0-Instance and Panoptic Segmentation Using Conditional Convolutions
Instance and Panoptic Segmentation Using Conditional Convolutions

IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 45, NO. 1, JANUARY 2023
背景
作者提出了一种实例和全景分割框架,其在COCO数据集上的表现优于其他几种最先进的方法,这种实例和全景分割框架称为”Condlnst(实例分割和条件卷积)”.
实例分割和全景分割是计算机视觉中的重要任务,需要算法对图像中的每个感兴趣实例进行像素级的分割,并为图像中的每个像素分配语义标签。全景分割在实例分割框架的基础上进一步要求对场景中的“stuff”进行分割,为图像中的每个像素分配语义标签。实例分割和全景分割面临着一个共同的挑战,即如何高效有效地区分个体实例。传统的方法通常采用Mask R-CNN等两阶段方法,通过ROI操作来关注每个实例,但这种方法存在一些缺点,如需要更大的计算量、固定的掩模头等。作者提出的Condlnst 框架,通过将实例分割和全景分割统一为完全卷积网络,消除了ROI裁剪和特征对齐的需要,由于动态生成的条件卷积容量大大提高,掩模头可以非常紧凑,从而大大加快每个实例的推理时间,在实例和全景分割任务上实现了最先进的性能,同时速度快且简单。
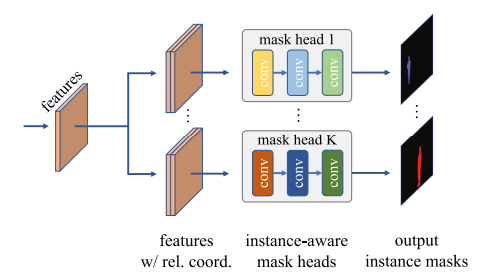
实验方法
Condlnst用于实例分割的整体架构:通过使用实例敏感的卷积滤波器和相对坐标来动态生成掩模头,实现了对每个实例的关注。与传统的固定权重掩模头不同,Condlnst的掩模头参数根据要预测的实例进行调整,使得网络参数能够编码实例的特征,并且只在该实例的像素上激活,从而绕过了标准FCN中的困难。
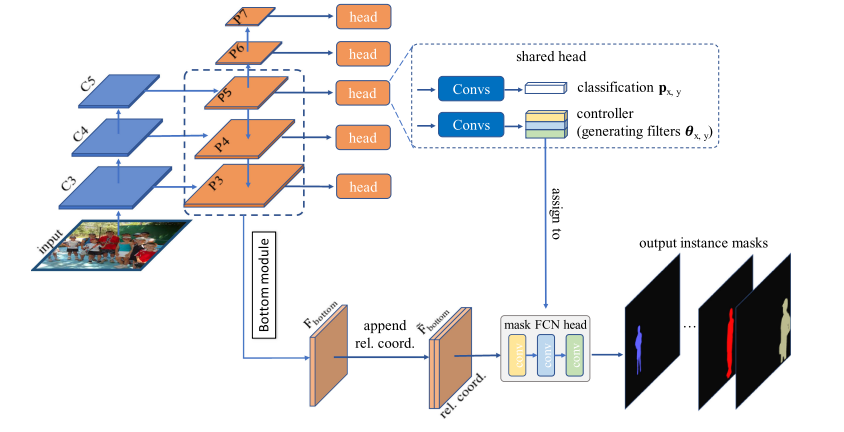
