0-CDDSA: Contrastive Domain Disentanglement and Style Augmentation for Generalizable Medical Image Segmentation
CDDSA:用于广义医学图像分割的对比域去纠缠和风格增强

发表于:Medical Image Analysis Volume 89 ,2023年10月, 102904
背景
在分割未见过的临床医学图像的过程中,区分域特定特征和域不变特征的能力是实现域泛化(鼓励模型DG)的关键。现有的DG方法难以有效的解纠缠,从而获得高泛化能力,故提出了本文的方法:CDDSA框架(对比域去纠缠和风格增强),用于推广医学图像分割。CDDSA的大概步骤如下:
- 特征分解:首先,提出了一个分解网络,将图像分解为领域不变的解剖表示和领域特定的风格编码。解剖表示被送入一个分割模型,该模型不受领域转移的影响。
- 重建图像:分解网络通过一个解码器进行正则化,结合解剖和风格编码来重建输入图像。这有助于学习如何有效地分离领域特定和领域不变的特征。
- 分割模型:分割器采用领域不变的解剖表示作为输入,以获得分割结果。这样可以确保分割模型不受领域变化的影响,从而提高泛化能力。
- 风格增强:引入风格增强策略,将给定图像的解剖表示与增强的风格编码相结合,生成新领域中的图像。这有助于模型学习如何适应不同风格的图像,提高泛化性能。
使用视杯和椎间盘分割的公共多位点眼底图像数据集和用于鼻咽总肿瘤体积(GTVnx)分割的内部多位点鼻咽癌磁共振图像(NPC-MRI)数据集上进行了验证,实验结果表明,所提出的CDDSA在不同领域具有显著的可推广性,并且在领域可推广分割方面优于几种最先进的方法。
在医学图像分割中,深度学习方法取得了显著的性能,但现有模型通常建立在训练和测试图像来自相同领域且具有非常相似(甚至相同)分布的假设上。然而,在临床实践中,由于多种因素(如扫描设备、成像协议、患者群体和图像质量的差异),测试图像通常来自于与训练集不同的医疗中心,这种假设经常不成立。这种领域转移会显著降低模型在测试时的性能。为了解决这一问题,许多领域自适应方法被探索,以将源领域中的一组标记图像的知识转移到目标领域中的图像。
实验方法
