0-Net2Net: Accelerating Learning Via Knowledge Transfer
Net2Net: Accelerating Learning Via Knowledge Transfer

ICLR 2016
背景
大型的深度神经网络的训练通常需要大量的计算资源和时间。随着模型需求增加(更深和更宽的网络),训练时间和资源也随之增加。于是作者给出了一种通过迁移学习来加速训练的方法。
传统的机器学习算法是接受一个固定的数据集作为输入,在不接受任何知识情况下初始化,并训练模型至收敛。但实际应用场景中,数据集往往是不断增长的,为避免过拟合和降低模型计算成本,一开始会选择小模型,之后需要一个大模型以充分利用大型数据集。而重新训练一个大的神经网络十分耗时,通过实验证明使用Net2Net操作初始化的模型比标准模型收敛得更快。
实验方法
Net2Net 包括两个主要的变换方法:Net2WiderNet 和 Net2DeeperNet。
1.Net2WiderNet
Net2WiderNet 的目标是将现有神经网络的层变宽,即增加每层的神经元数量,同时保持网络的功能不变。
操作步骤:
- 权重矩阵扩展:
- 给定一个原始层的权重矩阵 $W$(维度为 $m \times n$,其中 $m$ 是输入神经元数量,$n$ 是输出神经元数量)。
- 生成一个新的更宽的权重矩阵 $W’$(维度为 $m \times n’$,其中 $n’ > n$)。
- 权重复制与扰动:
- 将原始的 $W$ 中的每一列复制到 $W’$ 的多列上。
- 对复制的列施加微小的随机扰动,确保新的输出节点不会完全相同,这样可以避免梯度消失或爆炸问题。
数学表示:
假设原始的权重矩阵 $W$ 为:
$W=[w_1,w_2,…,w_n]$
新的权重矩阵 $W’$ 通过复制和扰动生成:
$W’=[w_1,w_1,w_2,w_2,…,w_n,w_n]+ϵ$
其中 $\epsilon$ 是一个微小的随机扰动矩阵。
偏置项扩展:类似地,对应的偏置项向量 $b$ 也进行扩展和复制。
目的:
- 通过适当的权重复制和调整,新网络的输出可以保持与原始网络相同。
- 新的宽网络已经包含了原始网络的知识,无需从头开始训练,只需进行微调。
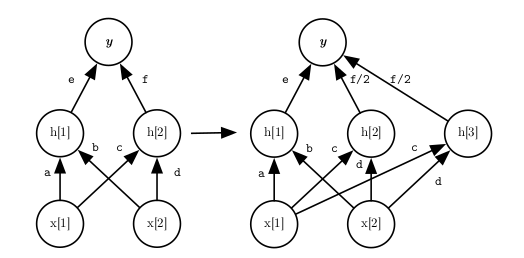
2. Net2DeeperNet
Net2DeeperNet 的目标是增加网络的深度,即在现有网络中增加新的层,同时保持网络的功能不变。
操作步骤:
- 增加新层:
- 在现有网络的某一层后增加一个新的层(可以是卷积层、全连接层等)。
- 恒等变换初始化:
- 将新层的权重初始化为恒等变换,这样新层在初始时不会改变输入的数据。
- 对于全连接层,使用单位矩阵进行初始化: $W=I$
