2-工具与软件-5-TensorFlow
环境的安装
首先去conda官网下载 conda
linux系统先使用bash安装
1 | |
安装后在pycharm配置conda环境,然后新建AI项目,选择conda,然后在所选择的解释器中安装tensorflow
选择pycharm自动安装(会自动安装其他依赖,十分方便)
所需安装:
- conda
- tensorflow
如果你是N卡,可继续在项目终端中输入
1 | |
1 | |
安装GUP加速
1.1 人工智能三学派
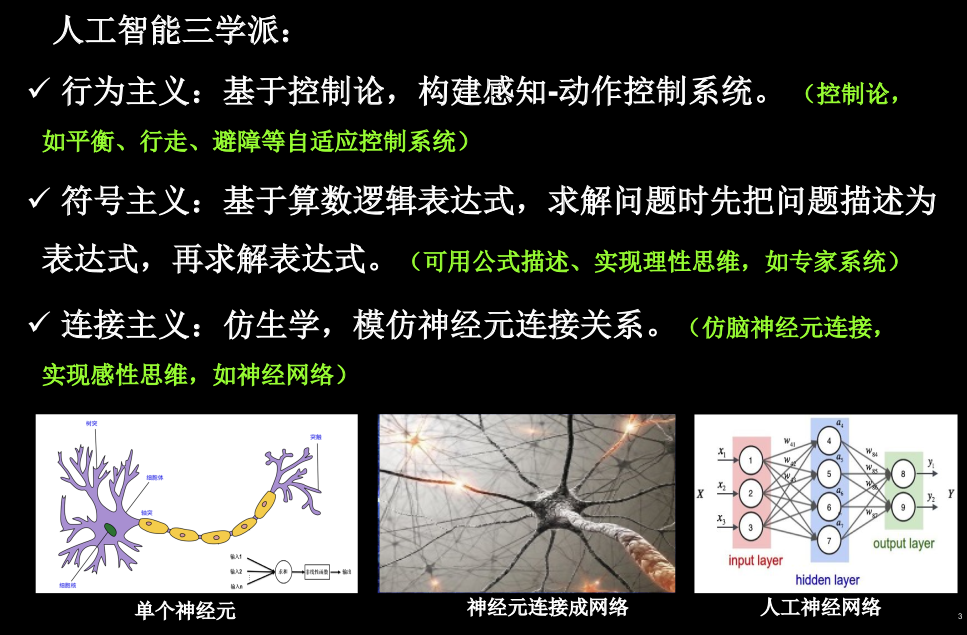
行为主义:机器人的摔倒预测
符号主义:用公式描述的人工智能,让PC具有了理性思维
连接主义:仿造人的感性思维
1.2 神经网络的设计过程
用神经网络实现鸢尾花的分类:梯度下降
目的:找到一组参数w和b,使得损失函数最小。
梯度:函数对各参数求偏导后的向量。 梯度下降的方向是函数减小的方向
梯度下降法:沿损失函数梯度下降的方向,寻找损失函数的最小值,得到最优参数的方法
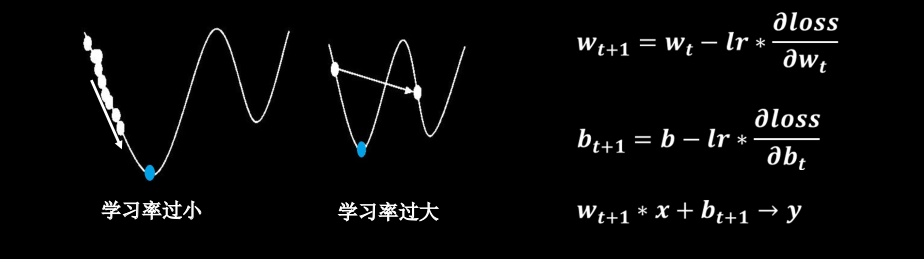
学习率(lr):设置过小,收敛缓慢;设置过大,无法收敛(找不到最小值)
反向传播:从后向前,逐层求损失函数对每层神经元参数的偏导数,迭代更新所有参数。
损失函数:
$$
loss = (w + 1 )^2
$$
$$
\frac{\part loss}{\part w} = 2w +2
$$
代码实现:
1 | |
Output:
1 | |
1.3 张量生成
张量(Tensor:多维数组 /列表 ) 阶 :张量的维数
| 维数 | 阶 | 名 | 例 |
|---|---|---|---|
| 0-D | 0 | 标量 scalar | s=1 |
| 1-D | 1 | 向量 vector | v=[1,2,3] |
| 2-D | 2 | 矩阵 matrix | m=[[1,2],[3,4],[5,6]] |
| n-D | n | 张量 tensor | t=[[[[……]]]] (n个) |
数据类型
1 | |
创建Tensor
tf.constant(张量内容,dtype=数据类型(可选))
创建全为0的张量 tf.zeros(维度)
纬度:一维直接写个数;二维[行,列];多维[n,m,j,k,…..]
