C-Vision Transformer (ViT)
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE

[v2] Thu, 3 Jun 2021 13:08:56 UTC Vision Transformer (ViT)
背景
虽然Transformer架构已经成为自然语言处理任务的事实上的标准,但它在计算机视觉上的应用仍然有限。在视觉方面,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。本文证明这种对cnn的依赖是不必要的,直接应用于图像补丁序列的纯Transformer可以很好地完成图像分类任务。当对大量数据进行预训练并传输到多个中型或小型图像识别基准(ImageNet, CIFAR-100, VTAB等)时,Vision Transformer (ViT)与最先进的卷积网络相比获得了出色的结果,同时需要更少的计算资源进行训练。
实验方法
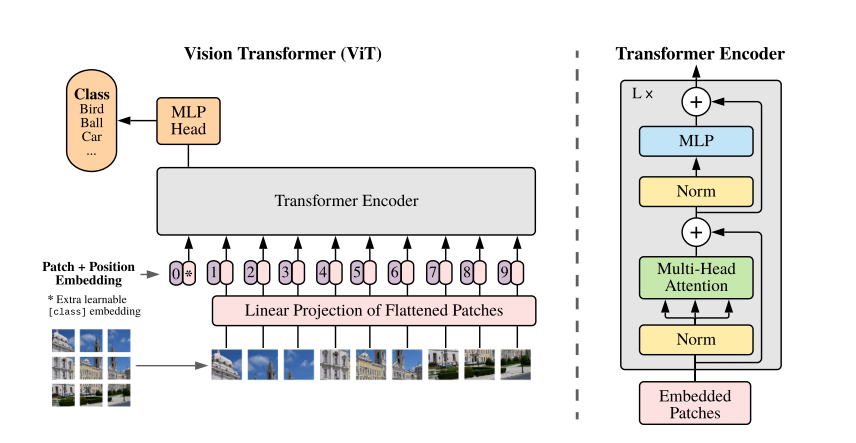
将图像分割成固定大小的补丁,线性嵌入每个补丁,添加位置嵌入,并将结果向量序列馈送到标准Transformer编码器。为了执行分类,使用标准方法向序列中添加一个额外的可学习的“分类令牌”。
多头自注意力机制:
标准qkv自注意是神经架构的流行构建块。对于输入序列$z∈R^{N×D}$中的每个元素,计算序列中所有值v的加权和。注意权$A_{ij}$基于序列中两个元素的成对相似度及其各自的查询$q_i$和键$k_j$表示。
$$
[q,k,v]=zU_{qkv} \ \ \ \ \ \ \ \ \ U_{qkv}\in R^{D\times3D_h},\
A=softmax(\frac{qk^T}{\sqrt{D_h}}) \ \ \ \ \ \
A\in R^{N\times N},\
SA(z)=A_v
$$
多头自注意(MSA)是自注意的扩展,其中并行运行k个自注意操作,称为“头”,并投影它们的连接输出。为了在改变k时保持计算量和参数数量不变,通常将$D_h$ 设为D/k。
$$
MSA(z) = [SA_1(z); SA_2(z); · · · ; SA_k(z)]U_{msa}\ \ \ \ \ \ \ \
U_{msa} ∈ R^{k·D_h×D}
$$
代码解析
Vision transformer 将纯 transformer 应用于图像,无需任何卷积层。它们将图像分割成块,并将 transformer 应用于块嵌入。通过对块的扁平像素值应用简单的线性变换来生成块嵌入。然后,将块嵌入以及分类 token 馈送到标准 transformer 编码器 。token 上的编码 用于使用 MLP 对图像进行分类。
在将补丁输入到 Transformer 时,学习到的位置嵌入会添加到补丁嵌入中,因为补丁嵌入不包含有关该补丁来自何处的任何信息。位置嵌入是每个补丁位置的一组向量,使用梯度下降法和其他参数进行训练。
ViT 在大型数据集上进行预训练时表现良好。本文建议使用 MLP 分类头对它们进行预训练,然后在微调时使用单个线性层。本文使用在 3 亿个图像数据集上进行预训练的 ViT 击败了 SOTA。他们还在推理过程中使用更高分辨率的图像,同时保持补丁大小不变。新补丁位置的位置嵌入是通过插值学习位置嵌入来计算的。
这是在 CIFAR-10 上训练 ViT 的实验。由于是在小型数据集上训练的,因此效果不佳。这是一个简单的实验,任何人都可以运行和使用 ViT。
1 | |
获取补丁嵌入
本文将图像分割成大小相同的块,并对每个块的扁平像素进行线性变换。
通过卷积层实现同样的事情,因为它实现起来更简单。
d_model是 transformer 嵌入的大小patch_size是补丁的大小in_channels是输入图像的通道数(RGB 为 3)
1 | |
创建一个卷积层,其核大小和步长等于块大小。这相当于将图像分割成块并对每个块进行线性变换。
1 | |
x是形状为[batch_size, channels, height, width]
1 | |
应用卷积层。
1 | |
获取形状。
1 | |
重新排列形状[patches, batch_size, d_model]
1 | |
返回补丁嵌入。
1 | |
添加参数化位置编码,
这会将学习到的位置嵌入添加到补丁嵌入中。
1 | |
d_model是 transformer 嵌入的大小max_len是最大补丁数
1 | |
1 | |
每个位置的位置嵌入
1 | |
x是形状为[patches, batch_size, d_model]
1 | |
获取给定补丁的位置嵌入
1 | |
添加到补丁嵌入并返回
1 | |
MLP 分类主管
这是基于标记嵌入对图像进行分类的两层 MLP 头 。
1 | |
d_model是 transformer 嵌入大小n_hidden是隐藏层的大小n_classes是分类任务中的类别数
1 | |
1 | |
第一层
1 | |
激活
1 | |
第二层
1 | |
x 是token 的 transformer 编码。
1 | |
第一层和激活。
1 | |
第二层
1 | |
1 | |
VisionTransformer 这结合了补丁嵌入、位置嵌入、Transformer和分类头。
1 | |
transformer_layer是单个Transformer层的副本。复制它以制作Transformer 。n_layersn_layers是Transformer层的数量。patch_emb是补丁嵌入层。pos_emb是位置嵌入层。classification是分类主管。
1 | |
1 | |
补丁嵌入
1 | |
分类头
1 | |
复制transformer
1 | |
标记嵌入
1 | |
最终规范化层
1 | |
x是形状为[batch_size, channels, height, width]
1 | |
获取补丁嵌入。这给出了形状为[patches, batch_size, d_model]
1 | |
在输入转换器之前连接 token嵌入
1 | |
添加位置嵌入
1 | |
无需注意掩蔽即可通过 Transformer 层
1 | |
获取令牌的转换器输出 (序列中的第一个)
1 | |
层规范化
1 | |
分类头,得到logits
1 | |
1 | |