- 对于卷积层,使用类似单位矩阵的滤波器进行初始化,即在中心位置设置为1,其余位置为0。
数学表示:
假设在现有网络的某一层 $h = f(x)$ 后增加一个新层 $g$,新的网络输出应为: $h’=g(f(x))$
初始化新层 $g$ 的权重使其为恒等变换: $g(h)=h$
具体实现中,对于全连接层 $W = I$,卷积层使用 $\delta$ 函数作为滤波器。
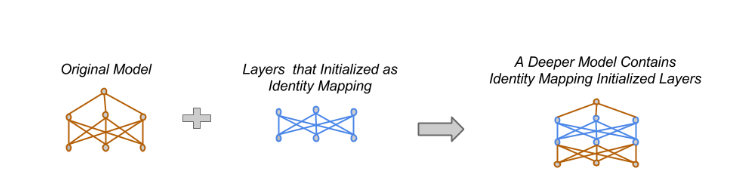
目的:
- 新层在初始化时等效于一个恒等映射,不会改变网络的输出。
- 通过对新层的微调,可以逐渐引入新的表示能力,而不影响原有网络的性能。
实验结果
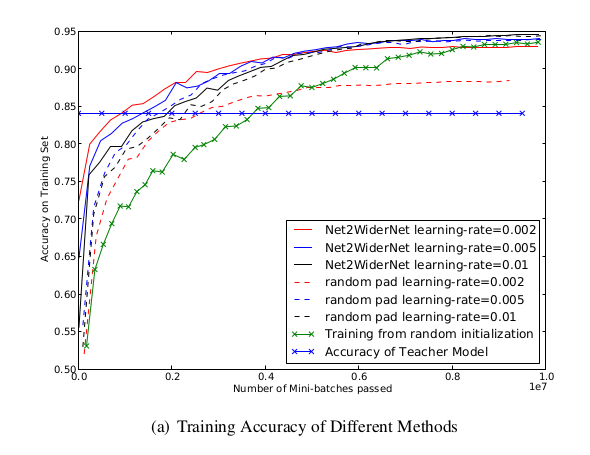
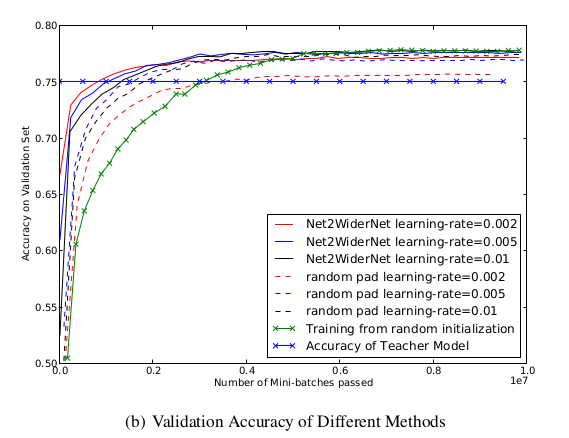
Net2Net 算法在多个数据集和不同模型上进行了验证,结果表明:
- Net2WiderNet 和 Net2DeeperNet 能够显著加速模型的训练时间。
- 在扩展后的网络上,训练后的验证准确率与直接从头训练的模型相当,甚至更高。
- Net2Net 方法在保持原有网络性能的前提下,有效地增加了网络的容量和复杂性。
论文的主要贡献为:
提出保留功能的初始化策略,有如下优点:
- 新的大网络和原来的性能一样,不花费时间在之前低性能时期训练;
- 保证在初始化后的任何更改都是改进的,之前的方法可能无法在baseline上改进,因为对较大模型初始化后的更改恶化了性能
- 对网络中所有参数的优化都是“安全的”,从来没有哪个阶段某一层会接收到有害的梯度、需要冻结。这与级联相关(cascade correlation)等方法形成对比,后者将冻结旧单元,以避免在试图影响新的随机连接单元的行为时产生不良的适应性。
提出Net2Net方法,在现有模型基础上加速新模型训练
应用于终身学习系统:
真实场景下的机器学习系统,最终都会变成终身学习系统(Lifelong learning system),不断的有新数据,通过新的数据改善模型,刚开始数据量小,我们使用小的网络,可以防止过拟合并加快训练速度,但是随着数据量的增大,小网络就不足以完成复杂的问题了,这个时候我们就需要在小网络上进行扩展变成一个大网络了。
Net2Net操作使我们能够顺利地实例化一个大得多的模型,并立即开始在我们的终身学习系统中使用它,而不需要花费数周或数月的时间在最新的、最大版本的训练集上从头开始重新训练一个大模型。
结论
Net2Net 提供了一种简单而有效的方法,通过知识转移加速神经网络的训练过程。该方法能够帮助研究人员和工程师快速构建和训练更大规模的神经网络,减少计算资源和时间的消耗。Net2Net 算法具有广泛的应用前景,尤其是在需要频繁扩展和调整模型结构的深度学习研究和应用中。