创建全为1的张量 tf.ones(纬度)
创建全为指定值的张量 tf.fill(维度,指定值)
正态分部的随机数,默认值为0,标准差为1
tf.random.normal(纬度,mean=均值,stddev=标准差)
生成截断式正态分布的随机数
tf.random.truncated_normal(纬度,mean=均值,stddev=标准差)
在正态分布中如果随机生成的数据的取值在($\mu\pm2\sigma$)
生成均匀分布的随机数
tf.random.uniform(纬度,minval=最小值,maxval=最大值)
1.4 TF2常用函数
强制tensor转换为该数据类型tf.cast (张量名,dtype=数据类型)
计算张量维度上元素的最小值tf.reduce_min (张量名)
计算张量维度上元素的最大值tf.reduce_max (张量名)
理解axis
在一个二维张量或数组中,可以通过调整 axis 等于0或1 控制执行维度。
axis=0代表跨行(经度,down),而axis=1代表跨列(纬度,across)
如果不指定axis,则所有元素参与计算。
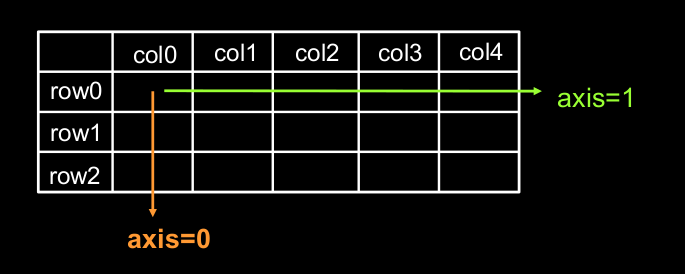
计算张量沿着指定维度的平均值tf.reduce_mean (张量名,axis=操作轴) (不指定axis,则对所有元素进行操作)
计算张量沿着指定维度的和tf.reduce_sum (张量名,axis=操作轴)
tf.Variable () 将变量标记为“可训练”,被标记的变量会在反向传播
中记录梯度信息。神经网络训练中,常用该函数标记待训练参数。tf.Variable(初始值)w = tf.Variable(tf.random.normal([2, 2], mean=0, stddev=1))
TensorFlow中的数学运算
对应元素的四则运算:tf.add,tf.subtract,tf.multiply,tf.divide
只有纬度相同的张量才能做四则运算。
平方、次方与开方: tf.square,tf.pow,tf.sqrt
矩阵乘:tf.matmul
切分传入张量的第一维度,生成输入特征/标签对,构建数据集data = tf.data.Dataset.from_tensor_slices((输入特征, 标签))
(Numpy和Tensor格式都可用该语句读入数据)
tf.GradientTape
with结构记录计算过程,gradient求出张量的梯度
1 | |
enumerate是python的内建函数,它可遍历每个元素(如列表、元组
或字符串),组合为:索引 元素,常在for循环中使用。enumerate(列表名)
独热编码:在分类问题中,常用独热码做标签,标记类别:1表示是,0表示非。 tf.one_hot (待转换数据, depth=几分类)
当n分类的n个输出 (y0 ,y1, …… yn-1)通过softmax( ) 函数,
便符合概率分布了。也就是说,将多个权重占比划分归为1。
$$
\forall x \ \ P(X = x) \in [0,1] 且 \sum_{x}P(X = x) = 1
$$
assign_sub 赋值操作,更新参数的值并返回。
调用assign_sub前,先用 tf.Variable 定义变量 w 为可训练(可自更新)。
w.assign_sub (w要自减的内容)
返回张量沿指定维度最大值的索引
