0-Knowledge Mining with Scene Text for Fine-Grained Recognition
Knowledge Mining with Scene Text for Fine-Grained Recognition

基于场景文字知识挖掘的细粒度图像识别算法 CVPR 2022
背景
场景文字的识别:和文档文本不同,场景文字具有稀疏性,通常以少许关键词的形式存在于自然环境中。通过稀疏的关键词,机器难以获取精准的语义。然而,人类能够较为充分地理解稀疏的场景文字。原因在于,人类具有大量的外部知识库,能够通过知识库来弥补稀疏的场景文字所带来的语义损失。

如图所示:
该数据集是关于细粒度图像分类任务,旨在区分图像中的瓶子属于哪种饮品或。图中 3 张图像均属于 soda 类饮品,尽管案例(c)同样属于 soda 类饮品,但是其附属的场景文本的表面信息无法提供明显的线索。场景文字在 百科 中的描述,百科 告知我们,场景文本 leninade 代表某种品牌,其属于 soda 类饮品。因此,挖掘场景文本背后丰富的语义信息能够进一步弥补场景文本的语义损失,从而更为准确地理解图像中的目标。
Fine-Grained Image Classification(细粒度图像分类):区分某些领域中物体类别之间具有细微视觉差异的图像。
1.仅使用视觉线索对对象进行分类,并旨在找到有区别的图像路径。
2.通过使用场景文本的视觉线索来利用场景文本进行细粒度图像分类任务。
3.利用场景文本的文本线索作为判别信号,并结合GoogLeNet获得的视觉特征来区分商业场所。
尽管取得了有希望的进展,但现有的方法利用了场景文本的字面意义,而忽略了有意义的人类的文本知识。
**Knowledge-aware Language Models(知识感知语言模型)**:预训练语言模型经过优化,可以预测给定序列中的下一个单词或一些屏蔽单词。这种知识通常是从预训练模型生成的潜在上下文表示中获得的,或者通过使用预训练模型的参数来初始化特定于任务的模型以进行进一步微调来获得。
在论文的方法中,采用 BERT 和 KnowBert 作为知识感知语言模型,并应用它们来提取知识特征。尽管以前的方法从视觉语言任务的句子中提取知识特征,但它们需要图像文本对的注释。
实验方法
算法框架:
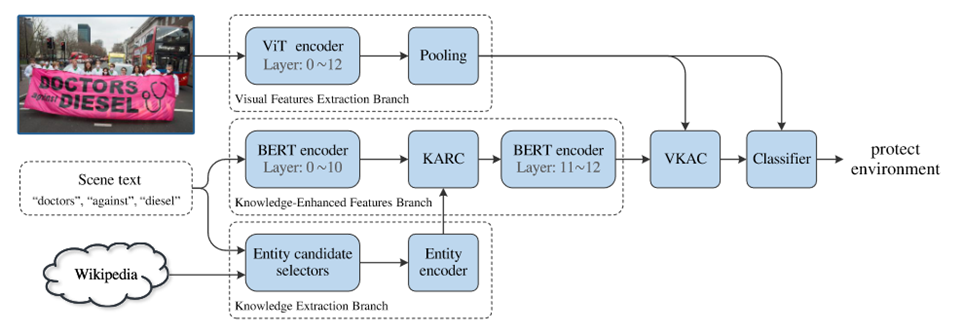
算法框架图,由视觉特征分支、知识提取分支和知识增强分支、视觉-知识注意力模块(VKAC)和分类器构成。
网络框架由视觉特征分支、知识提取分支和知识增强分支、视觉-知识注意力模块和分类器构成。算法输入包括 3 部分:图像,图像中包含的场景文本实例,外部知识库。其中场景文本实例通过已有的文字识别器从输入图像中获取,外部知识库采用了 Wikipedia。知识提取分支提取场景文本实例背后的语义信息(知识特征),知识增强分支融合场景文本实例和挖掘出的知识特征。随后,视觉-知识注意力模块融合视觉和知识特征,并将其输入给分类器进行分类。
知识提取分支:该分支由实体候选选择器和实体编码器构成。实体候选选择器预先在大量语料库上统计单词在所有可能实体上的概率分布,根据概率分布选取前 10 个候选实体,并将其输入给实体编码器进行特征编码。实体编码器在 Wikipedia 的数据库上进行预训练,预训练任务旨在通过 Wikipedia 上实体的描述来预测该页面的标题(实体名称)。
知识增强特征分支:该分支主要由 bert 构成,在 bert 的第 10 层后插入知识注意力模块(KARC),该模块融合了文本实例特征和知识特征后,接着输入给 bert 剩余的层。Bert 第 12 层输出的特征给 VKAC 模块。
视觉-知识注意力模块:并非所有的场景文本或知识对理解图像有积极作用,为选取和图像内容相关的场景文本和知识来加强对图像的理解。该模块以图像全局特征作为访问特征,从增强的知识特征中选取相关的知识特征来加强视觉特征。其网络结构由注意力模型构成。
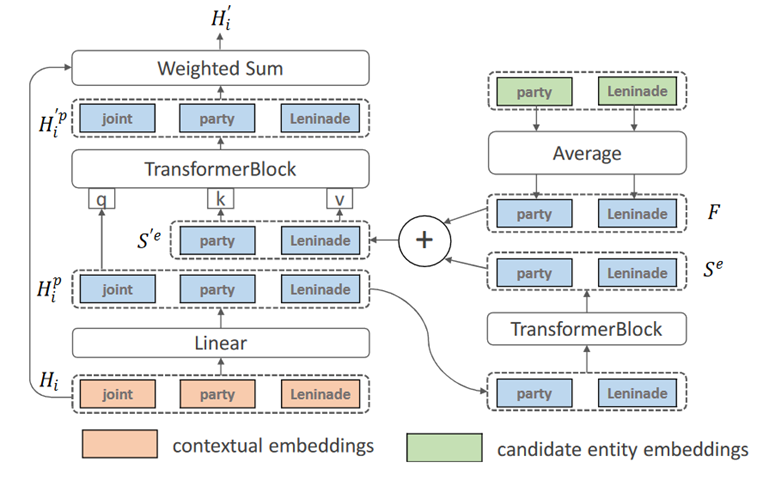
通过在BERT模型中的特定层(第十层)插入一个KARC(knowledge attention and recontextualization component)
•将一个单词序列输入到BERT中10层连续的编码层,得到语境 Hi
•将 Hi ,knowledge extraction得到的entity embedding输入到KARC中,输出知识增强的text representation Hi ’
•将 Hi ‘输入到BERT中剩余的编码层,并获得最终的知识增强的特征,输送给下一子模型(Visual-knowledge attention component )。
注意力机制:
主要目标:将注意力放在和场景内容有较强相关的文字上,忽略和场景关系不大的文字。
方法:提取全局的视觉特征,将视觉特征和提取到的知识特征做对比,选取相似度高的视觉特征(注意力机制)。
为研究场景文本背后的知识对图像识别的帮助,收集了一个关于人群活动的数据集。该数据集中的类别主要分为游行示威和日常人群密集活动两大类,细分为 21 类。

