0-Decoupled Neural Interfaces using Synthetic Gradients
Decoupled Neural Interfaces using Synthetic

使用合成梯度的解耦神经接口arXiv:1608.05343v2 ICML2016
背景
训练神经网络需要数据通过前向传播,随后反向传播误差来更新权重,在这个过程中,网络和模块各层之间的相互依赖,需要等待其他层的计算完成才能完成更新,导致效率低下。本文的作者使用建模误差梯度,通过使用建模用合成梯度代替真正的反向传播误差梯度,将子图解耦,并且可以独立和异步地更新它们,即实现了解耦的神经接口。
本文的核心创新在于使用合成梯度。合成梯度使用局部信息进行预测,而不是等待从误差中计算出的真实梯度。这些合成梯度允许网络的不同部分独立且异步地进行更新。从而在前向和后向解耦的模型
和向后传递 相当于独立网络共同学习,这样它们就可以组成一个单一运作的模块。
实验方法
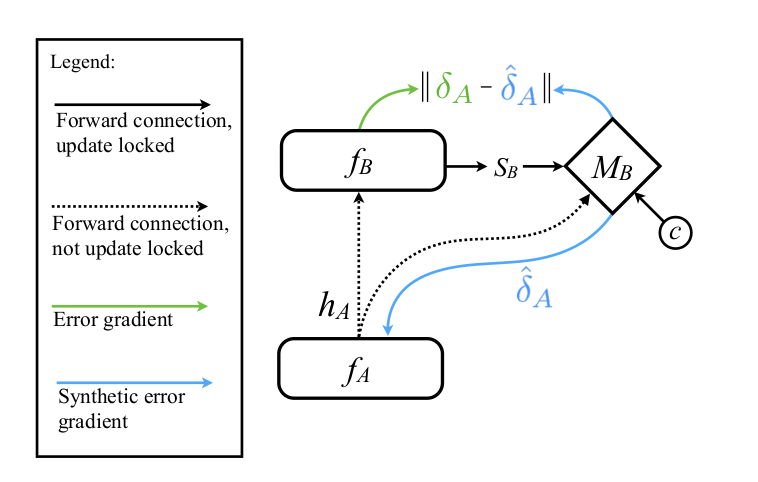
图中$M_B$是DNI网络,相当于使用自建的模型来预测梯度。输入的是某一层的输出,输出的就是该层对应的梯度,这样就解除了更新锁和反向锁,优化了梯度的计算时间。
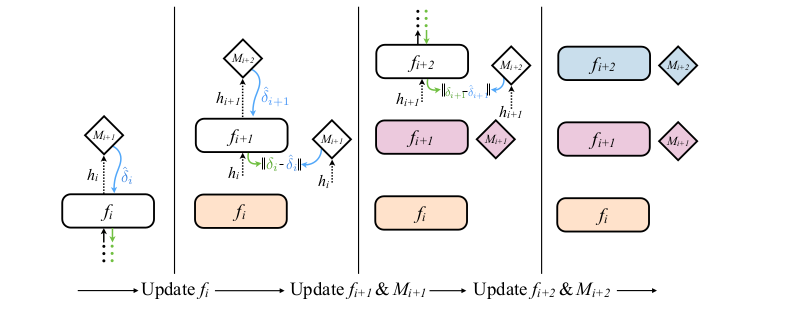
传统的反向传播(Backpropagation, BP)算法,是先计算出最后一层的残差,然后用最后一层的残差去计算倒数第二层的残差,依次类推,如果在训练模型 M 时依然遵照这个流程,毫无疑问 Update Locking 和 Backward Locking 依然存在,所以作者在计算每一层的“实际残差”时,用的是后一层的“合成残差”,而合成残差的计算是可以立即计算的,这样近似出的结果去评估模型中的残差估计值,如下图所示:
再进一步地,作者表示,利用 DNI 的思想,去预测每一层的输入也是可以的,这样就把 Forward Locking 也去掉了。基本思想和合成梯度是一样的,不同之处在于预测每一层的输入时只用到第一层也就是输入层的输入
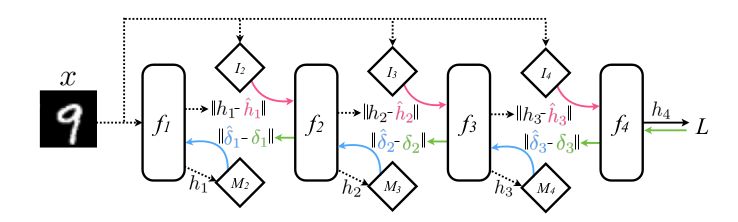