tf.argmax (张量名,axis=操作轴) numpy中也有类似函数
1.5 鸢尾花数据集的读入
Setosa Iris(狗尾草鸢尾),Versicolour Iris(杂色鸢尾),Virginica Iris(弗吉尼亚鸢尾)
鸢尾花数据来源:sklearn框架

1 | |
1.8 神经网络实现鸢尾花的分类
1.准备数据
数据集读入
1 | |
数据集乱序
1 | |
分成用不相见的训练集和测试集
1 | |
配成【输入特征,标签】对,每次喂入一个batch
1 | |
2.搭建网络
定义神经网络中的所有可训练参数
1 | |
3.参数优化
嵌套循环迭代,with结构更新参数,显示当前loss
1 | |
4.测试效果
计算当前参数前向传播后的准确率,显示当前acc
1 | |
5.acc / loss 可视化(查看效果)
1 | |
2.1 预备知识
函数:
tf.where() 条件语句真返回A,条件语句假返回Btf.where(条件语句,真返回A,假返回B)
np.random.RandomState.rand()返回一个[0,1)之间的随机数np.random.RandomState.rand(维度) #维度为空,返回标量
np.vstack()将两个数组按垂直方向叠加np.vstack(数组1,数组2)
np.mgrid[ ] 返回间隔数值点,可同时返回多组, [起始值 结束值)np.mgrid[ 起始值 : 结束值 : 步长 ,起始值 : 结束值 : 步长 , … ]
x.ravel( ) 将x变为一维数组,“把. 前变量拉直”np.c\_[ ] 使返回的间隔数值点配对np.c\_[ 数组1,数组2, … ]
2.2 复杂度学习率
NN复杂度:多用NN层数和NN参数的个数表示

空间复杂度:
层数 = 隐藏层的层数 + 1个输出层
图为2层NN
总参数 = 总w + 总b
图中 3x4+4 + 4x2+2 = 26
时间复杂度:
乘加运算次数
左图 3x4 + 4x2 = 20
学习率:

指数衰减学习率:
可以先用较大的学习率,快速得到较优解,然后逐步减小学习率,使
模型在训练后期稳定。指数衰减学习率 = 初始学习率 * 学习率衰减率( 当前轮数 / 多少轮衰减一次 )
2.3 激活函数
优秀的激活函数:
• 非线性: 激活函数非线性时,多层神经网络可逼近所有函数
• 可微性: 优化器大多用梯度下降更新参数
• 单调性: 当激活函数是单调的,能保证单层网络的损失函数是凸函数
• 近似恒等性: f(x)≈x当参数初始化为随机小值时,神经网络更稳定
激活函数输出值的范围:
• 激活函数输出为有限值时,基于梯度的优化方法更稳定
• 激活函数输出为无限值时,建议调小学习率
Sigmoid函数:
$$
f(x) = \frac{1}{1 + e ^ {-x}}
$$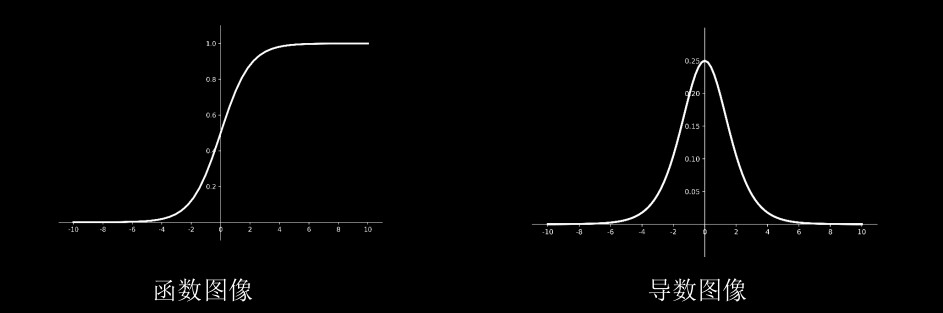
特点
(1)易造成梯度消失
(2)输出非0均值,收敛慢
(3)幂运算复杂,训练时间长
目前Sigmoid函数因计算复杂,已接近弃用。
Tanh函数:
$$
f(x) = \frac{1-e^{-2x}}{1+e^{-2x}}
$$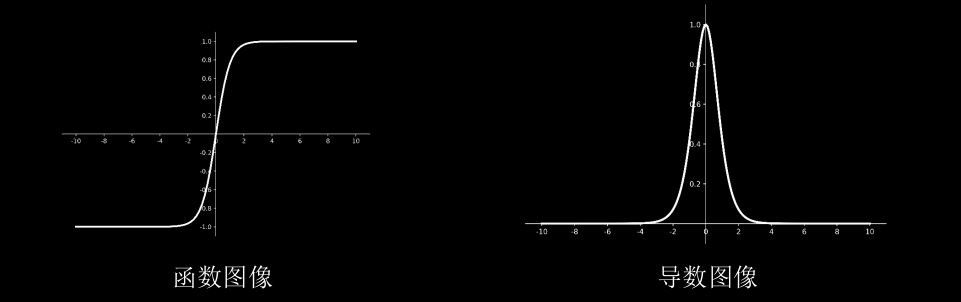
特点
(1)输出是0均值
(2)易造成梯度消失
(3)幂运算复杂,训练时间长
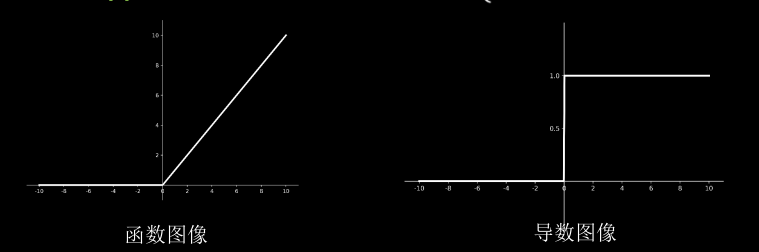
