0-SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings

SimCSE:对比学习句向量表示 发布于EMNLP 2021
背景
Embedding是指将高维度的数据(例如文字、图片、音频)映射到低维度空间的过程。Embedding向量是包含语义信息的。也就是含义相近的单词,Embedding向量在空间中有相似的位置。Embedding是数据科学工具包中至关重要的部分,已经广泛应用于各种不同领域的生产级机器学习系统,包括自然语言处理、推荐系统和计算机视觉等
Dropout:Dropout是一种用于减少神经网络过拟合的正则化技术。在训练过程中,dropout会随机地将神经元的输出置为零,这样可以防止网络对特定的输入特征过度依赖,从而提高了模型的泛化能力。在SimCSE中,dropout被用作一种噪声注入的手段,用于生成不同的句子表示,从而帮助模型学习更加鲁棒和具有表征能力的句子嵌入。
**Simple Contrastive Learning of Sentence Embeddings(SimCSE)**:一种简单的对比学习框架,用于学习句子表示。SimCSE提出了无监督和监督两种方法来学习句子表示。在无监督方法中,SimCSE利用对比学习的方式,通过预测输入句子本身来学习句子表示。而在监督方法中,SimCSE利用自然语言推理数据集中的标注句对来训练模型,以进一步提高句子表示的性能。SimCSE的方法简单而高效,在语义文本相似性任务上取得了令人满意的性能表现。
SimCSE这个对比学习框架,它可以通过预测输入句子本身来学习句子表示。例如,对于输入句子”The cat is sleeping on the mat.”,SimCSE会使用标准的dropout噪声来生成两个不同的嵌入向量,然后将其他句子作为“负样本”,并让模型预测哪个嵌入向量是“正样本”。这个过程可以在无标注数据上进行,因此是一种无监督的方法。SimCSE的监督方法则利用自然语言推理数据集中的标注句对来训练模型。例如,对于一个标注句对”The cat is sleeping on the mat.”和”The feline is resting on the mat.”,SimCSE会将它们的嵌入向量作为“正样本”,并将其他句子的嵌入向量作为“负样本”,从而训练模型。
对比学习:对比学习的两个优化目标:
1.正例之间表示保持较近的距离;
2.随机样例的表示应分散在超平面上。并且这两个目标分别可以用指标alignment和uniformity来衡量。
样本对数据 D ,X_i和X_i^+是一对相似样本对。训练目标函数为
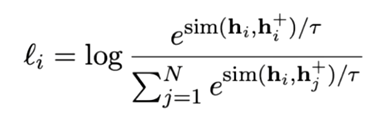
正样本:构造(X_i,X_i^+)样本对。在CV领域可通过裁剪、翻转等方法很容易构建,在NLP领域则很难构造语义一致的样本。比较常见的是通过数据增强来构造,如同义词的替换,删除某个或某些不重要的词等,但这些方法很容易引入噪声,致使模型的效果提升有限。
alignment和uniformity:alignment是正样本 (x_i,x_i^+)的平均距离. (对齐性)越小越好
uniformity计算向量整体分布的均匀程度,越均匀,保留的信息越多。 (均匀性) 越小越好
实验方法
无监督SimCSE:
无监督SimCSE的工作原理,它使用对比学习的方法,通过预测输入句子本身来学习句子表示。使用不同的隐藏层dropout掩码来生成不同的句子表示,并将它们与同一批次中的其他句子表示进行比较,以学习更好的句子表示。
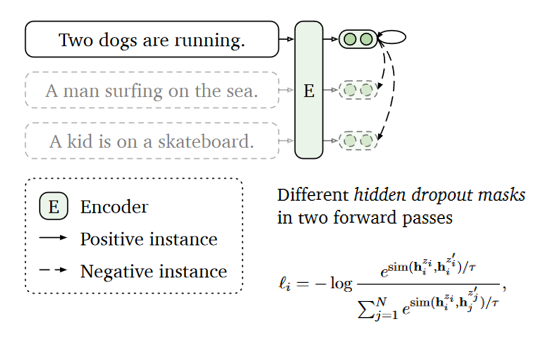
一般来说,我们会使用一些数据扩增手段,让正例的两个样本有所差异,但是在 NLP 中如何做数据扩增本身也是一个问题,SimCSE 提出了一个极为简单优雅的方案:直接把 Dropout 当做数据扩增!