Condlnst结构可以分为四个主要部分:
- **特征提取网络:**负责从输入图像中提取多尺度的特征图。这些特征图通常具有深度学习中的层级结构,表现为从浅层到深层的不同抽象级别。
- 特征金字塔网络: 特征金字塔网络是一种受人体视觉启发的结构,能够将高层次的语义信息与低层次的细节信息结合起来,产生一系列尺度的特征图,这对于检测不同尺寸的对象非常有用。
- CondInst: 在这一模块,网络通过一组称作“head”的子网络来进行实际的实例分割。这些头部分别负责预测类别得分,边界框回归,以及产生实例分辨率的特定掩膜。掩膜生成是实例分割的核心,需要精准地为每个检测到的物体实例生成一个像素级的掩膜。
- 输出和后处理: 最后,网络结合来自头部网络的预测结果,并通过逐像素的分类来生成最终的实例分割掩膜。
以对实例分割掩码、类别预测和边界框预测进行监督学习为训练目标,使网络能够准确地预测每个物体实例的位置、类别和掩码。
模型细节:
实验使用了的MS COCO和Cityscapes数据集进行训练和评估。
在训练过程中,作者采用了多尺度数据增强策略,以提高模型的泛化能力。
基准掩码头采用了三个1x1卷积层,每个卷积层有8个通道,并使用ReLU作为激活函数,最后一层使用sigmoid函数预测前景的概率。
掩码头总共有169个参数,非常轻量级,相比Mask R-CNN等模型,计算复杂度大大降低。
改变底部分支输出特征图的通道数(C_bottom),实验结果表明,在合理范围内(从2到16),性能基本保持稳定。
生成的动态滤波器可以被视为轮廓的表示,与Mask R-CNN不同,Condlnst通过生成的滤波器编码实例的轮廓,因此可以轻松表示包括不规则形状在内的各种形状,更加灵活。
作者建议在Condlnst模型中使用上采样因子为2,因为这种设置在各项指标上表现较好。
在推断过程中去除边界框分支并使用基于掩码的NMS(非极大值抑制),可以获得与基于边界框的NMS相似的性能。
实验结果
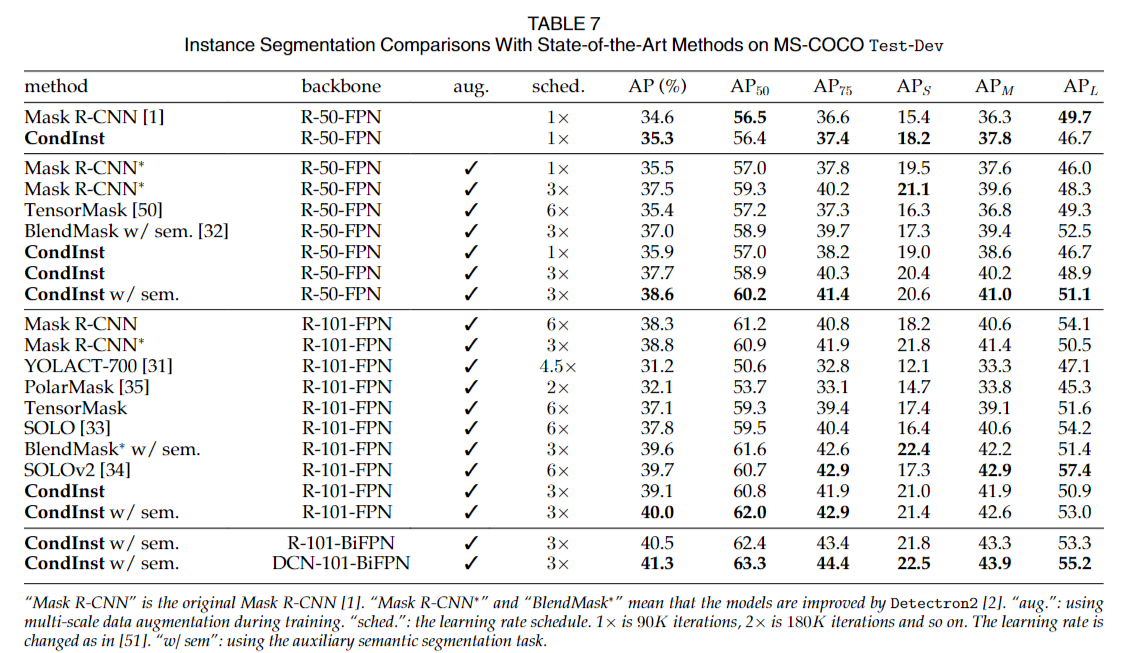