Relu函数:
$$
f(x) = max(x , 0) = \begin{cases}0 \quad x<0 \\ x \quad x\geq0 \end{cases}
$$
优点:
(1) 解决了梯度消失问题 (在正区间)
(2) 只需判断输入是否大于0,计算速度快
(3) 收敛速度远快于sigmoid和tanh
缺点:
(1) 输出非0均值,收敛慢
(2) Dead RelU问题:某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。(神经元死亡)
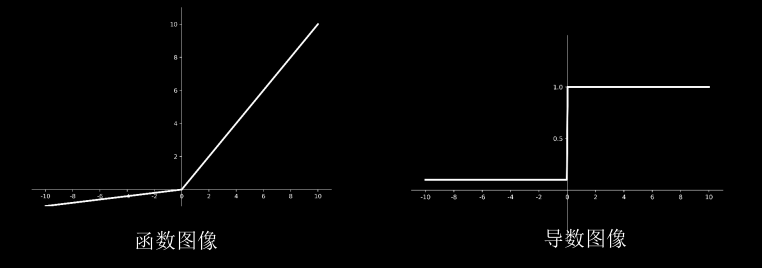
Leaky Relu函数:
$$
f(x) = max (ax,x)
$$
理论上来讲,Leaky Relu有Relu的所有优点,外加不会有Dead Relu问题,但是在实际操作当中,并没有完全证明Leaky Relu总是好于Relu。
对于初学者的建议:
首选relu激活函数;
学习率设置较小值;
输入特征标准化,即让输入特征满足以0为均值,1为标准差的正态分布;
初始参数中心化,即让随机生成的参数满足以0为均值,$\sqrt{\frac{2}{当前层输入特征个数}}$为标准差的正态分布。
2.4 损失函数
预测值(y)与已知答案(_y)的差距

均方误差mse:
$$
MSE(y_,y)=\frac{\sum_{i=1}^n (y-y_)^2}{n}
$$lost_mse = tf.reduce_mean(tf.square(y_-y))
自定义函数:
可在一定程度上优化实际问题中的预测误差。
交叉熵CE:
表明了两个概率分布之间的距离,交叉熵越大,表明两个概率分布越远
$$
H(y_,y) = - \sum y_ \times ln\ y
$$
交叉熵越小,证明数据距离真实越准确。
softmax与交叉熵的结合:
在TensorFlow中提供了函数tf.nn.softmax_cross_entropy_with_logits(y_,y)输出先过softmax函数,再计算y与y_的交叉熵损失函数。
2.5 缓解过拟合
欠拟合与过拟合
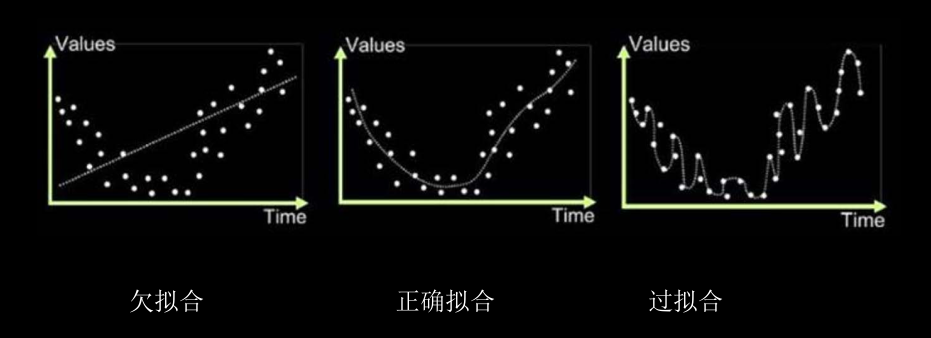
| 欠拟合的解决方法: 增加输入特征项 增加网络参数 减少正则化参数 |
过拟合的解决方法: 数据清洗 增大训练集 采用正则化 增大正则化参数 |
|---|
正则化缓解过拟合:
正则化在损失函数中引入模型复杂度指标,利用给W加权值,弱化了训练
数据的噪声(一般不正则化b)

正则化的选择
L1正则化大概率会使很多参数变为零,因此该方法可通过稀疏参数,即减少参数的数量,降低复杂度。
L2正则化会使参数很接近零但不为零,因此该方法可通过减小参数值的大小降低复杂度。
使用L2正则化缓解过拟合
1 | |
下表可以看出,L2正则化函数可有效的缓解过饱和现象
 |
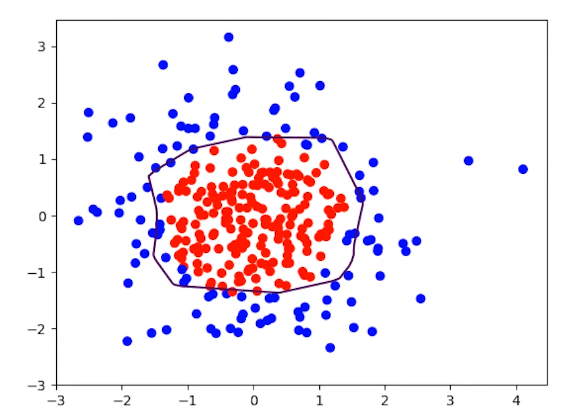 |
|---|
2.6 优化器
是引导神经网络更新参数的工具。
神经网络参数优化器:
待优化参数𝒘,损失函数loss,学习率lr,每次迭代一个batch,t表示当前batch迭代的总次数:
- 计算t时刻损失函数关于当前参数的梯度 $g_t=\triangledown loss = \frac{\partial loss}{\partial (w_t)} $