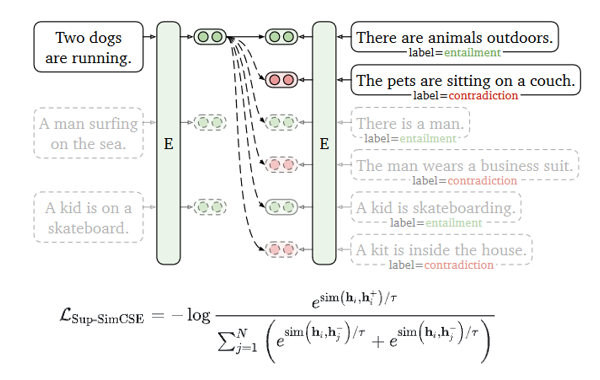
有监督SimCSE:
监督SimCSE的工作原理,它利用自然语言推理数据集(NLI数据集)中的标注句对来训练模型,以进一步提高句子表示的性能。使用自然语言推理数据,以学习更好的句子表示。
SimCSE的各向异性(Anisotropy):
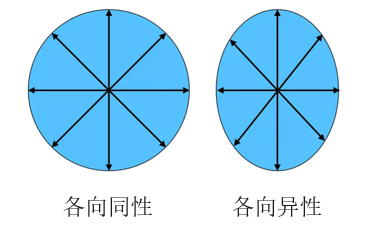
各向异性,又叫做表征退化问题,表示词嵌入在向量空间中占据了一个狭窄的圆锥体。与各向异性对应的是各向同性,指的是数据的分布在各个方向都一样,如图5。SimCSE论文中讨论的各向异性是和我们前面的均匀性类似的概念。目前缓解模型坍塌的策略消除主成分,加入正则项以及将各向异性映射为各向同性等等。SimCSE则证明了对比学习的训练目标可以降低模型的各向异性。
在SimCSE中,作者表明,对比目标还可以通过提高嵌入空间的均匀性来缓解各向异性问题。他们从奇异谱的角度证明了对比学习目标“平坦”了句子嵌入空间的奇异值分布,从而提高了一致性。这是通过将对比学习目标中的负面事例分开来实现的。因此,SimCSE为语言表征中的各向异性问题提供了一种新的解决方案。
对比学习能平缓奇异值的分布。
实验结果
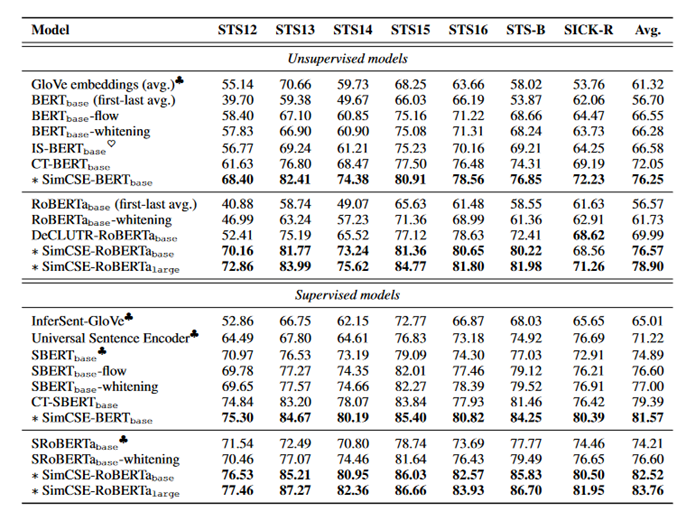
Sentence embedding performance on STS tasks
语义文本相似性
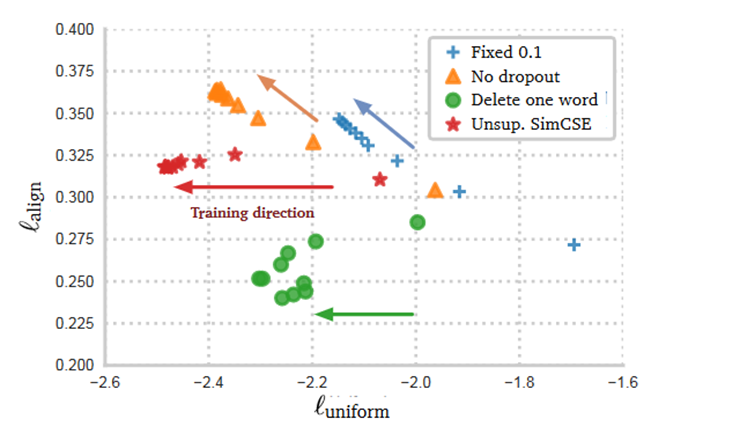
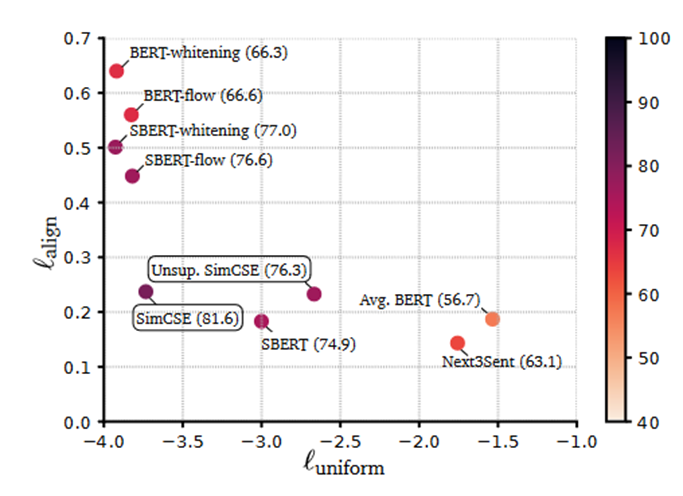
alignment和uniformity对比其他方法,可以看出SimCSE在alignment和uniformity两个方面均要好于BERT算法。
总结
SimCSE是一个原理并不复杂的算法,它提出了使用Dropout构建正样本对这个简单易行的方案,解决了模型预训练过程中容易出现的模型坍塌的问题。Sim-CSE非常简单但效果非常好,其背后的数学原理是引入深思的。SimCSE一文对对比学习之后的数学原理进行了深入的探讨。证明了对比学习的损失函数是具有同时优化对齐性和均匀性这两个方向的。