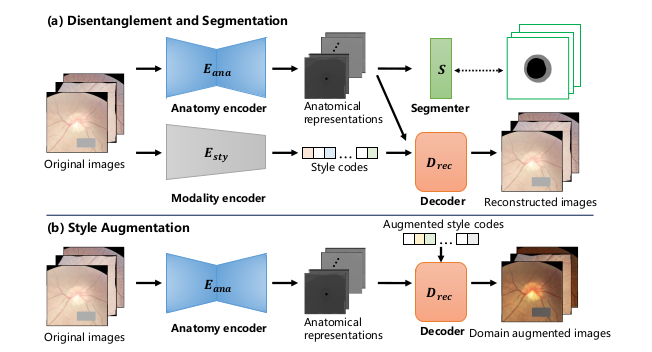
a)图像分割;b)图像增强。仅使用一对解剖编码器和样式编码器将不同领域中的医学图像组合成领域不变的解剖表示和领域特定的样式代码,该编码器和样式代码由接受解剖表示和样式代码的解码器正则化以重建图像。
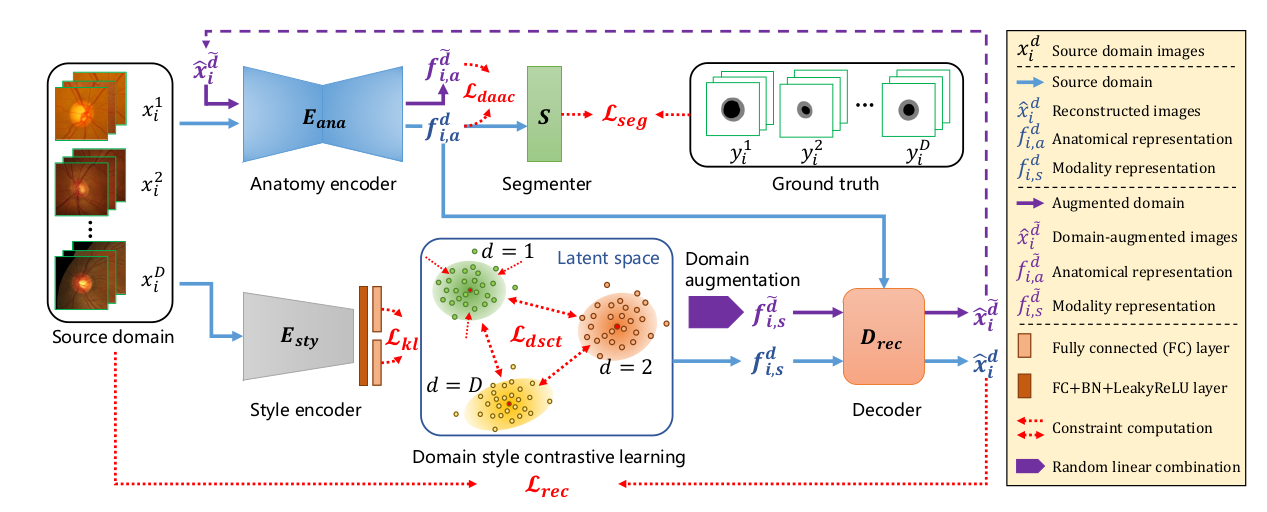
图中几个主要组件:
- **编码器部分 (E_anat 和 E_sty)**:解剖编码器(E_anat)和风格编码器(E_sty)分别提取输入图像的解剖结构和风格信息。
- **域对比学习 (Domain-wise contrastive learning)**:在潜在空间中进行对比学习,以使来源域和目标域的数据表示彼此靠近,并远离其他域的数据表示。
- **域增强 (Domain augmentation)**:通过加入风格扰动(s_seg)来增强图像,从而提高网络的鲁棒性。
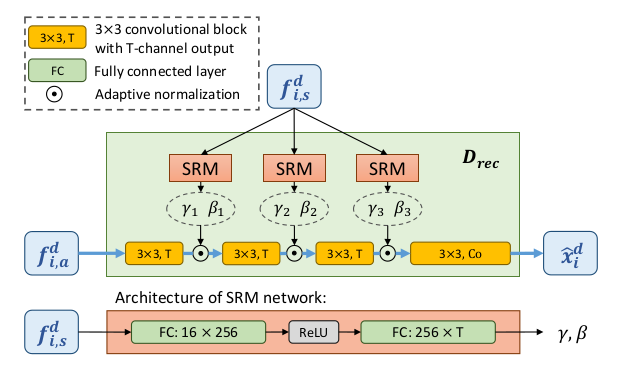
