0-HyKGE AHypothesis Knowledge Graph Enhanced Framework
HyKGE:利用知识图谱增强大语言模型在医学领域提升准确度

arXiv:2312.15883v2 2024年4月19日(v2)
背景
LLM增强的知识图谱问答:是指结合大型语言模型(LLM)和知识图谱(KG)来改进和增强问答系统的能力。通过利用LLM的自然语言处理和生成能力,结合知识图谱的结构化数据。通过结合LLM和KG,问答系统可以处理更复杂和多样化的问题,同时提供更高质量和更可信的回答。这种增强方法有助于突破传统问答系统的限制,提升用户体验和满意度。
大型语言模型(LLM):基于深度学习技术训练的模型,能够理解和生成自然语言文本。擅长处理各种自然语言任务,如文本生成、翻译、总结和问答等。例如,GPT-4、文心一言等。
知识图谱(KG):一种以图形结构表示知识的数据库,节点表示实体(如人物、地点、事件等),边表示实体之间的关系。提供结构化和关联的数据,可以用于回答具体问题和提供事实信息。
知识问答系统(QA System):一个能够接受自然语言问题并生成答案的系统。通常包括问题理解、信息检索和答案生成三个主要步骤。
检索增强生成(RAG):通过检索外部信息来增强内容生成,减少知识密集型任务中的事实错误。RAG 被认为是一种有前途的解决方案,可以解决错误答案、幻觉和解释不足的问题。
Retrieval-Augmented Generation(检索增强生成):通过提示工程将外部知识检索组件纳入其中,以实现更符合事实的一致性,提高可靠性和 LLM 响应的可解释性,但在获取高精度方面仍然遇到困难用于训练查询文档对检索器的优质数据集,或用户查询中的信息有限,削弱了普遍性。
Knowledge Graph Query-Answer (知识图谱问答): 知识知识图谱具有结构化和可推断的优势,相比知识存储在文档库中。但是如何从 KG 中获取知识,以及如何设计LLM 与 KG 之间的交互策略仍处于探索阶段。 目前的解决办法是语义解析方法:允许LLM 将问题转换为结构化查询(例如 SPARQL),可以由查询引擎执行来得出答案。
所面临的挑战:
- 避免事实错误(如幻觉和有限解释性)
- 数据约束(如资源限制、高训练成本和隐私问题)
- 灾难性遗忘
- 知识过时
- 处理特定领域或高度专业化查询的专业知识不足
解决方案:
- 将用户不一致的非结构化查询与高质量的结构化知识图谱对接,存在显著挑战。
- 提出了一种假设知识图谱增强(HyKGE)框架,利用 LLMs 强大的推理能力来补偿用户查询的不完整性,优化与 LLMs 的交互过程,并提供多样化的检索知识。