结果显示,Condlnst在1次学习率计划(90K迭代)下的性能优于原始的Mask R-CNN,并且比原始Mask R-CNN更快(每张图像在单个V100 GPU上)。
Condlnst还在性能上优于Detectron2中的Mask R-CNN。
通过更长的训练计划或更强大的骨干网络,如ResNet-101,也可以实现一致的改进。
通过辅助语义分割任务,Condlnst的性能可以从37.7%提升到38.6%(ResNet-50),或从39.1%提升到40.0%(ResNet-101),而推理时间不增加。
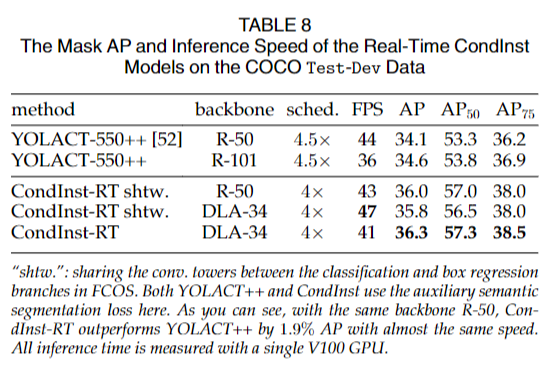
实验结果表明,基于ResNet-50的Condlnst-RT在AP方面优于YOLACT++,并且几乎具有相同的推理速度。
使用更强大的骨干网络DLA-34,CondInst-RT可以实现47 FPS的速度,并保持类似的性能水平。
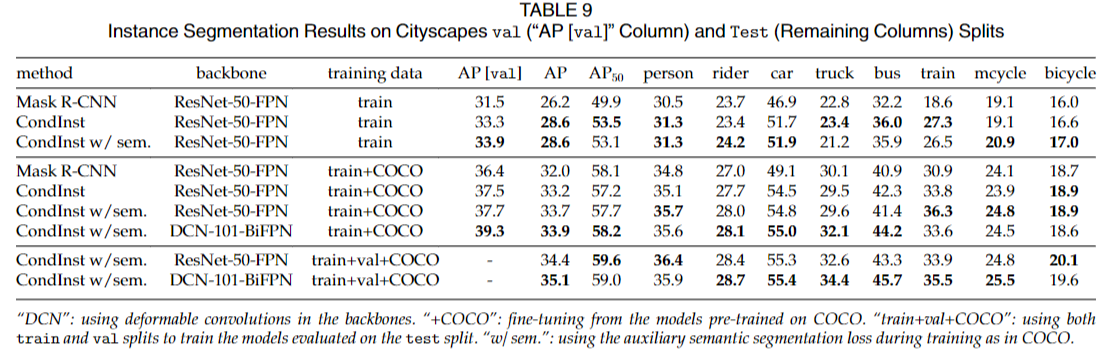
在Cityscapes数据集上,作者使用COCO风格的mask AP作为性能评估指标。实验结果表明,Condlnst在Cityscapes数据集上的表现优于之前的强基线模型Mask R-CNN,提高了超过1%的mask AP。
另外在Cityscapes数据集上,CondInst在全景分割任务上表现优异,超过了之前的方法,包括Panoptic-FPN等。与类似方法AdaptIS相比,CondInst在ResNet-101基础上取得了显着更好的性能,这表明在这里使用动态滤波器可能更为有效。与最近的方法(如Panoptic-FCN)相比,CondInst在全景分割任务上也取得了显著的性能提升。
总结
Condlnst是一个新的实例分割框架,通过动态生成掩码头部的滤波器,减少了参数和计算复杂度,提高了速度和准确性,同时无需更长的训练周期。它还可以简单地扩展到解决全景分割问题,并在COCO数据集上达到最先进的性能。