0-Deep Residual Learning for Image Recognition
用于图像识别的深度残差学习ResNet

文章发表于2015年
背景
越深的神经网络训练起来越发困难,利用残差学习框架,能够简化深层的的网络训练。根据输入来学习残差函数而非原神函数,在ImageNet数据集使用了152曾的网络来评价残差网络,具有很低的复杂度,并且多个ensemble在测试集上的错误率很低。
在深度学习神经网络的训练中,层次越深,训练越困难,优化越困难,并且会出现梯度消失/爆炸等问题阻碍网络收敛,使用归一初始化(normalized initialization)和中间归一化(intermediate normalization)在很大程度上解决了这一问题,使得在前数十层的网络在反向传播的随机梯度下降(SGD)上能够收敛。
层数更深后,精度饱和,训练模型迅速变差
残差神经网络(也称为残差网络或ResNet)是一种深度学习模型,其中权重层参考层输入学习残差函数。
残差学习框架通过引入残差学习的概念,使得训练比以往更深的网络变得更加容易。这种框架允许网络学习残差映射,即学习残差函数而不是直接学习底层特征映射。通过这种方式,网络可以更轻松地学习残差,从而减轻了训练深度网络时出现的梯度消失或梯度爆炸等问题。
步骤:
在ImageNet 2015比赛之前,2012 年 ImageNet 开发的AlexNet模型是一个八层卷积神经网络。牛津大学视觉几何小组 (VGGNet) 于 2014 年开发的神经网络通过堆叠 3×3 卷积层达到了 19 层的深度,然而,堆叠更多层会导致训练精度急剧下降,这被称为“退化”问题。
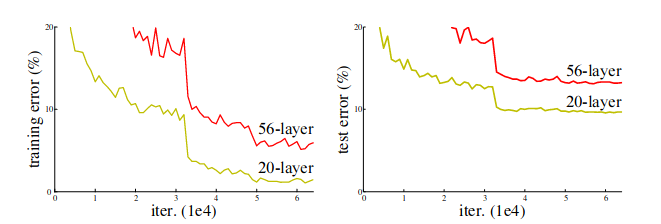
如上图所示,将20层神经网络加深到56层之后,模型的training error和test error反而更高了。
论文提出了一个解决方案,就是使用深度残差网络:
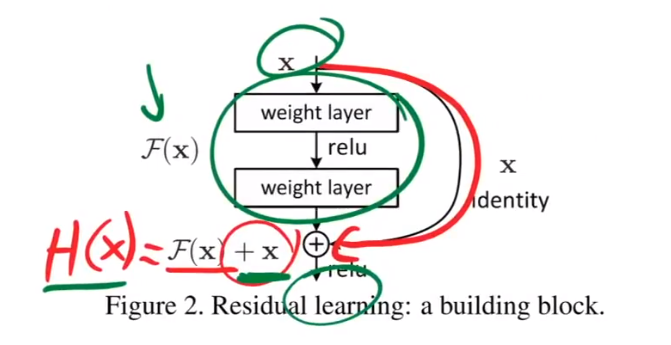
从深层网络出发,深层网路=浅层网络+附加层,如果浅层网络已经做的非常好了,附加层只会进行一些微小的改动,得到的结果就是网络随着深度的增加,准确率会上升,而不是degredation描述的下降。
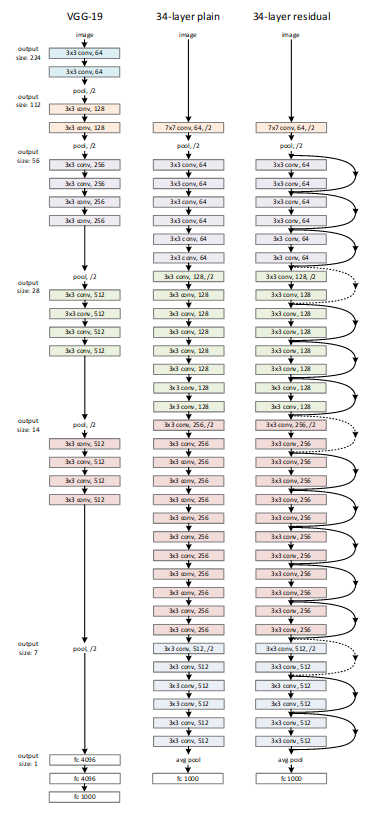
从图中可以看到ResNet中的快捷连接有实线和虚线,实线表示输入输出维度相同,虚线表示维度不同。对于 ResNet,当输入维度小于输出维度时,有3 种类型的快捷连接方式:
- (A) Shortcut 执行恒等映射,使用额外的零填充来增加维度。因此,没有额外的参数。
- (B) 投影快捷方式仅用于增加维度,其他快捷方式是恒等映射。需要额外的参数。
- (C) 所有捷径都是投影。额外的参数比(B)的要多。
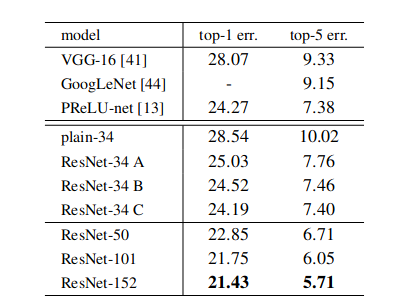
实验表明方式C的精度最高,但作者建议使用方式B,因为C的计算量和参数量都有所增加。
实验方法:
- 将图像扩充到[256,480]之间,再resize为224 × 224
- 使用颜色增强
- 使用BN
- 将学习率通过乘0.1减小(这个方法现在已经不太用了,因为不知道具体在什么时候乘这个0.1,有的时候可能乘早了,在晚一点乘效果会更好,图中断崖式下降的地方就是学习率乘了0.1的地方)
- 没有使用dropout操作(dropout对卷积层的正则化作用很小:卷积层的参数必FC少很多,本身不需要正则化;同时,特征图编码的是空间的关系,他们之间是高度相关的,这也导致了dropout的失效)
- 在测试中使用了10-crop(10-crop是指在test的时候,从原始图片及翻转后的图片中,从四个corner和一个center各crop一个(224,224)的图片,一次是5张,镜像之后再操作一次就是10张。然后对这10张图片进行分类,对10次预测结果做average)
- 使用了{224,256,384,480,640}这5种不同的分辨率
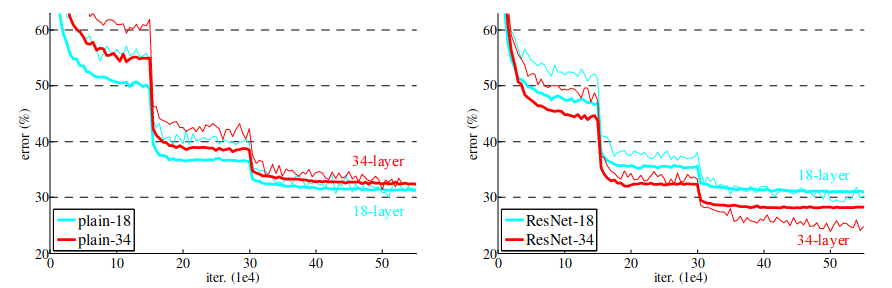
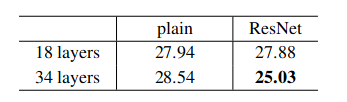
当使用普通网络时,由于退化问题,18 层的结果优于 34 层;使用 ResNet 时,34 层优于 18 层,通过快捷连接解决了梯度消失问题。(比较 18 层普通网络和 18 层 ResNet,没有太大区别。这是因为浅层网络不会出现梯度消失问题。)