HyKGE在预检索过程中使用图推理链纠正模型错误,并在后检索中应用细粒度对齐来保持有效、多样的知识,在没有微调或过度交互的情况下高效地增强检索。
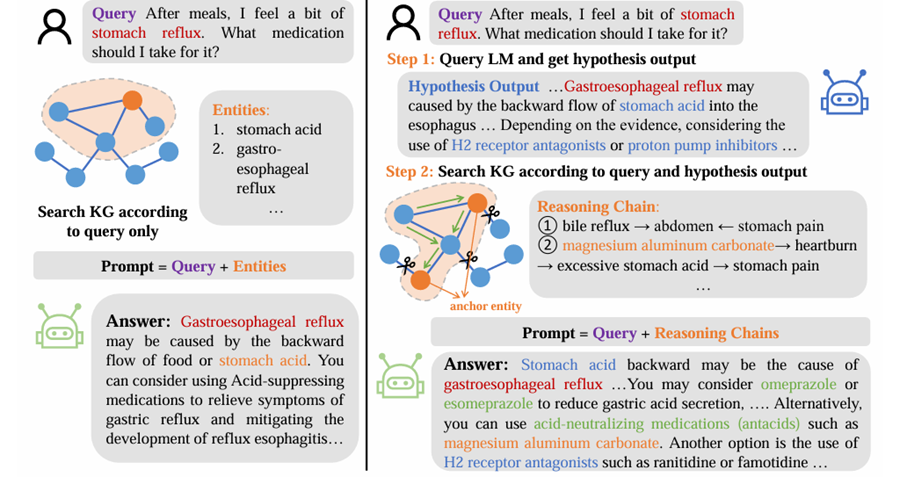
KGRAG(左)。基本 KGRAG 从用户查询中提取关键实体,并在其中搜索相应实体 KG,然后与查询一起输入到 LLM 中。询问饭后,我感觉有点胃反流。用什么药? 仅根据查询条件搜索KG 提示 =查询+实体 答案:胃食管反流 可能是由于落后 食物或胃酸的流动。您 可以考虑使用抑酸 缓解症状的药物 胃反流和减轻 反流性食管炎的发展⋯⋯
HyKGE(右)。HyKGE 首先查询 LLM 以获得假设 输出并从假设输出和查询中提取实体。然后 HyKGE 检索 任意两个锚实体,并将推理链与查询一起输入到 LLM问题吃完饭后,感觉有点胃痛 胃食管反流。我应该服用什么药物治疗? 假设输出⋯⋯胃食管反流可能是由于胃酸反流到食管引起的⋯⋯根据 证据,考虑使用H2 受体拮抗剂或质子泵抑制剂⋯⋯ 推理链: ①胆汁反流→腹部←胃痛 ②碳酸铝镁→胃灼热→胃酸过多→胃痛 锚实体 提示=查询+推理链 回答:胃酸倒流可能是导致 胃食管反流⋯⋯你可以考虑奥美拉唑或 埃索美拉唑减少胃酸分泌,⋯⋯或者, 您可以使用酸中和药物(抗酸药),例如 碳酸镁铝。另一种选择是使用 ⋯ H2 受体拮抗剂,如雷尼替丁或法莫替丁⋯ 中。
实验步骤
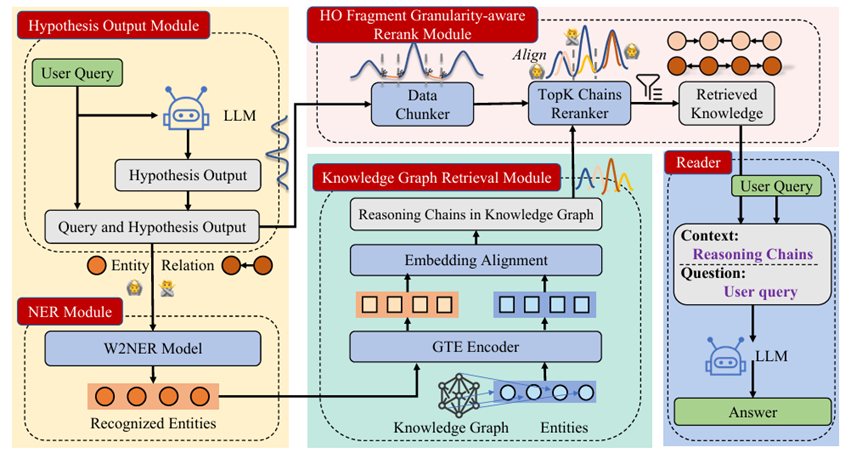
HyKGE 的整体框架。HyKGE 首先将用户查询(Q)输入到 LLM 中,得到假设输出(H ·O)。然后通过 NER 模块,应用 W2NER 模型识别实体并分离关系。然后通过 GTE 编码器将这 些识别出的实体与知识图谱中的实体链接起来。之后,HyKGE 从知识图谱中提取出相关推理链。然后,由于Q 的稀疏性,在 HO 片段粒度感知重排序模块中, HyKGE 将Q和HO进行分 块,并通过 TopK 链重排序器与推理链对齐,以消除不相关的知识。最后,根据用户查询来组织检索到的知识,并通过 LLM Reader 获取答案。
预检索阶段:包括假设输出模块和NER模块。HOM利用LLM通过探索可能的答案来获得假设输出。然后NER模块提取来自假设输出模块的医疗实体和用户查询。
NER(医学命名实体识别)模块:为了解决模型可能出现的幻觉或医学实体之间的误解,作者提取实体而不是关系,并使用KG中完全无误的三元组进行真实性验证,而不是在HO中分析的关系,使用 CMEEE(中文医学命名实体识别数据集)数据训练了一个医学命名实体识别(NER) 模型。
