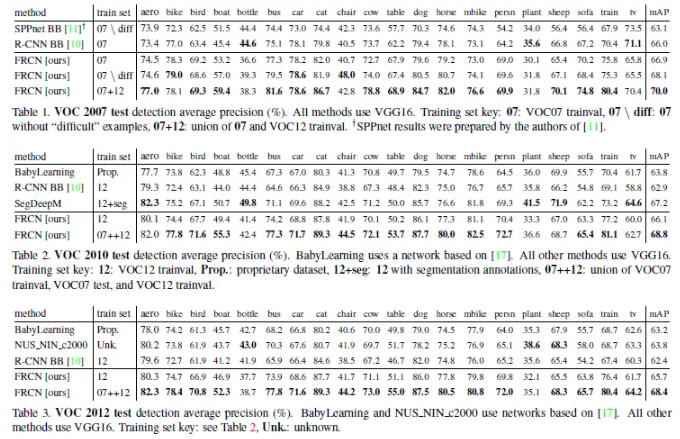
0-Fast R-CNN
Fast R-CNN

背景
上回说到R-CNN,而Fast R-CNN是原作者在2015年发表的续作,性能比之前的R-CNN块9倍。目标检测要面临的两大问题是(1)需要处理的候选框过多(2)候选框的位置不精确要进行微调。
这就不得不提到R-CNN的缺点:训练以及测试的过程复杂,需要大量的RAM,R-CNN网络需要对候选框进行形变操作后再输入CNN网络提取特征,形变会产生一些列问题。
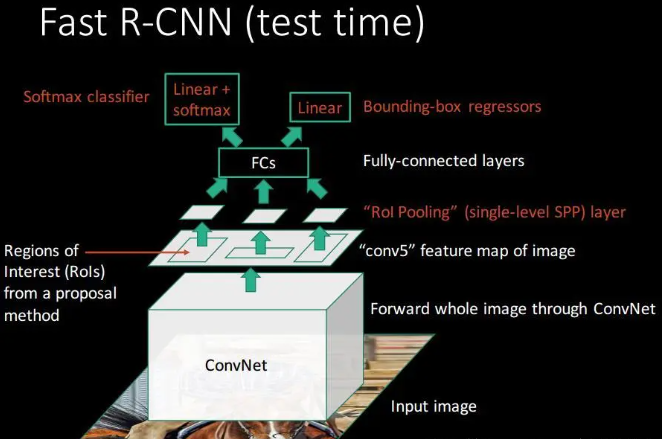
相比于RCNN主要在以下方面进行了改进:
(1)Fast RCNN仍然使用selective search选取2000个建议框,但是这里不是将这么多建议框都输入卷积网络中,而是将原始图片输入卷积网络中得到特征图,再使用建议框对特征图提取特征框。这样做的好处是,原来建议框重合部分非常多,卷积重复计算严重,而这里每个位置都只计算了一次卷积,大大减少了计算量
(2)由于建议框大小不一,得到的特征框需要转化为相同大小,这一步是通过ROI Pooling层来实现的(ROI表示region of interest即目标)
(3)Fast RCNN里没有SVM分类器和回归器了,分类和预测框的位置大小都是通过卷积神经网络输出的
(4)为了提高计算速度,网络最后使用SVD代替全连接层
实验方法
inference过程
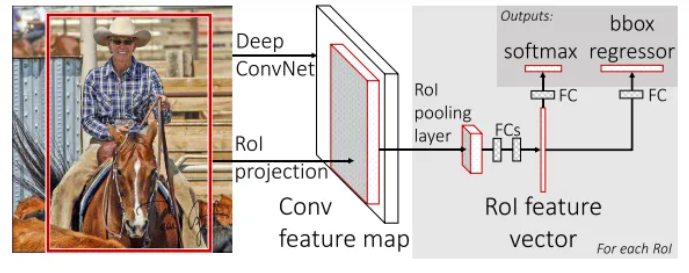
- CNN:将任意size的图像输入网络,计算整张图的feature maps
- Selective search:在任意size图片上采用selective search算法提取约2k个候选框
- RoI projection:在特征图中找到每个候选框对应的特征框(深度和特征图一致)
- RoI pooling:相当于只有一层的空间金字塔池化SPP,将每个特征框划分为HW个网格(eg: 77 for VGG16),每个网格中执行最大池化,输出为HWC,特征图深度不变。RoI pooling的输出需要满足下一层全连接层输入要求
- FC+softmax/bbox regerssion
- NMS:利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠候选框,最终得到每个类别中回归修正后的得分最高的窗口
损失函数
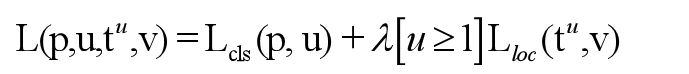
[u≥1]是艾弗森括号,当u≥1,这一项为1,否则,这一项为0
训练过程
对训练集中的图片,用selective search提取出每一个图片对应的一些proposal,保存图片路径和bounding box信息
对每张图片,根据图片中bounding box的ground truth信息,给该图片的每一个proposal标记类标签,并保存。具体操作:对于每一个proposal,如果和ground truth中的proposal的IOU值超过了阈值(IOU>=0.5),则把ground truth中的proposal对应的类标签给原始产生的这个proposal,其余的proposal都标为背景;
使用mini-batch=128,25%来自非背景标签的proposal,其余来自标记为背景的proposal;
训练CNN,最后一层的结果包含分类信息和位置修正信息,用多任务的loss,一个是分类的损失函数,一个是位置的损失函数。
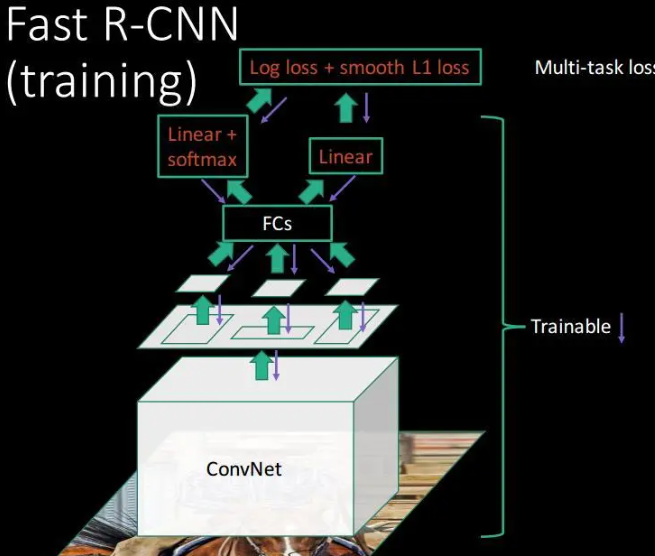
测试过程
用selective search方法提取图片的2000个proposal,并保存到文件;将图片输入到已经训好的多层全卷积网络,对每一个proposal,获得对应的RoI Conv featrue map;对每一个RoI Conv featrue map,按照3.1中的方法进行池化,得到固定大小的feture map,并将其输入到后续的FC层,最后一层输出类别相关信息和4个boundinf box的修正偏移量;
对bounding box 按照上述得到的位置偏移量进行修正,再根据nms对所有的proposal进行筛选,即可得到对该张图片的bounding box预测值以及每个bounding box对应的类和score。
实验结果