0-Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Dropout: A Simple Way to Prevent Neural Networks from Overfitting

Journal of Machine Learning Research 15 (2014)
背景
“Improving neural networks by preventing co-adaptation of feature detectors”这篇文章与本文有很大的关联,实际上,前者可以被认为是后者的早期工作或相关研究,前者讨论了防止特征检测器协同适应(co-adaptation)的方法,这就是Dropout技术的核心思想,本文是作者在同一年稍晚时候发表的进一步研究成果,更详细地描述了Dropout技术并提供了更多实验结果。
实验过程
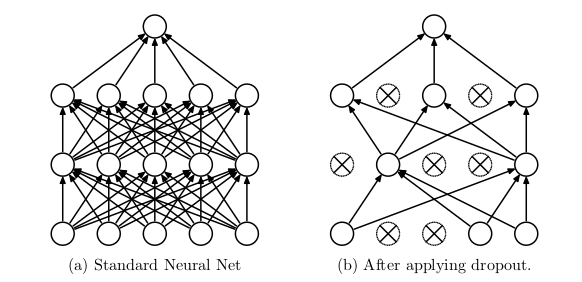
左边是训练集神经元,右边是测试集神经元。左边训练集的神经元以P概率被保留。右边测试集不做丢弃,但参数乘以p。 这⾥的意义就是保证训练集和测试集 的输出期望⼀致。
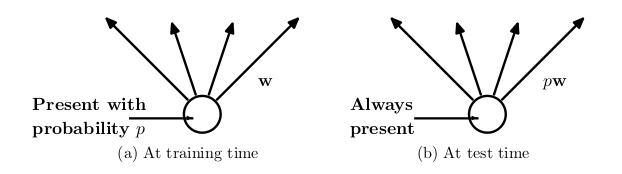
也就是Dropout说数目要在相应的分母中减去,以保证结果不会偏差。
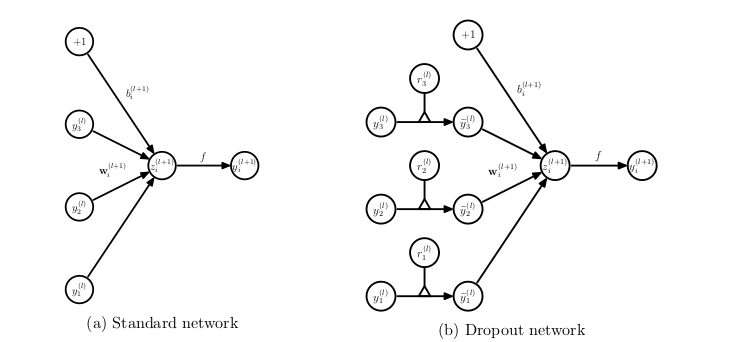
Dropout神经网络模型描述。Dropout通过减少神经元之间的相互依赖,迫使网络学习到更加鲁棒的特征。这不仅有效防止了过拟合,还可以看作是对多个不同结构网络的集成,提升了模型的泛化能力。
深入研究:

其中,图(a)是没有Dropout的神经网络提取的特征,图(b)是丢失率 p=0.5 时的带Dropout的神经网络提取的特征。由上图可知,Dropout破坏了隐藏层单元之间的协同适应性,使得带Dropout的神经网络提取的特征更明确,增加了模型的泛化能力。
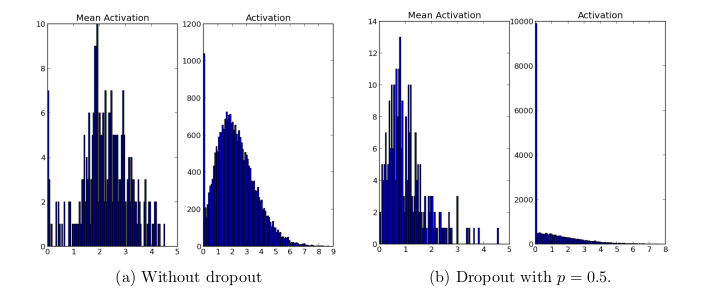
其中,图(a)是没有Dropout的神经网络提取的特征,图(b)是丢失率 p=0.5 时的带Dropout的神经网络提取的特征。由上图可知,Dropout使得网络中只有极少数单位具有较高的激活能力。
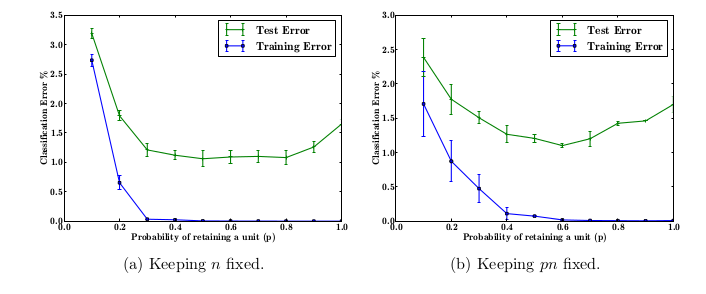
其中,图(a)是第一种情况,在第一种情况下,使用不同数量的辍学来训练相同的网络架构。网络结构为784-2048-2048-2048-10。没有在输入时使用Dropout。由图可知,随着p的增加,测试误差先降后升,在 p∈[0.4,0.8] 时效果最好。 图(b)是第二种情况,此时 pn 保持不变,因此p越大,n越小,反之亦然。由该图可知,随着p的增加,测试误差先降后升,在 p=0.6 时效果最好。
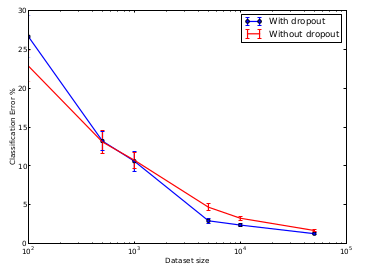
其中,实验从MNIST训练集中随机选取100、500、1K、5K、10K和50K的数据集。所有数据集的网络结构皆为784-1024-1024-2048-10。Dropout的丢失率为0.5。由上图可知,在小数据集(100,500)上,Dropout并没有改善性能,数据量变大时,Dropout就有了明显的改善网络的效果,但数据量过大是Dropout对网络的改进并不明显。
实验结果
所用的数据集有:
- MNIST:一组手写体数字的标准数据集。
- Timit:用于语音清洗识别的标准语音基准。
- CIAR-10和CIFAR-100:微小的自然图像。
- 街景房屋编号数据集(Street View House Numbers data set,SVHN):谷歌街景收集的房屋号码图片。
- ImageNet:大量自然图像的集合。
- Reuters-RCV1:路透社新闻报道集。
- 替代剪接数据集(Alternative Splicing data set):预测替代基因剪接的RNA特征。
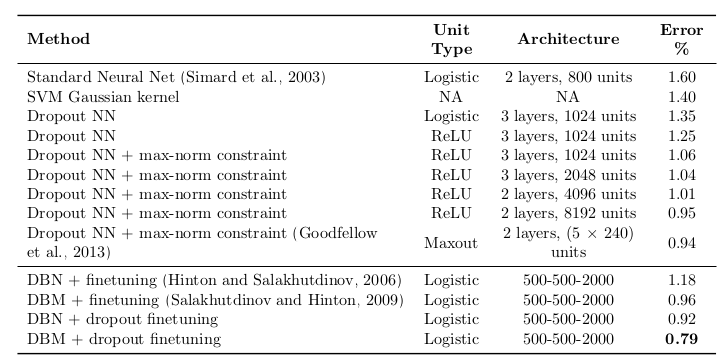

可以看出都有不错的结果,其他数据集的结果不在次赘述。
总结
“Improving neural networks by preventing co-adaptation of feature detectors”提出了防止神经网络中过拟合的基本思想,而“Dropout: A Simple Way to Prevent Neural Networks from Overfitting”详细描述并验证了这一思想,形成了Dropout技术。两篇论文共同推进了深度学习领域的发展,为后续研究和应用奠定了基础。Dropout的基本思想是,在每次训练迭代中,随机忽略(“丢弃”)网络中的一些神经元,包括它们的连接。具体做法是在前向传播时,以一定的概率p将某些神经元的输出设为零,而在反向传播时只对剩下的神经元进行权重更新。这篇论文的主要贡献在于提供了一种简单而有效的防止过拟合的方法,极大地推动了神经网络的发展和应用。