0-ImageNet Classification with Deep Convolutional Neural Networks
AlexNet 2012 NIPS

背景
为了从数以百万计的图像中学习出数千种的目标,需要一个具有很强学习能力的模型。尽管CNNs有效率的局部结构,但大规模地应用于高分辨率图像消耗资源仍然过多。本文介绍了一种可以进行图像识别的卷积神经网络,包含了大量的不常见和新的特征来提升网络性能,减少训练时间。
包含6千万个参数和65万个神经元,包含了5个卷积层,其中有几层后面跟着最大池化层,以及3个全连接层,最后还有一个1000路的softmax层。为了加快训练速度,本文使用了不饱和神经元以及一种高效的基于GPU的卷积运算方法。为了减少全连接层的过拟合,采用了正则化方法“dropout”,该方法被证明非常有效。
实验
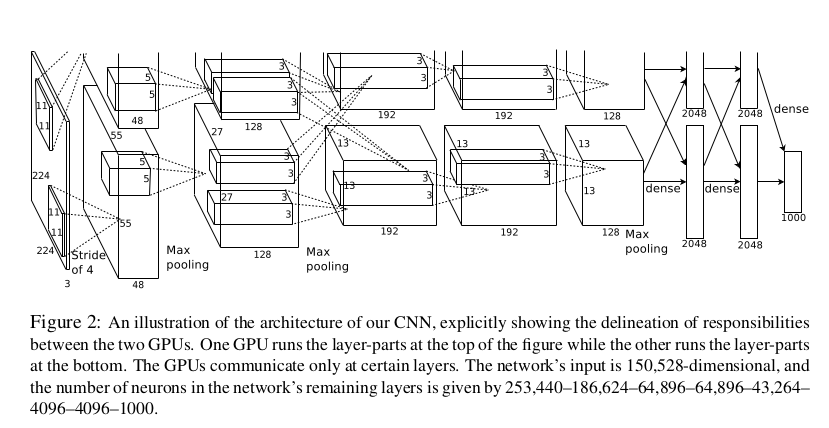
网络结构
8层学习层——5层卷积层和三层全连接层
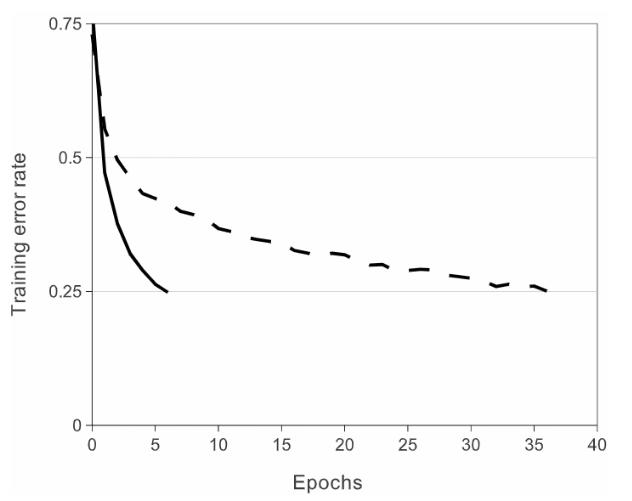
用ReLUs主要是对训练集的拟合进行加速。快速学习对由大规模数据集上训练出大模型的性能有相当大的影响。
ReLUs具有符合本文要求的一个性质:它不需要对输入进行归一化来防止饱和。
(1)输入图像大小:224 * 224 * 3
(2)第一层卷积设置:卷积–>ReLU–>局部响应归一化(LRN)–>池化
(3)第二层卷积:卷积–>ReLU–>局部响应归一化(LRN)–>池化
(4)第三层卷积:卷积–>ReLU
(5)第四层卷积:卷积–>ReLU
(6)第五层卷积:卷积–>ReLU–>池化
(7)全连接层
(8)全连接层2
(9)输出层(全连接层3)
降低过拟合所采用的方法
数据扩增
为了降低过拟合,提高模型的鲁棒性,这里采用了两种Data Augmentation数据扩增方式:
a.生成图像平移和水平反射。通过从256×256幅图像中提取随机224×224块图像(及其水平反射),并在这些提取的图像上训练AlexNet。这将训练集的大小增加了2048倍。
b.改变训练图像中RGB通道的强度。在整个ImageNet训练集中对RGB像素值集执行PCA(Principal Component Analysis)[5]操作。
Dropout
训练采用了0.5丢弃率的传统Dropout,对于使用了Dropout的layer中的每个神经元,训练时都有50%的概率被丢弃。所以每次输入时,神经网络都会对不同的结构进行采样,但是所有这些结构都共享权重。这种技术减少了神经元之间复杂的相互适应,因为神经元不能依赖于其他神经元的存在,因此,它被迫获得更健壮的特征。测试时使用所有的神经元,但将它们的输出乘以0.5。 论文中还提到了:Dropout使收敛所需的迭代次数增加了一倍。
实验
batch size=128,动量项v=0.9,权值衰减(weight decay) wd=0.0005,W服从均值为0、标准差为0.01的高斯分布。
偏置项:第2、4、5卷积层和全连接层的b=1(促进最初阶段ReLU的学习);其它层b=0。
学习率:初始为0.01,当验证集的错误率停止降低时,手动缩减学习率(除以10)。
结果
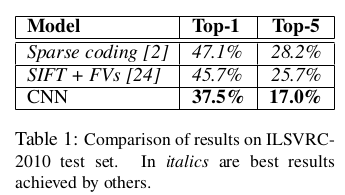
最后结果top-1是67.4%,top-5是40.9%,比发布的最好的结果还要好。
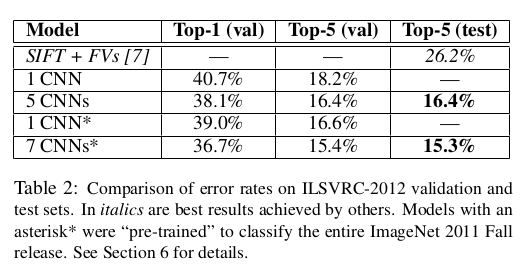

左边部分,作者展示了8张图片的预测结果来说明网络在预测top-5时都从测试图片中学到了什么。右边部分则对比了测试集中的五张图片和在训练集中与之最相似的6张图片,如果两张图片产生的特征激活向量(即CNN的输出结果)的欧几里得距离小,就认为这两张图片相似。
总结
对于一个较大的数据集,给出了一种解决分类任务的方法,在当时取得了很重大的突破,AlexNet在深度学习
发展史上的历史意义远大于其模型的影响。卷积神经网络也成为计算机视觉的核心算法模型。
如果我们今天回过头看看,将人工智能领域的蓬勃发展归功于某个事件的话,这份殊荣应属于2012年 ImageNet大赛的比赛成果。
2012年 ImageNet 的那场赛事的的确确引发了今天人工智能井喷式的发展。之前在语音识别领域是有一些成果,但大众并不知道,也不关心,而 ImageNet 让人工智能开始进入公众视野。