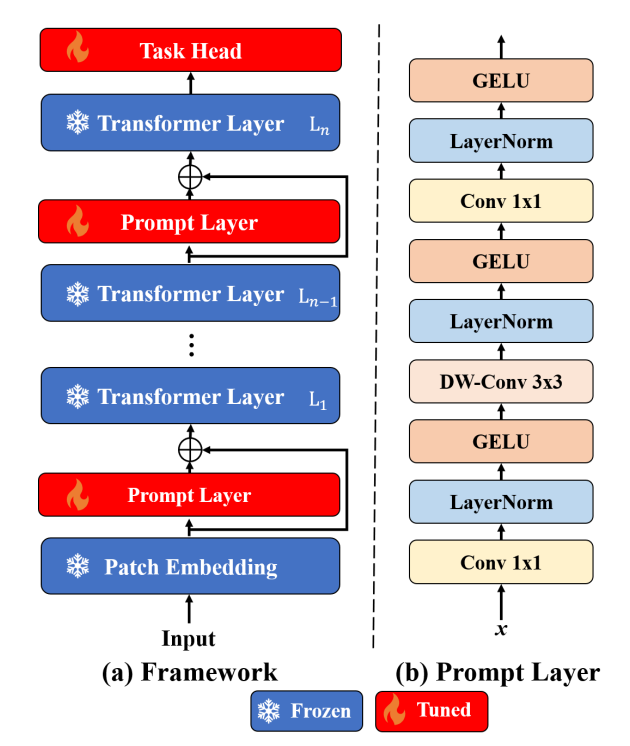
从输入到任务头的流程,并在变换器层之间插入了提示层。
图的部分(b)是,提示层的架构,包括1x1卷积、层归一化、GELU激活函数和3x3深度卷积层。
在处理OCT图像时,模型需要识别和分割出视网膜的多个层次。
通过在可学习提示层中使用深度可分离的3x3卷积,模型能够更有效地捕捉到视网膜层次之间的微妙差异,例如识别出神经纤维层和视网膜色素上皮层。
这种深度可分离卷积的应用不仅提高了分割的精度,而且因为其参数更少,也增强了模型在不同数据集间的泛化能力。
相比于传统的卷积层,这种方法在维持高分辨率特征图的同时,有效减少了计算复杂度和模型的参数量,使得模型在处理复杂的医学图像时更加高效和准确。
实验结果

LOSAM(眼科SAM)算法在分割眼底血管和病变方面与基础的计算机视觉模型相比,提供了显著改善。
特别是在处理DINOv2和SAM无法有效识别的细小血管和病变时,LOSAM算法能够更接近真实情况,这证明了其对于眼科图像具有更好的适用性和准确性。
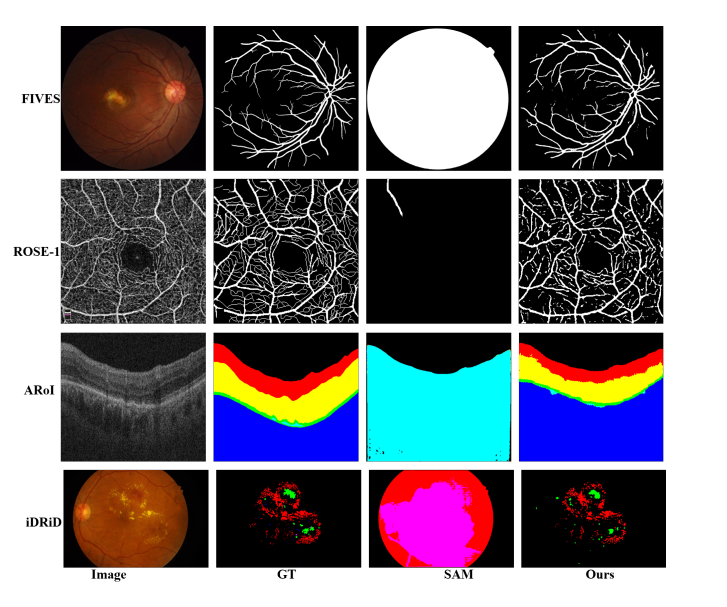
LOSAM 算法,在多种眼科图像分割任务上都能取得好的结果,包括血管分割、病变分割和视网膜层分割。
可视化结果展示了与真实情况相比,该算法在保留细节和结构方面的有效性。
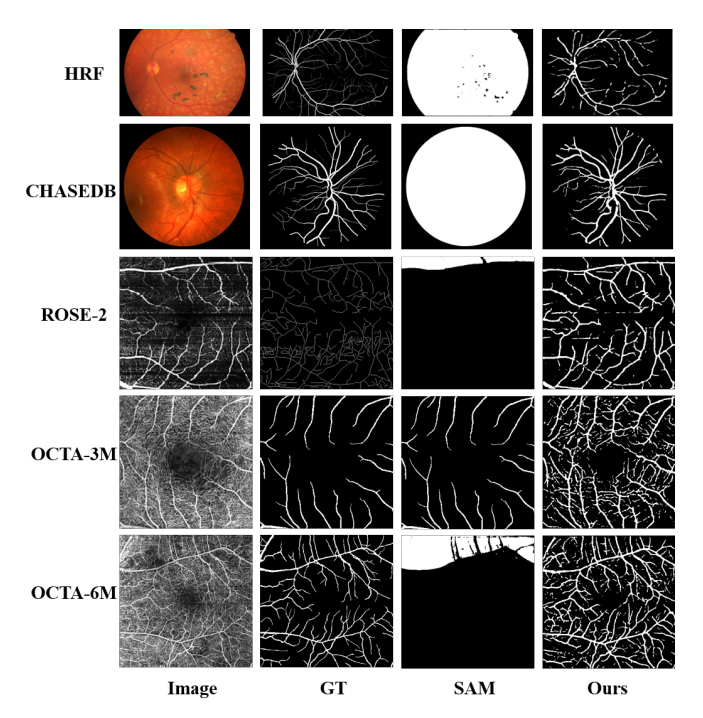
LOSAM 算法具有良好的泛化能力,即在一个数据集上训练后,能够在没有进一步训练的情况下,成功地应用于其他不同的数据集。
这表明了算法在处理不同成像条件下的图像时的稳健性。
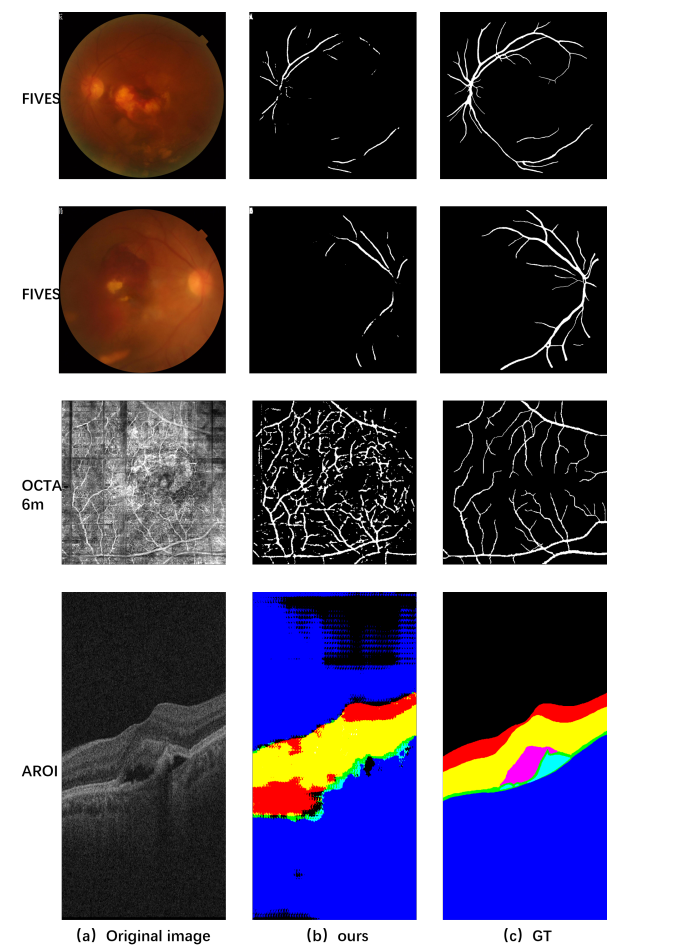
图像质量对分割算法的性能有显著影响,LOSAM在处理低质量图像时可能无法达到理想的分割效果。
这些失败的例子说明了改进算法以处理低质量图像的必要性。