- 计算t时刻一阶动量 $m_t$ 和二阶动量$V_t$
- 计算t时刻下降梯度:$\eta_t =\frac{lr·m_t}{\sqrt{V_t}}$
- 计算t+1时刻参数:$w_{t+1} = w_t - \eta_t = w_t - \frac{lr·m_t}{\sqrt{V_t}}$
一阶动量:与梯度相关的函数
二阶动量:与梯度平方相关的函数
SGD(无momentum),常用的梯度下降算法:
$m_t = g_t $ $V_t = 1$
$\eta_t = \frac{lr·m_t}{\sqrt{V_t}} $
$w_{t+1} = w_t -\eta_t = w_t - \frac{lr·m_t}{\sqrt{V_t}} \ =w_t - lr·g_t $
$w_{t+1} = w_t -lr \ast \frac{\partial loss}{\partial w_t} \ 参数更新公式$
SGDM(含momentum的SGD),在SGD的基础上增加了一阶动量:
$m_{t-1}$表示上一时刻的一阶动量。
$m_t = \beta · m_{t-1} + (1-\beta )·g_t $ $V_t=1$
$\eta_t= \frac{lr·m_t}{\sqrt{V_t}} = lr· m_t =lr·(\beta · m_{t-1}+(1-\beta)·g_t)$
$w_{t+1}=w_t -\eta_t = w_t - lr · (\beta · m_{t-1}+(1-\beta)·g_t)$
Adagrad,在SGD基础上增加二阶动量:
$m_t=g_t$ $V_t=\sum_{\tau=1}^t g_\tau^2$
$\eta_t=\frac{lr·m_t}{\sqrt{V_t}} =\frac{lr·g_t}{\sqrt{\sum_{\tau=1}^t g_\tau^2}} $
$w_{t+1}=w_t-\eta_t=w_t-\frac{lr·g_t}{\sqrt{\sum_{\tau=1}^t g_\tau^2}}$
RMSProp,SGD基础上增加二阶动量:
$m_t=g_t$ $V_t = \beta · V_{t-1} + (1-\beta)·g_t^2 $
$\eta_t=\frac{lr·m_t}{\sqrt{V_t}} =\frac{lr·g_t}{\sqrt{ \beta · V_{t-1} + (1-\beta)·g_t^2}} $
$w_{t+1}=w_t-\eta_t=w_t-\frac{lr·g_t}{\sqrt{ \beta · V_{t-1} + (1-\beta)·g_t^2}}$
Adam, 同时结合SGDM一阶动量和RMSProp二阶动量:
$m_t=\beta_1 ·m_{t-1}+(1-\beta_1)·g_t$
修正一阶动量的偏差:$\widehat{m_t}=\frac{m_t}{1-\beta_1^t}$
$V_t=\beta_2 · V_{step-1}+(1-\beta_2)·g_t^2$
修正二阶动量的偏差:$ \widehat{V_t}= \frac{V_t} {1-\beta_2^t} $
$\eta_t=\frac{lr·\widehat{m_t} }{\sqrt{\widehat{V_t} } } = lr \cdot \frac{lr{\frac{m_t}{1-\beta_1^t} } }{\sqrt{ {\frac{V_t} {1-\beta_2^t} } } } $
