0-Very Deep Convolutional Networks For Large-Scale Image Recognition
用于大规模图像识别的超深卷积网络 2015 (VGG)

ImageNet Large-ScaleVisual Recognition Challenge (ILSVRC):ImageNet大规模视觉识别挑战
背景
卷积核到底该设置为多少?AlexNet采用了极大的size(11x11)、ZFNet将size调小了但仍然使用到了7x7,GoogLeNet同时使用了不同的filter size…
本篇文章VGG使用3x3不断叠加,使得CNN模型可以达到更深的层数且得到更好的精准度。本方法其实是对于AlexNet的基础上做了更好的改进。VGG的模型架构如下图所示:
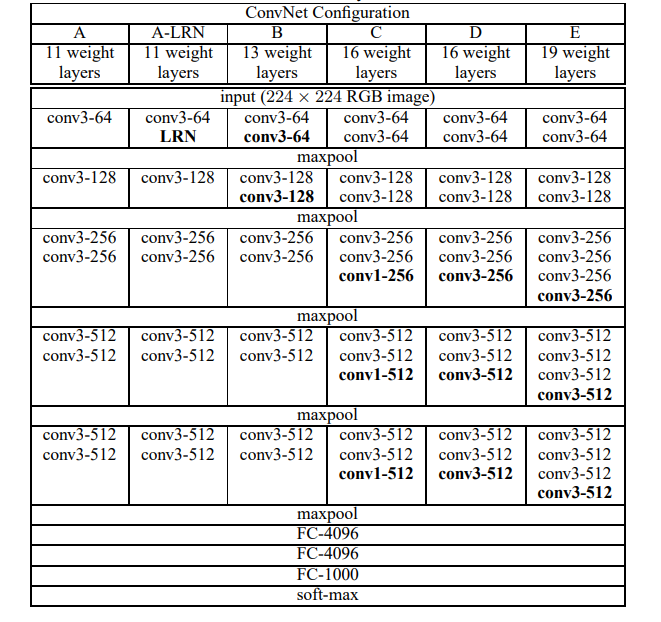

作者根据配置进行了分析:7x7的卷积和3个3x3的卷积感受野实际上是一样的,那为什么要用小卷积来代替大卷积呢?
实验方法
VGGNet 1x1卷积
选用1x1卷积核的最直接原因是在维度上继承全连接,conv1x1更加专注于跨通道的特征组合,conv3x3既考虑跨通道,也考虑局部信息整合。使用1x1卷积也可以在3x3或5x5卷积计算前先降低feature map的维度。
VGGNet 卷积核变小
卷积核全部替换为3×3(极少用了1×1)步长为1,而使用小的卷积核可以提升性能,加深网络结构。
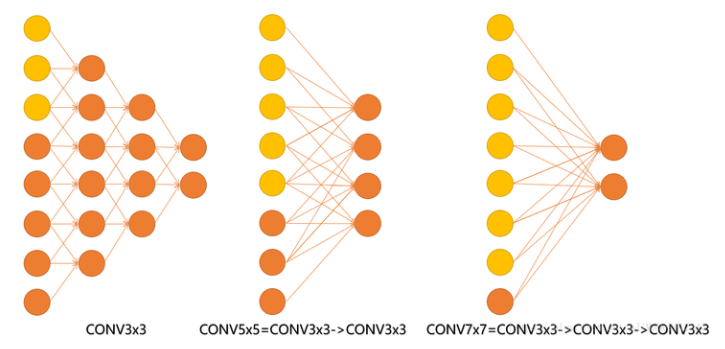
VGGNet 层数更深更宽
3个激活函数(ReLU)去代替1个,可使决策函数更加具有辨别能力;
3x3比5x5,7x7,11x11的Conv filter的参数减少,减少卷积数量带来性能提升。
VGGNet 池化核变小且为偶数
AlexNet中的max-pool全是3×3的,但VGGNet中是2×2的,可能的原因是2×2的max-pool带来的信息损失相对于3×3的来说要小一些,相比于3×3更容易捕获细小的特征变化起伏。在网络的层数增长的过程中,池化忽略的信息加上缓冲,并降低softmax的学习压力。
卷积只增加feature map的通道数,而池化只减少feature map的宽高。如今也有不少做法用大stride卷积去替代池化,未来可能没有池化。
训练阶段
- 优化方法:带动量(momentum)的小批量梯度下降
- batch size:256
- learning rate:0.01
和AlexNet一样,当val-acc 不下降则学习率缩小十倍,训练过程缩小了三次 - momentum:0.9
- weight decay(L2惩罚乘子):0.0005
- dropout rate(前两个全连接层):0.5
- 目标函数:多项式逻辑斯特回归(SoftMax)
- 迭代次数:37万次iteration(74 epochs)后,停止训练
测试阶段
- 测试图像的尺寸Q和训练图像的尺寸 S 没必要完全一样。
- 全连接层先转化为卷积层第一个全连接层转为7x7的卷积层,后两个转化为1x1的卷积层。
- 再将这样得到的全卷积网络运用在整幅图像上。
- 使用水平翻转对测试图像进行增强。
实验结论
单一尺寸上的卷积网络