这样 Forward Locking、Update Locking 和 Backward Locking 都被去掉了,通过适当的设计,整个训练可以被很好地并行化、异步化了。
DNI 的思想除了用在前馈神经网络上,也可以用于循环神经网络(Recurrent Neural Network, RNN)的训练上面,因为 RNN 在时间维度上展开后,其实就相当于是一个前馈神经网络了。而且由于应用 DNI 的模型,最多只有两层的网络层依赖,那么在用于 RNN 训练时,可以不用将 RNN 完全展开,而是可以以两个 time step 为最小单元进行展开,即一次只展开两个 time step,这样在存储上的消耗也可以被降低。
实验结果
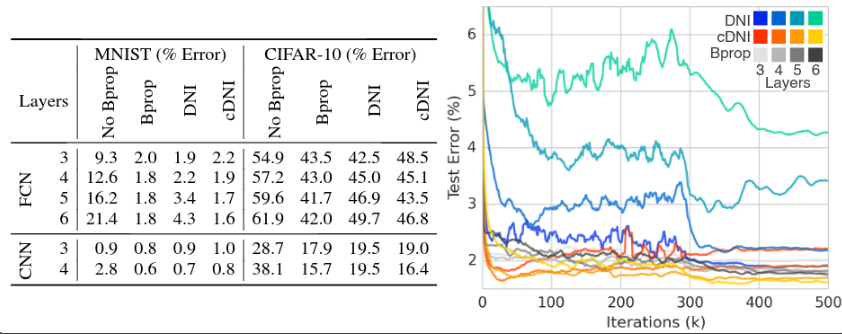
实验表明使用 DNI 模型能够被训练 。
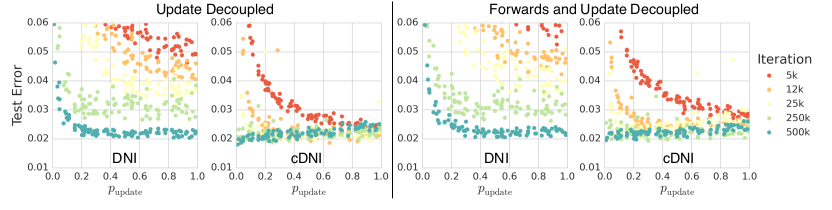
左:对一个四层的前馈网络,以随机的顺序来更新每一层,并且每一层在被选中都是有概率的。在这样的情况下,模型依然是可以被训练的。不过明显能看出来,概率值越大,收敛是越快的。
右:加上了 synthetic inputs ,也就是把 Forward Locking 去掉了,从结果上来看,和第上一个实验差不多。

最后在 RNN 上进行了三个实验,分别是:
- Copy: 读入 N 个字符,然后将这 N 个字符原样输出,有点类似 char-level language model 和 autoencoder。
- Repeat Copy: 读入 N 个字符,以及一个表示重复次数的数字 R,然后重复输出 R 次这 N 个字符构成的序列。
- char-level language modeling: (持续地)读取一个字符,并预测下一个字符。
总结
本文提出了一种使用合成梯度来加速神经网络训练的新方法,通过解耦网络层或模块之间的依赖性,提高训练效率。异步训练:网络层或模块可以独立训练,提高了训练效率。扩展时间依赖性:特别是对于RNN,这种方法有助于更有效地建模长期依赖性。灵活的网络结构:该技术可以应用于各种网络架构,不仅限于标准的前馈或循环网络。这种方法通过打破传统的训练过程中的层依赖性,显著提高了神经网络训练的效率和可扩展性。