$w_{t+1}=w_t-\eta_t=w_t-\frac{lr\cdot{\frac{m_t}{1-\beta_1^t} } }{\sqrt{ {\frac{V_t}{1-\beta_2^t} } } } $
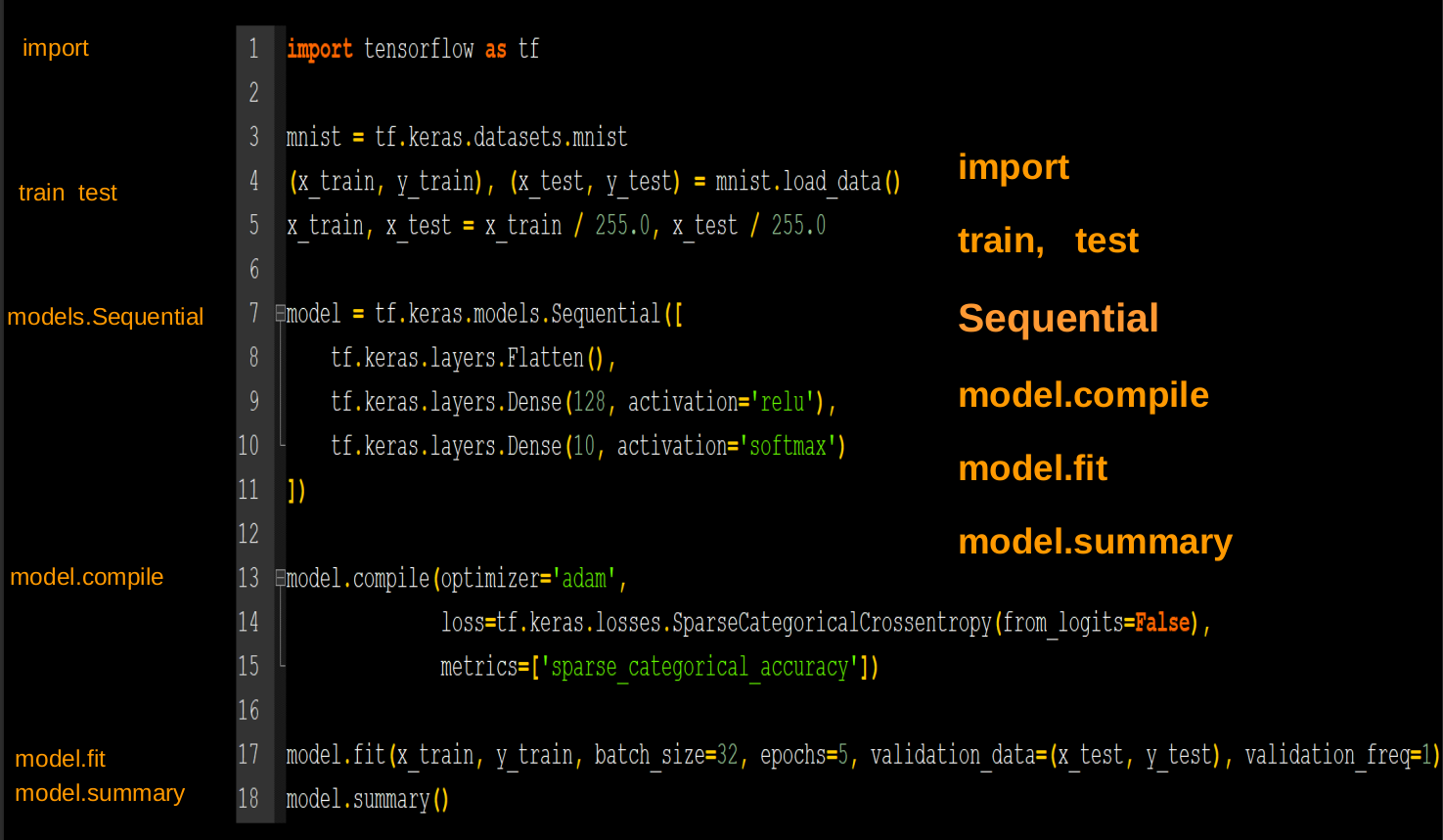
3.1 搭建网络八股Sequential
用Tensorflow API:tf.keras搭建网络八股
六步法
1 | |
model = tf.keras.models.Sequential ([ 网络结构 ]) #描述各层网络
Sequential是容器,给出从输入层到输出层的各层网络解构
拉直层: tf.keras.layers.Flatten( )
全连接层: tf.keras.layers.Dense(神经元个数, activation= "激活函数“ ,kernel_regularizer=哪种正则化)
activation(字符串给出)可选: relu、 softmax、 sigmoid 、 tanh
kernel_regularizer可选:tf.keras.regularizers.l1()tf.keras.regularizers.l2()
卷积层: tf.keras.layers.Conv2D(filters = 卷积核个数, kernel_size = 卷积核尺寸,
strides = 卷积步长, padding = “ valid” or “same”)
LSTM层: tf.keras.layers.LSTM()
model.compile(optimizer = 优化器,loss = 损失函数 metrics = [“准确率”] )
1 | |
model.fit (训练集的输入特征, 训练集的标签, batch_size= , epochs= , validation_data=(测试集的输入特征,测试集的标签), validation_split=从训练集划分多少比例给测试集, validation_freq = 多少次epoch测试一次)
使用sequential可以搭建出上层输出就是下层输入的下层网络机构,但无法写出一些带有跳连的非顺序网络结构,这时候可以选择用类Class搭建神经网络解构。
3.2 搭建网络八股Class
在六步法中,将第三部的Model改为class MyModel(Model) model=MyModel
1 | |
3.3 MNIST数据集
手写数字的数据集-上万张
导入MNIST数据集:
1 | |
为输入特征,输入神经网络时,将数据拉伸为一维数组:tf.keras.layers.Flatten( )
3.4 FASHION数据集
提供 6万张 28X28 像素点的衣裤等图片和标签,用于训练。
提供 1万张 28X28 像素点的衣裤等图片和标签,用于测试。
导入FASHION数据集:
1 | |
4.1 搭建网络八股总览
① 自制数据集,解决本领域应用
② 数据增强,扩充数据集
③ 断点续训,存取模型
④ 参数提取,把参数存入文本
⑤ acc/loss可视化,查看训练效果
⑥ 应用程序,给图识物
4.2 自制数据集
使用Py,目的是将文件夹内的图片读入,返回输入特征、标签。
标签文件txt
1 | |
第一次运行生成了npy格式的数据集。