实验结果
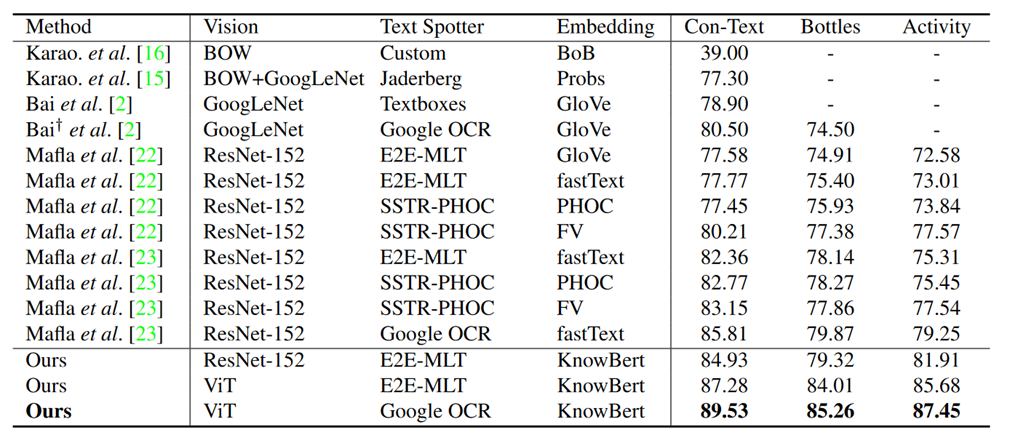
和 SOTA 对比:在公开数据集 Con-Text、Bottles 以及我们收集的 Activity 数据集上,在使用 resnet50[3]和 E2E-MLT[4]作为视觉特征提取器和文字提取器时,我们方法能在同等情况下取得最佳结果。当使用 ViT 和 Google OCR 时,其模型性能结果能进一步提升。
总结
本文提出了一种通过挖掘场景文本背后语义来增强分类模型理解图像内容的方法,该方法的核心是利用场景文字作为关键词,到 wikipedia 知识库中检索出相关的知识,并获取其特征表达,和图像视觉特征进行融合理解,而并非仅仅利用场景文字的表面语义信息。得益于挖掘场景文本背后的知识,该方法能够更好地理解文字语义并不非常直观的内容。实验表明,该方法在 3 个数据集上均取得了最佳结果。