- **重构模块 (D_rec)**:用来重构输入图像,以确保编码后的解剖和风格表示的质量。
- **判别器模块 (D_dom)**:用来区分不同域的图像,并在损失函数(L_adv)中发挥作用,进一步指导表示学习。
通过这些模块和损失函数的协同作用,网络能够学习到解耦的解剖结构和风格信息,实现多域医学图像的处理和分析。
实验结果
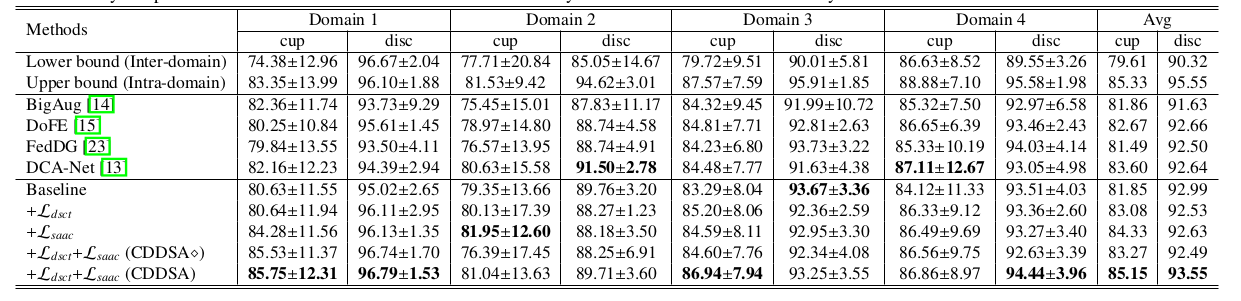
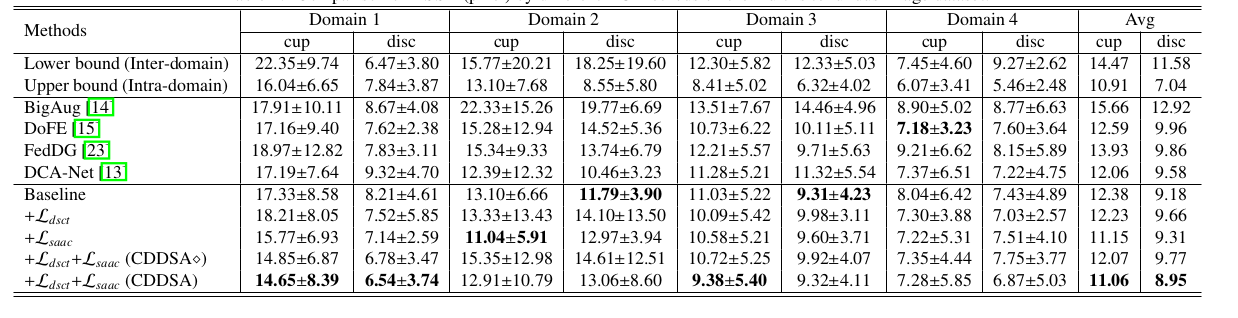
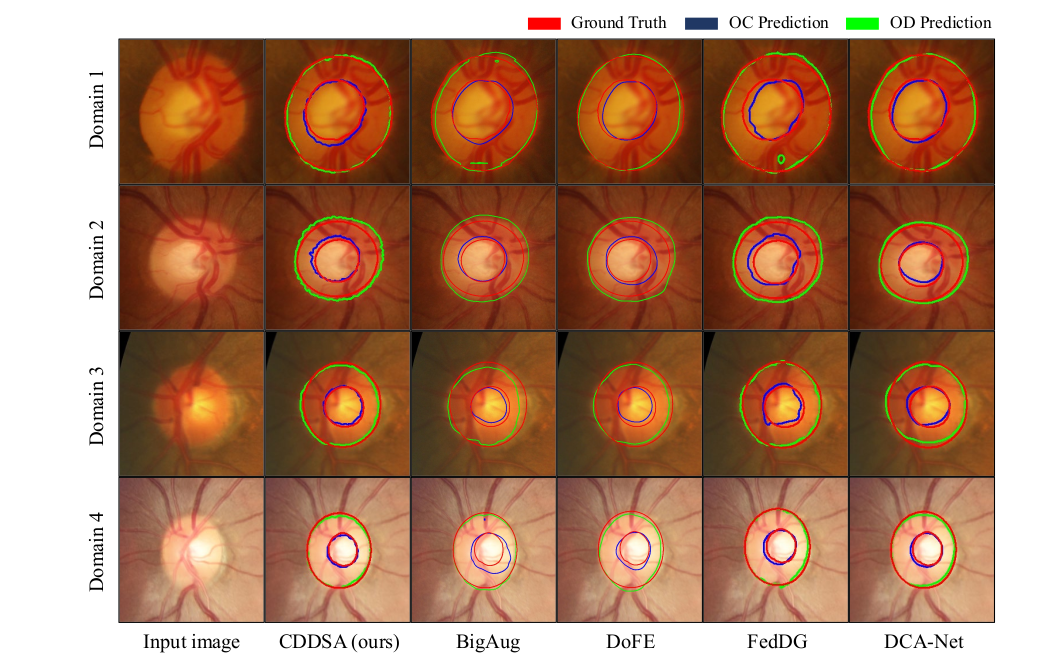
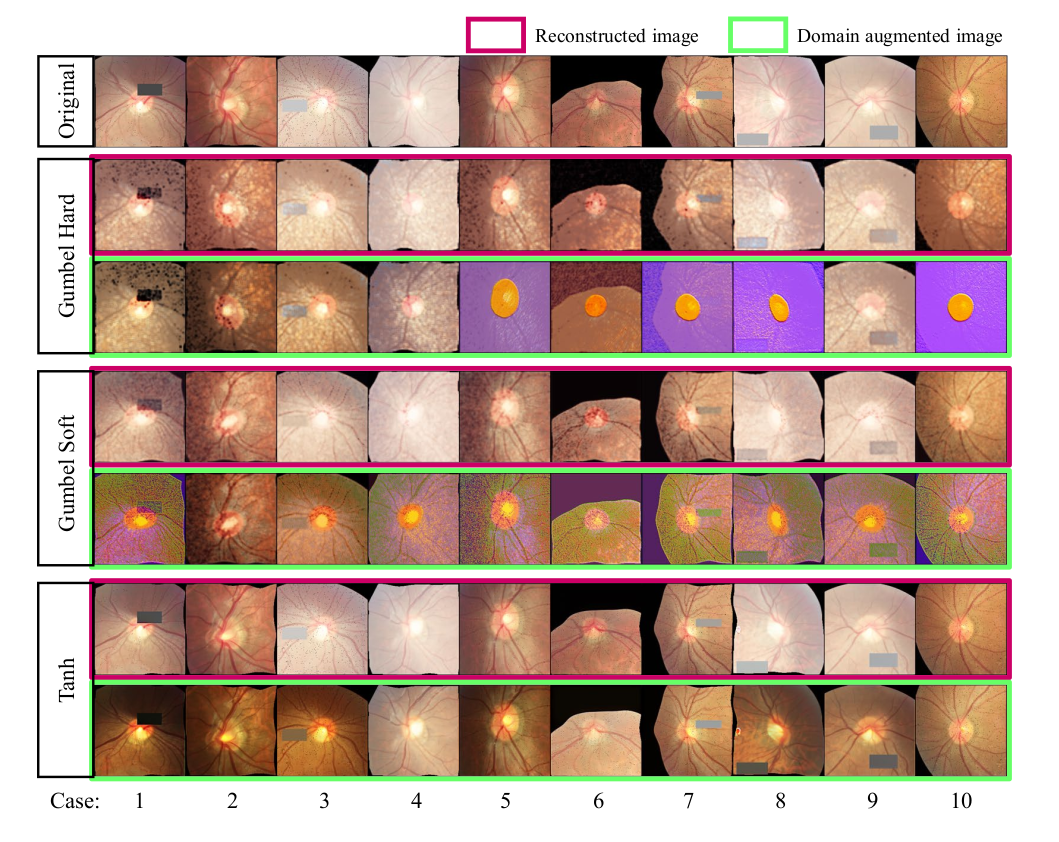
作者也对其他不同的数据集做了实验, 并附加了消融学习结果。
总结
CDDSA框架在多领域医学图像分割任务上有效性。通过对多领域眼底图像和多领域鼻咽癌磁共振图像(NPC-MRI)的全面实验结果,作者展示了CDDSA在未见领域上取得了高泛化性能,并且优于几种最先进的领域泛化方法。表明CDDSA框架在处理医学图像分割中的领域泛化问题上具有潜在的应用前景。