注意使用局部相应标准化网络(A-LRN)的性能并没有比未用标准化层的A高。
更大的数据集使用更深的模型会更好。小滤波器的卷积网络比大滤波器的千层网络性能更好。
多尺寸上的卷积网络
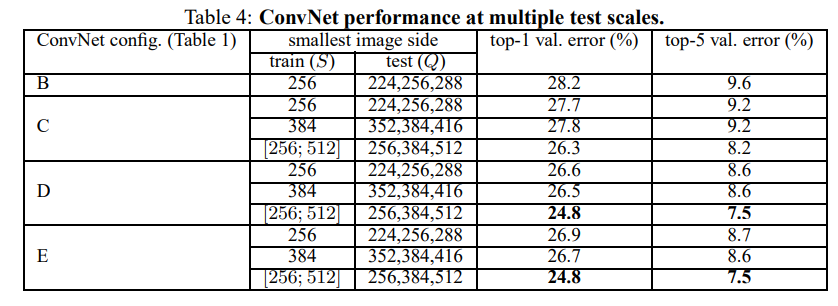
测试时图片尺寸波动会使性能更好。
多裁剪的评估
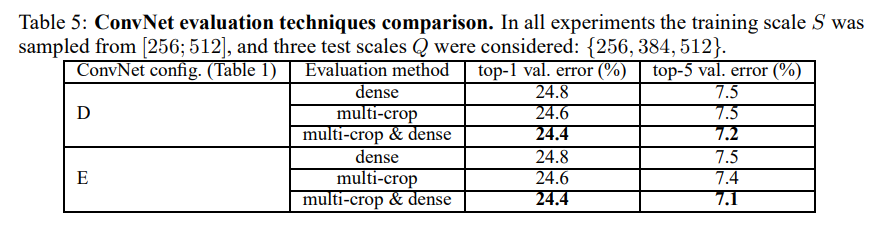
多重裁切比密集评估的效果好,并且两者互补。
融合卷积网络
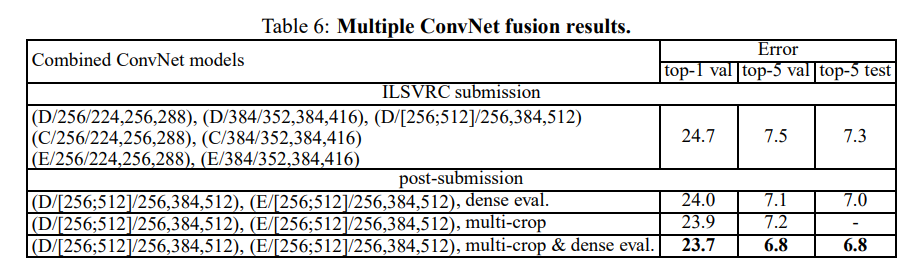
将两个表现最好的多尺寸模型组合禁用,将会进一步减少错误率。
结果比较
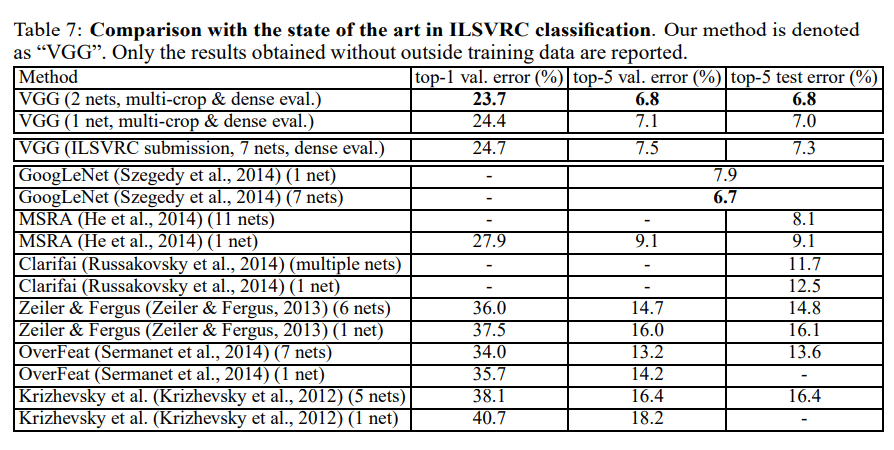
使用了7个模型组合的测试错误率,为7.3%,使用2个模型的组合,将错误率降低到了6.8%。
总结
VGG网络继承了AlexNet中的不少网络结构,同时继承了OverFeat在Localization任务中的做法,学习这种经典的网络应该可以对日后在Computer Vision领域的学习起到一定的作用,小卷积核的应用以及VGGNet的输入图像rescale应该是本论文中重点关注的点。