第二次会加载数据集,执行训练过程。
4.3 数据增强
增大数据量,扩充数据集
1 | |
4.4 断点续训
可以存取模型
读取模型:load_weights(路径文件名)
可以先检查是否存在断点,如有则加载模型。
1 | |
保存模型: tf.keras.callbacks.ModelCheckpoint(filepath=路径文件名,save_weights_only=True/False,save_best_only=True/False) history = model.fit( callbacks=[cp_callback] )
4.5 参数提取
把参数存入文本
提取可训练参数
model.trainable_variables 返回模型中可训练的参数
设置print输出格式
np.set_printoptions(threshold=超过多少省略显示)
1 | |
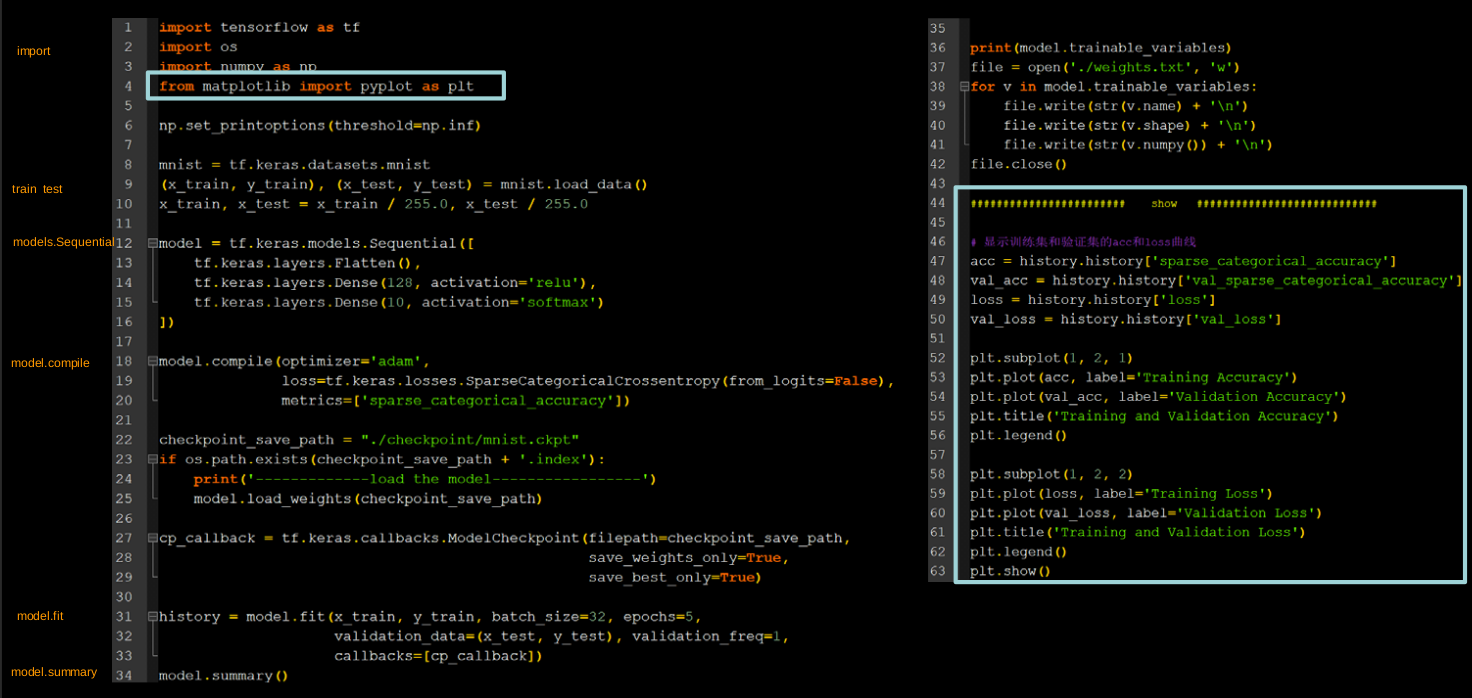
4.6 acc/loss可视化
acc曲线与loss曲线
history=model.fit(训练集数据, 训练集标签, batch_size=, epochs=,validation_split=用作测试数据的比例,validation_data=测试集,validation_freq=测试频率)
只是一段画图程序代码。
4.7 图片识别
给图识物
predict(输入特征,batch_size=整数)返回向前传播的计算结果
复现模型(前向传播):
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax’)])
加载参数:
model.load_weights(model_save_path
预测结果:
result = model.predict(x_predict)
5.1 卷积的计算过程 Convolutional
全连接 NN 特点:每个神经元与前后相邻层的每一个神经元都有连接关系。(可以实
现分类和预测)
全连接网络参数的个数为:$\sum(前层\times 后层 + 后层)$
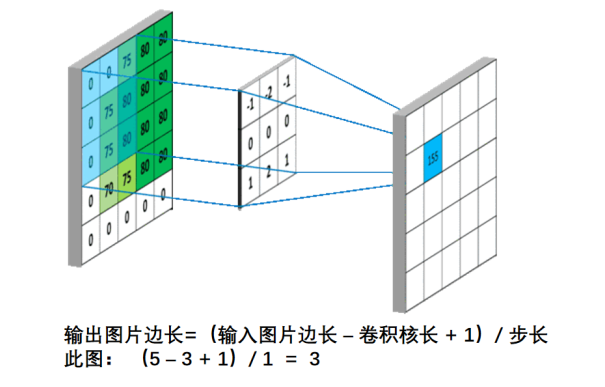
卷积的概念:卷积可以认为是一种有效提取图像特征的方法。一般会用一个正方形的
卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长,
卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出
特征的一个像素点。
对于彩色图像(多通道)来说,卷积核通道数与输入特征一致,套接后在对应位置上进行乘加和操作,如果是彩色图片(RGB)利用三通道卷积核对三通道的彩色特征图做卷积计算。
5.2 感受野
感受野(Receptive Field):卷积神经网络各输出特征图中的每个像素点,在原始输入图片上映射区域的大小。
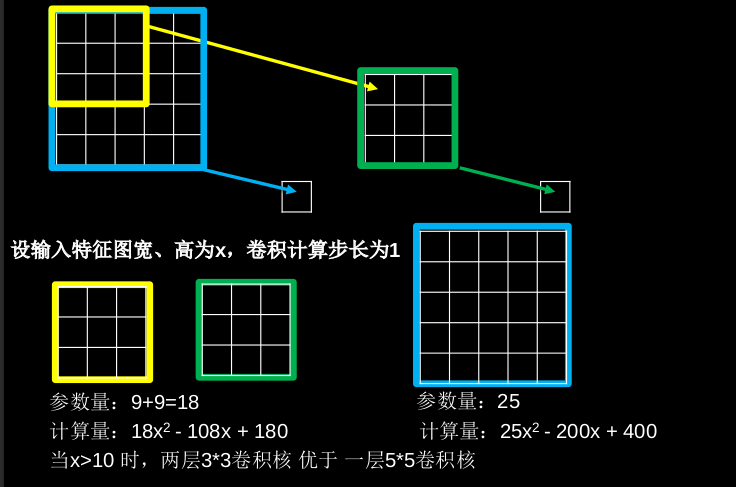
通常用两层3*3卷积核替换一层5*5卷积核
5.3 全零填充 Padding
将图的四周加上一圈零填充。

TF描述全零填充
用参数padding = ‘SAME’ 或 padding = ‘VALID’表示
SAME:5X5X1 –> 5X5X1 VALID:5X5X1–>3X3X1
可以让输出特征图和输出特征图的尺寸不变。
5.4 TF描述卷积计算层