低质量图像具体可能指以下情况:
低分辨率:图像的细节不够清晰,无法准确识别或分割图像中的重要特征,如血管、病变或视网膜层。
运动模糊:由于患者移动、手抖或设备问题导致的图像模糊,这会使得分割任务变得更加困难。
照明不足:图像因为照明不当(过暗或过亮)而丢失信息,导致关键的细节无法被辨识。
噪声干扰:图像中存在的随机变化(如电子噪声、压缩伪影)可能会干扰算法识别出真正的信号。
对比度低:图像中物体之间的对比度不足,使得算法难以区分目标和背景。
伪影:由成像设备的缺陷或处理错误引入的非真实结构,这些伪影可能会误导分割算法。
成像设备的差异:不同的成像设备可能会因为硬件的差异而产生不同质量的图像。
压缩损失:为了减少存储空间,图像可能被压缩,导致重要的细节信息丢失。
通常需要通过预处理步骤(如图像增强、去噪、对比度调整)来改善图像质量,或者通过改进算法使其对低质量图像更加鲁棒。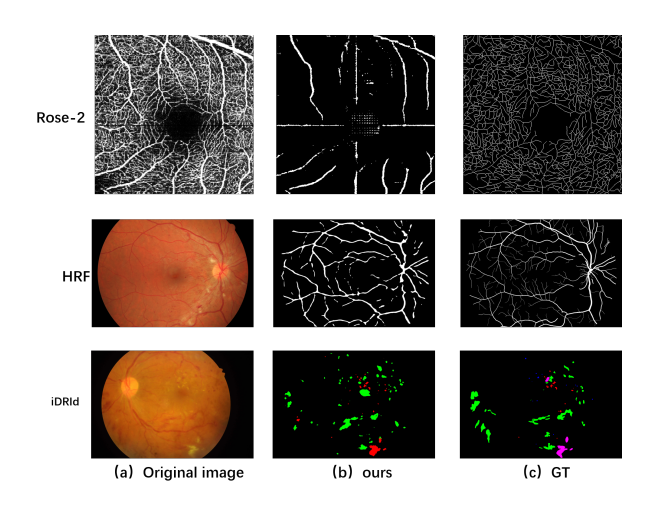
LOSAM算法在识别和分割图像中的小目标上存在局限性,尤其是当目标尺寸非常小或与背景对比不明显时。
所以,在应用中需要进一步提升算法在处理微小目标上的能力。
结论
多模态图像的分割不一致性—–可学习提示层(Learnable Prompt Layer)
原因: 多模态图像(如彩色眼底和OCTA图像)具有不同的成像特征,标准模型可能在一个模态上表现良好,在另一个模态上表现不足。可学习提示层允许模型在每个模态上捕捉和学习特定的特征,从而提高分割的一致性和准确性。
例子: 在彩色眼底图像中,可学习提示层帮助模型区分了主要血管和次要血管,尽管分割微小血管仍然具有挑战性。
OCT图像中的视网膜层精确分割——体数据增强(Volume Data Augmentation)
原因: OCT图像通常以三维数据形式存在,需要模型能够理解和处理这种体数据。体数据增强通过提供更丰富的三维信息来训练模型,从而提高分割视网膜层的精度。
