0-Why Should I Trust You Explaining the Predictions of Any Classifier
“Why Should I Trust You”Explaining the Predictions of Any Classifier

LIME 这篇论文发表在2016年的KDD会议上
背景
机器模型虽然被广泛采用,但是其对人们来说,还是一个黑匣子。然而,了解机器学习背后的原理对于其评估非常重要,因此一种称为“LIME(Local Interpretable Model-agnostic Explanations)”的技术被提出,通过可解释和忠实的方式解释任何分类器的预测,以非冗余的方式呈现代表性的个体预测及其解释。人类对模型行为的理解程度,而不是将其视为黑匣子。
当模型用于决策时,确定对个人预测的信任是很重要的,例如,当使用机器学习进行医疗诊断、恐怖主义检测时,如果盲目的相信预测,可能会带来灾难性的后果。
实验方法
LIME 是一种模型无关的方法,可以解释任何机器学习模型的预测结果。它的基本思路是通过扰动输入数据并观察模型输出的变化,来构建一个局部线性模型,从而解释模型在某个特定数据点附近的行为。LIME 的具体步骤如下:
- 扰动输入数据:生成与原始数据点相似的一组扰动数据。
- 模型预测:使用原始模型对这些扰动数据进行预测。
- 加权线性回归:根据扰动数据与原始数据点的相似度,对扰动数据的预测结果进行加权线性回归,从而得到一个局部的线性模型。
- 解释结果:利用线性模型的系数解释原始模型的预测。
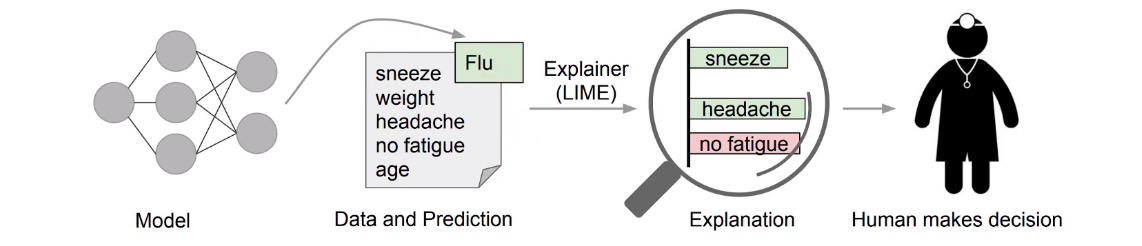
LIME的主要流程,通过对数据对可能的症状进行高亮标记,通过这个模型就会对于结果有可信的预测。
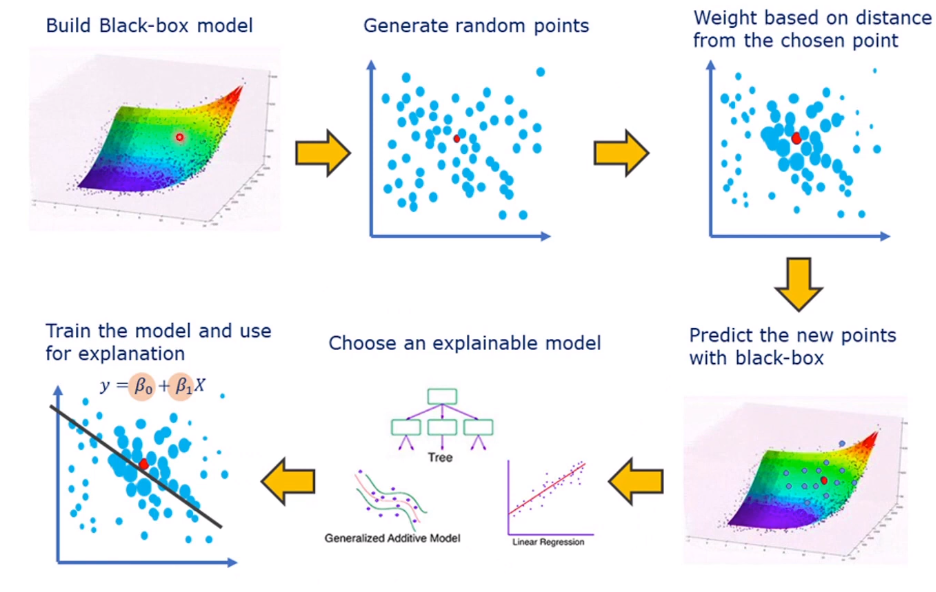
在模型中选取需要预测的点,对其周围的点按照weight进行标记,然后将weight大的点放入模型中重新标记,选择一个解释模型来表示原来的模型,也就是在用一个可解释的新模型代替不可解释的原模型。
假设有一个训练好的图像分类模型,可以将医学图像分类为正常或异常。使用LIME来解释模型对某个具体图像的预测:
- 输入扰动:对该医学图像进行小幅度扰动,如改变某些像素值或添加噪声,生成一组相似的图像。
- 模型预测:使用原始模型对这些扰动图像进行预测,记录每个扰动图像的预测结果。
- 加权回归:根据扰动图像与原始图像的相似度,对这些扰动图像的预测结果进行加权线性回归,构建局部线性模型。
- 解释结果:分析线性模型的系数,解释哪些像素或图像区域对原始模型的预测影响最大,从而理解模型是如何做出预测的。
实验结果
论文在多个数据集上进行了实验,包括文本分类和图像分类。实验结果表明,LIME能够有效地解释复杂模型的预测结果,并且在保持高解释性的同时,对原始模型的预测结果有较高的近似度。
总结
通过这种方法,可以更好地理解深度学习模型在医学图像处理中的决策过程,提升模型的透明度和可信度。
事实上还有一种方法SHAP(SHapley Additive exPlanations)是一种基于合作博弈论的解释方法,用于解释机器学习模型的预测结果。SHAP 结合了Shapley值的理论基础和加性特征重要性的思想,是目前广泛应用的一种解释工具。相比于 LIME,SHAP 更加严格和全面,但计算复杂度也较高。在实际应用中,SHAP 被广泛用于解释各种机器学习和深度学习模型的预测结果,提升模型的可解释性和透明度。在本文中不再介绍。