1 | |
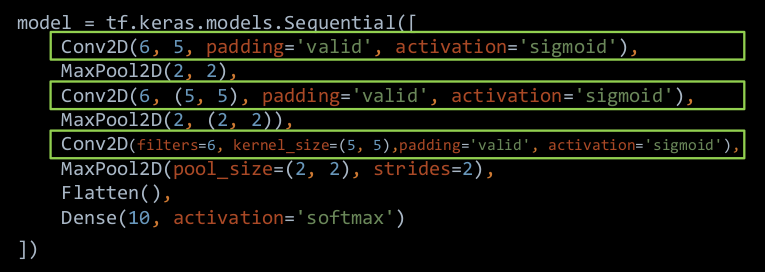
例如可以使用关键字传递参数的方法。
5.5 批标准化 BN
标准化:使数据符合0均值,1为标准差的分布。
批标准化:对一小批数据(batch),做标准化处理 。
批标准化后,第 k个卷积核的输出特征图(feature map)中第 i 个像素点


5.6 池化 Pooling
池化用于减少特征数据量。平均池化和最大池化
1 | |

5.7 舍弃 Dropout
在神经网络训练时,将一部分神经元按照一定概率从神经网络中暂时舍弃。神经网络使用时,被舍弃的神经元恢复链接。
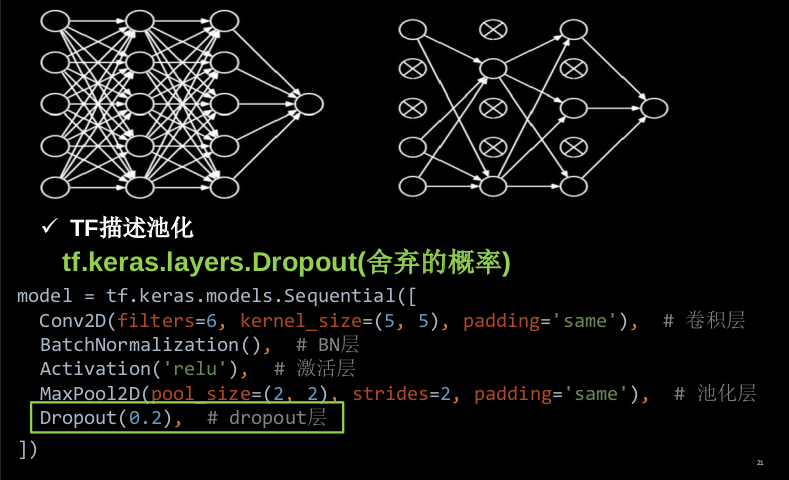
5.8 卷积神经网络
卷积是什么? 卷积就是特征提取器,就是CBAPD


5.9 Cifar10数据集 卷积神经网络搭建示例
提供 5万张 32*32 像素点的十分类彩色图片和标签,用于训练。
提供 1万张 32*32 像素点的十分类彩色图片和标签,用于测试。
1 | |
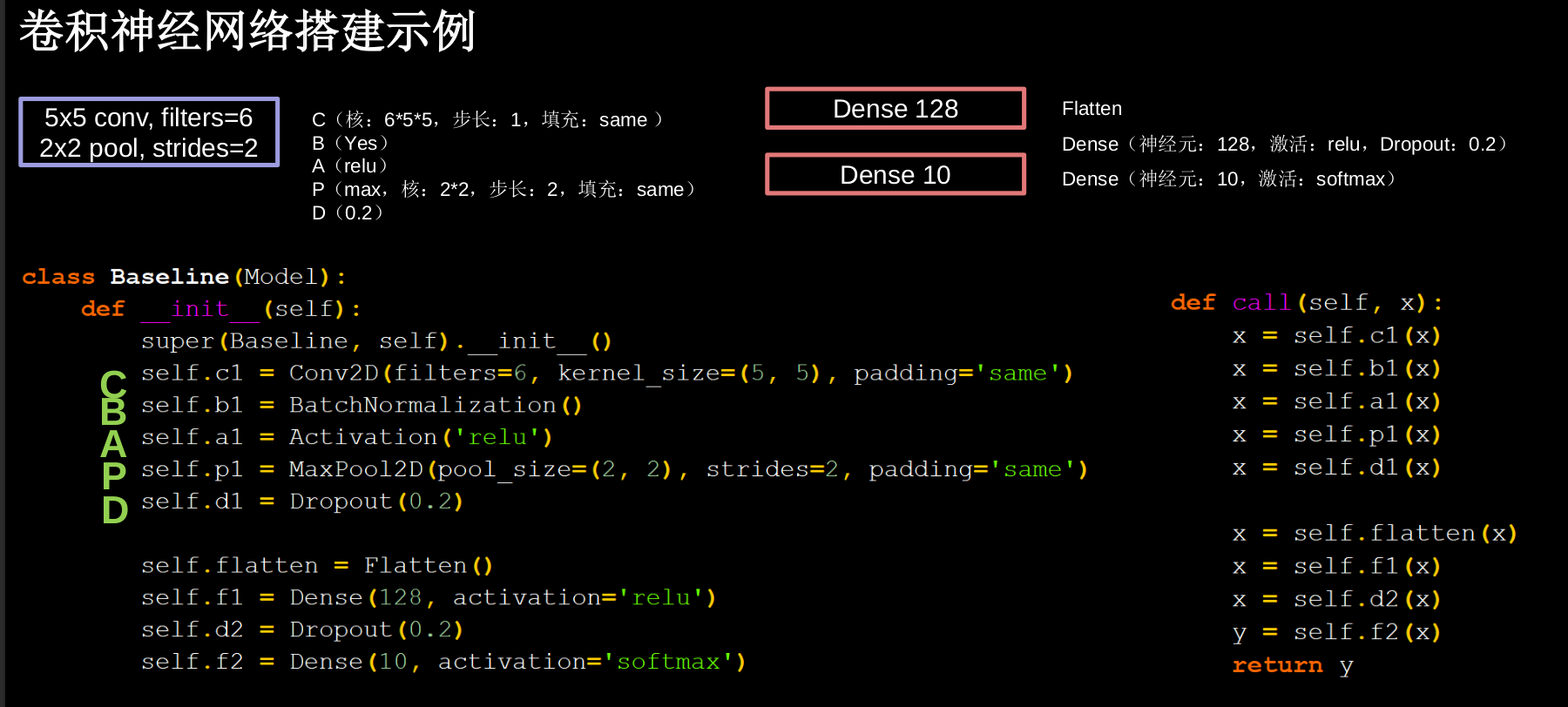
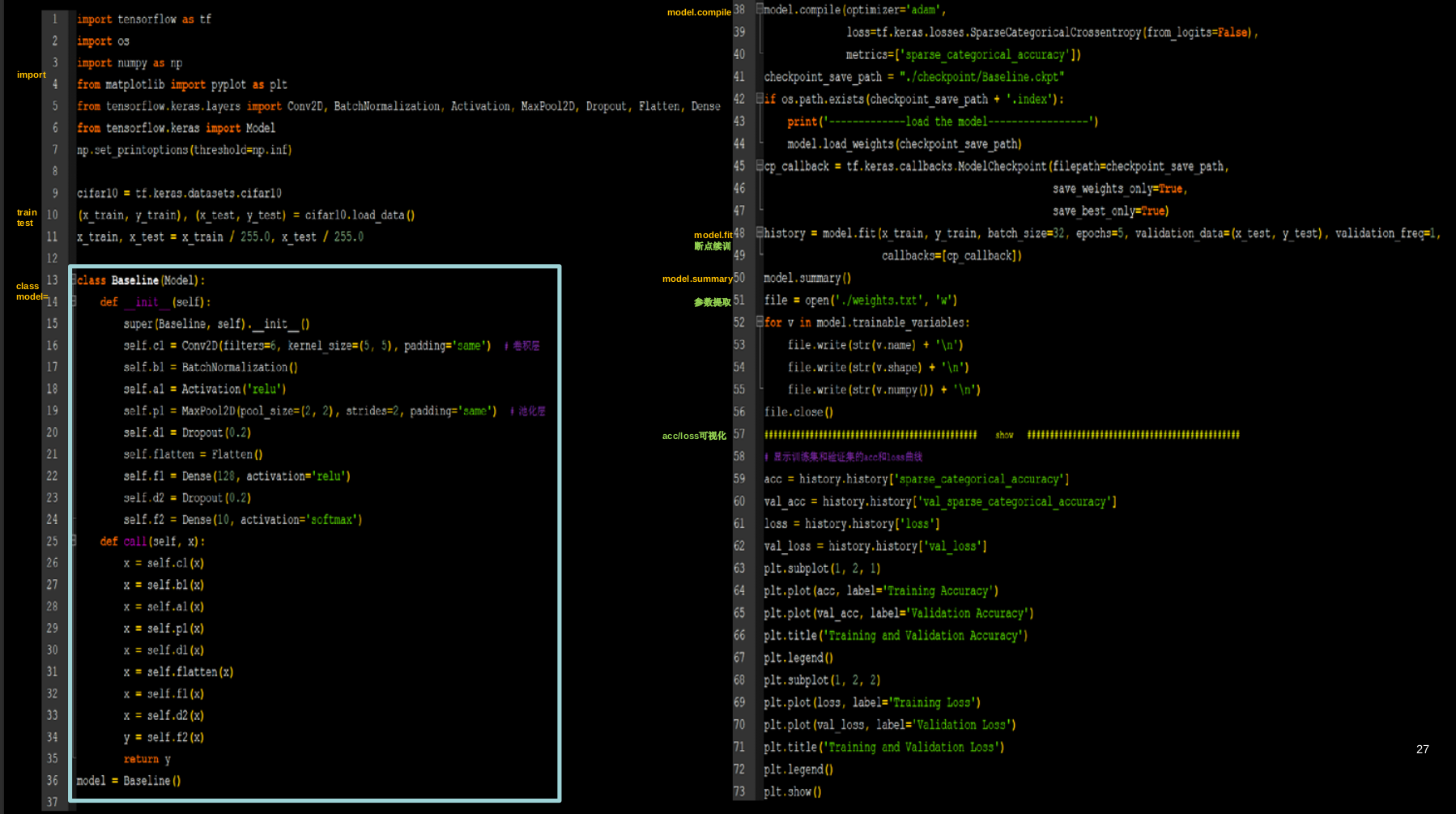
5.10 LeNet AlexNet VGGNet InceptionNet ResNet
LeNet由Yann LeCun于1998年提出,卷积网络开篇之作。
AlexNet网络诞生于2012年,当年ImageNet竞赛的冠军,Top5错误率为16.4%。
VGGNet诞生于2014年,当年ImageNet竞赛的亚军,Top5错误率减小到7.3%。
InceptionNet诞生于2014年,当年ImageNet竞赛冠军,Top5错误率为6.67%
ResNet诞生于2015年,当年ImageNet竞赛冠军,Top5错误率为3.57%
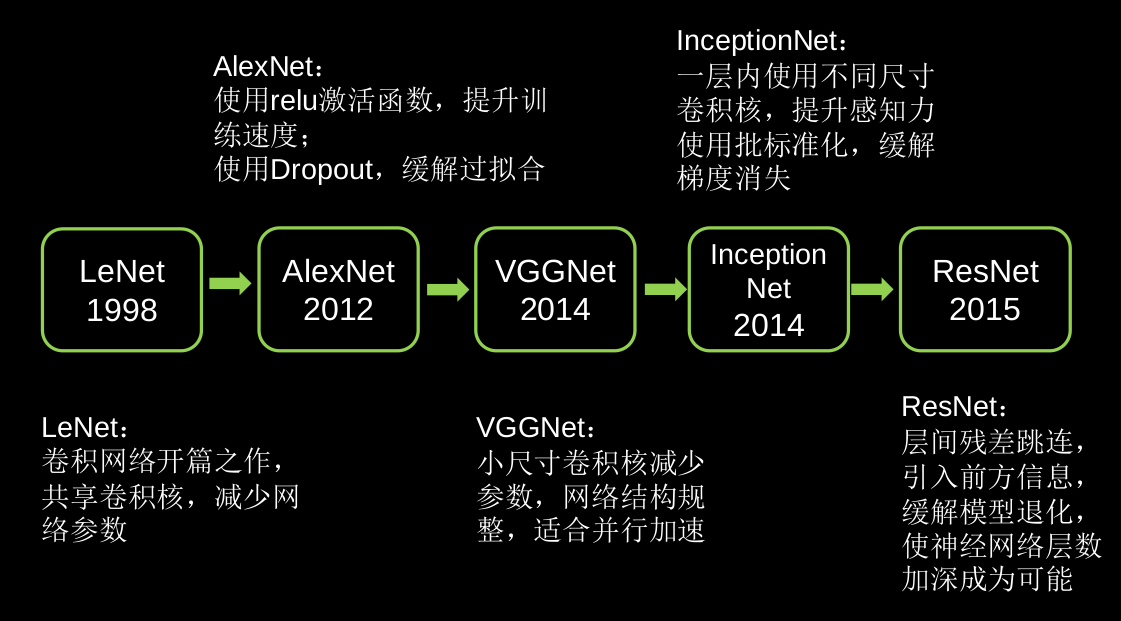
6.1 循环核
循环核:参数时间共享,循环层提取时间信息。

6.2 循环核按时间步展开
循环神经网络:借助循环核提取时间特征后,送入全连接网络。
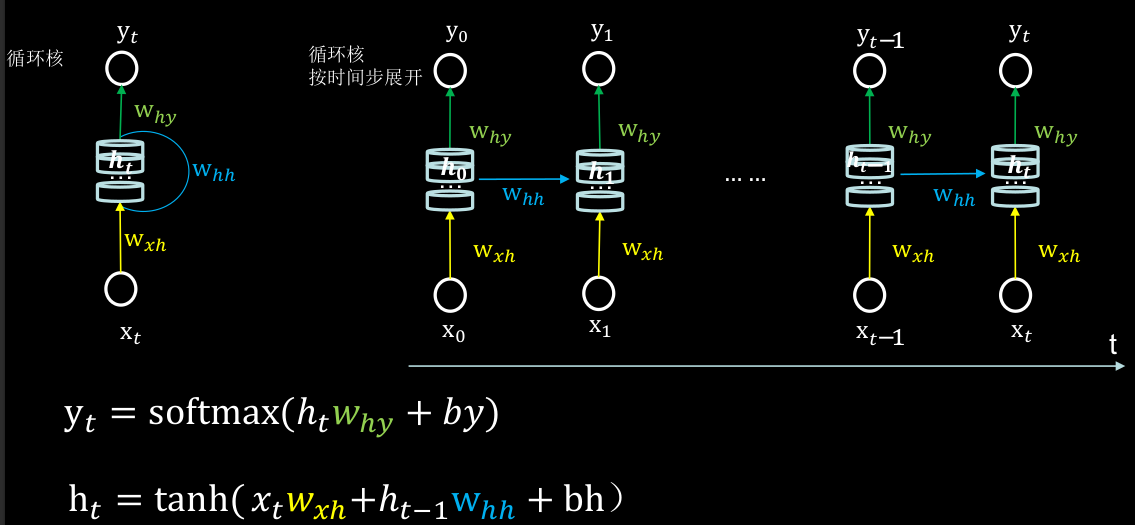
循环计算层:向输出方向生长。
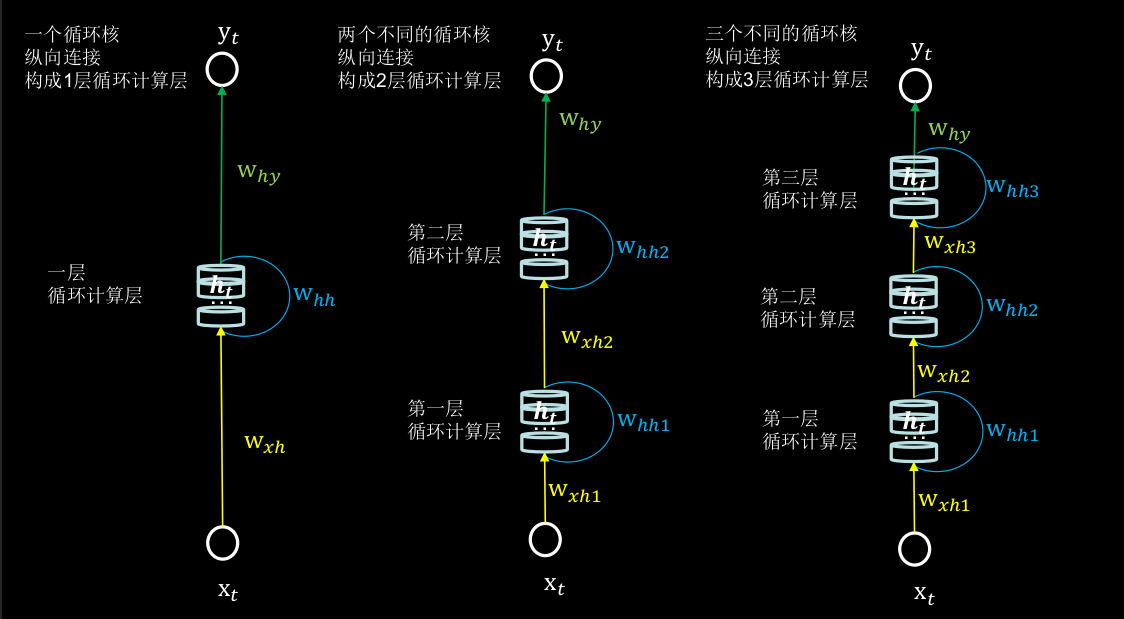
6.3 TF描述循环计算层
1 | |
入RNN时, x_train维度:
[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
6.4 循环计算过程-字母输入预测
字母预测:输入a预测出b,输入b预测出c,
输入c预测出d,输入d预测出e,输入e预测出a
用RNN实现输入一个字母,预测下一个字母
(One hot 编码)独热码
用RNN实现输入连续四个字母,预测下一个字母
(One hot 编码)
用RNN实现输入一个字母,预测下一个字母
(Embedding 编码)
用RNN实现输入连续四个字母,预测下一个字母
(Embedding 编码)
6.5 股票预测
用RNN实现股票预测
用LSTM实现股票预测
LSTM 由Hochreiter & Schmidhuber 于1997年提出,通过门控单元改善了RNN长期依赖问题。
用GRU实现股票预测
GRU由Cho等人于2014年提出,优化LSTM结构。
更新于:2024