例子: 对于ARoI数据集的OCT层分割任务,体数据增强使得LOSAM在Dice评分上显著提高。
小目标物的分割困难——目标大小感知分割(Size-Aware Segmentation)
原因: 小目标物,如微动脉瘤,可能在图像的预处理阶段被丢失或在分割过程中难以辨认。目标大小感知分割专注于改进模型对于不同大小目标物的识别能力,特别是提高小目标的检测率。
例子: 在iDRiD数据集上,LOSAM通过目标大小感知分割在大的病变(出血和硬渗出)上取得了成功,但对于小的病变(微动脉瘤和软渗出)的分割仍然是一个挑战。
算法泛化到新的、未见过的数据集—–零次学习泛化(Zero-Shot Learning Generalization)
原因: 算法需要在训练时未见过的新数据集上仍然表现良好,这要求算法具有良好的泛化能力。零次学习泛化是在算法没有直接从特定数据集学习的情况下,验证其在新数据集上的表现。
例子: 经过在FIVES数据集上的训练,LOSAM在HRF和CHASEDB数据集上的血管分割表现出了优秀的泛化能力,证明了其不依赖于特定数据集的训练就能够实现有效的分割。
代码分析
code:https://github.com/Qsingle/LearnablePromptSAM
训练部分需要注意数据集的mask是否是二值图像,调整divide_mask的值(255),代码使用的SAM的自定义模型 PromptSAM,并且删除了部分层(如 prompt_encoder 和 mask_decoder),并对其他层(如 blocks)做了修改。这可能导致保存的模型权重与加载时的模型结构不一致。基于 SAM 模型进行的微调,并且仅冻结了 image_encoder,则需要确保训练时间足够长(epoch 数量、学习率等参数调整),以让新的任务(例如语义分割)适应当前数据集,最后在IDRiD和CHASEDB1数据集上分割失败,IOU为0。失败原因未知。