知识图谱上的检索:利用提取的实体作为锚点搜索不同类型的推理链,这些推理链将这些锚点相互连接起来,提供相关且合乎逻辑的知识。
此过程涉及使用编码模型对潜在实体和KG中的实体进行编码,使用GTE嵌入模型,这是目前在检索领域中文本向量嵌入表现最好的模型。GTE 编码器遵循两阶段训练过程最初使用来自文本对的弱监督大规模数据集,然后使用对比 学习对高质量手动标记数据进行微调。计算和的嵌入之间的内积相似度,相似度最高的实体视为匹配。
选择匹配的实体,使用实体之间的推理链,原因如下:
- 推理链为 LLM 提供了更丰富的逻辑知识以帮助其消化。
- 推理链帮助 LLM 阅读器理解 不同实体之间的关系,从而减轻幻觉和错误问题。
- 推理链充当有效的修剪机制,比 子图更有效地过滤噪音并节省资源。
后检索阶段:
采用 HO 片段粒度感知重排序方法。首先,假设输出和用户查询被分割成离散片段,随后,根据片段对检索到的推理链进行重排序。
传统的重新排序仅基于Q上的学习可能会过滤掉通过HOM获得的有价值的知识,从而导致重复和单调的情况。作者创新性地将HO和Q 结合起来,而不是仅仅依赖用户查询,利用其中包含的更丰富的医学知识。
LLM阅读器:
接收用户查询和修剪后的检索到的推理链,并通过精心设计的提示进行组织。


实验结果
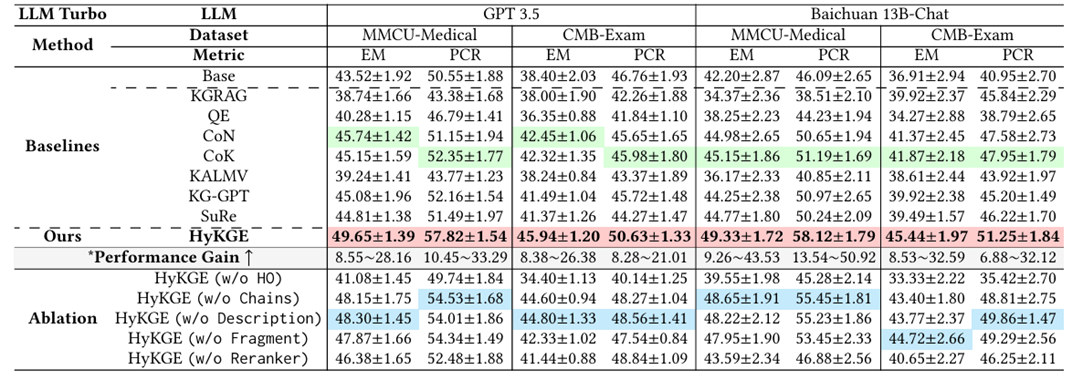
红色阴影表示表现最佳的模型,蓝色表示消融研究中第二好的模型,绿色表示基线排名第二。
总结
本文介绍了HyKGE框架,旨在提高医学领域大型语言模型(LLMs)在回答问题时的准确性和可靠性。该框架利用知识图谱增强了LLMs的推理能力,通过识别实体、关系和知识图谱的嵌入对用户查询进行处理,并从知识图谱中提取相关的推理链。在处理查询和假设输出时,HyKGE采用了分段处理和重新排序的方法,以消除无关知识并提供更精确的答案。该框架的设计使得LLMs能够更好地理解和回答医学领域的复杂问题,提高了在实际应用中的性能表现。
未来发展:
- 动态优化片段粒度:在后检索阶段,可以探索如何动态优化片段粒度,以进一步提高知识的密度和效率。
- 探索更多语言或领域特定的知识图谱:尽管存在数据源的限制和LLMs的高计算成本,但未来可以在更多其他语言或领域特定的知识图谱上进行实验,以增强HyKGE框架的可扩展性和泛化性能。
- 持续的实验和优化:未来可以继续尝试不同的策略,并对HyKGE框架进行进一步优化,以不断提升其性能和效果。