2-工具与软件-2-Pandas
安装
在pycharm中对应的python解释器内安装pandas。
1 | |
Output:
1 | |
Pandas 数据结构 - Series
Series 相当于表格中的一个列,函数如下:
pandas.Series( data, index, dtype, name, copy)
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
也可以使用Map来创建Series:
1 | |
这样Key就变为了索引值。
Pandas 数据结构 - DataFrame
DataFrame 是一个表格型的数据结构,由一个index组成的第0列和DataFrame组成的n列构成,相当于Series组成的字典(共用一个index)。
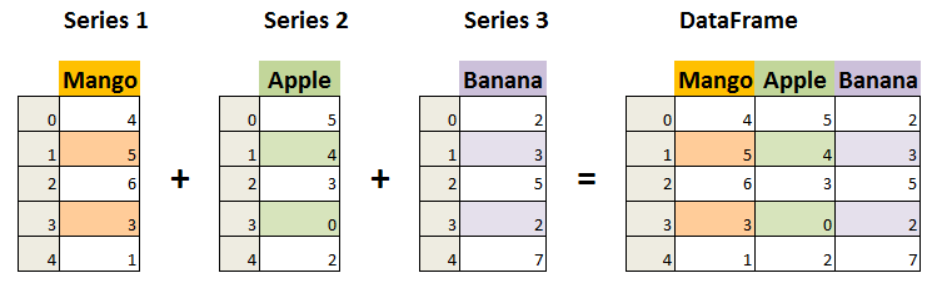
函数如下:
pandas.DataFrame( data, index, columns, dtype, copy)
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
使用ndarrays创建DataFrame对象:
1 | |
Site Age为列名,0、1、2为行标。
使用Map创建与Series同理。
Pandas CSV 文件
Pandas 可以很方便的处理 CSV 文件
df = pd.read_csv('nba.csv')读取CSV文件。
df.to_csv('site.csv')将DataFrame储存为csv文件。
数据处理
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
info() 方法返回表格的一些基本信息:
Pandas JSON 文件
Pandas 可以很方便的处理 JSON 数据
to_string() 用于返回 DataFrame(表格) 类型的数据,我们也可以直接处理 JSON 字符串。
如果是字符串格式的 JSON 可以直接将Python字典转为DataFrame数据(json对象与Map有相同的格式)
Json数据的解析
直接加载一个print一个json文件打印出的并不直观。
1 | |
用到 json_normalize() 方法将内嵌的数据完整的解析出来
1 | |
Output:
1 | |
读取一组数据glom
import pandas as pd
from glom import glom glom模块准许使用“.”来获取内嵌对象的属性
data = df['students'].apply(**lambda** row: glom(row, 'grade.math'))
效果类似于查找。
Pandas 数据清洗
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理(清洗)。
例如数据中的“n/a NA – na”,或者空值等。
清洗空值:dropna()方法
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=’all’ 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
可以先用isnull()判断是否为空。
可以在read_csv()方法中指定空数据的数据类型:
1 | |
dropna会返回一个新的Dataframe不会修改源数据。如果需要修改在inplace设置为True。
移除指定列有空值的行(移除 ST_NUM 列值为空)df.dropna(subset=['ST_NUM'], inplace = True)
我们也可以 fillna() 方法来替换一些空字段df.fillna(12345, inplace = True)
指定某一个列来替换数据df['PID'].fillna(12345, inplace = True)
替换空单元格的常用方法是计算列的均值、中值或众数。
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
比如mode() 方法计算列的众数并替换空单元格:
1 | |
清洗格式错误数据:
1 | |
清洗错误数据:
1 | |
清洗重复数据:
如果我们要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。
如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
Pandas 常用函数
读取数据
| 函数 | 说明 |
|---|---|
| pd.read_csv(filename) | 读取 CSV 文件; |
| pd.read_excel(filename) | 读取 Excel 文件; |
| pd.read_sql(query, connection_object) | 从 SQL 数据库读取数据; |
| pd.read_json(json_string) | 从 JSON 字符串中读取数据; |
| pd.read_html(url) | 从 HTML 页面中读取数据。 |
查看数据
| 函数 | 说明 |
|---|---|
| df.head(n) | 显示前 n 行数据; |
| df.tail(n) | 显示后 n 行数据; |
| df.info() | 显示数据的信息,包括列名、数据类型、缺失值等; |
| df.describe() | 显示数据的基本统计信息,包括均值、方差、最大值、最小值等; |
| df.shape | 显示数据的行数和列数。 |
数据清洗
| 函数 | 说明 |
|---|---|
| df.dropna() | 删除包含缺失值的行或列; |
| df.fillna(value) | 将缺失值替换为指定的值; |
| df.replace(old_value, new_value) | 将指定值替换为新值; |
| df.duplicated() | 检查是否有重复的数据; |
| df.drop_duplicates() | 删除重复的数据。 |
数据选择和切片
| 函数 | 说明 |
|---|---|
| df[column_name] | 选择指定的列; |
| df.loc[row_index, column_name] | 通过标签选择数据; |
| df.iloc[row_index, column_index] | 通过位置选择数据; |
| df.ix[row_index, column_name] | 通过标签或位置选择数据; |
| df.filter(items=[column_name1, column_name2]) | 选择指定的列; |
| df.filter(regex=’regex’) | 选择列名匹配正则表达式的列; |
| df.sample(n) | 随机选择 n 行数据。 |
数据排序
| 函数 | 说明 |
|---|---|
| df.sort_values(column_name) | 按照指定列的值排序; |
| df.sort_values([column_name1, column_name2], ascending=[True, False]) | 按照多个列的值排序; |
| df.sort_index() | 按照索引排序。 |
数据分组和聚合
| 函数 | 说明 |
|---|---|
| df.groupby(column_name) | 按照指定列进行分组; |
| df.aggregate(function_name) | 对分组后的数据进行聚合操作; |
| df.pivot_table(values, index, columns, aggfunc) | 生成透视表。 |
数据合并
| 函数 | 说明 |
|---|---|
| pd.concat([df1, df2]) | 将多个数据框按照行或列进行合并; |
| pd.merge(df1, df2, on=column_name) | 按照指定列将两个数据框进行合并。 |
数据选择和过滤
| 函数 | 说明 |
|---|---|
| df.loc[row_indexer, column_indexer] | 按标签选择行和列。 |
| df.iloc[row_indexer, column_indexer] | 按位置选择行和列。 |
| df[df[‘column_name’] > value] | 选择列中满足条件的行。 |
| df.query(‘column_name > value’) | 使用字符串表达式选择列中满足条件的行。 |
数据统计和描述
| 函数 | 说明 |
|---|---|
| df.describe() | 计算基本统计信息,如均值、标准差、最小值、最大值等。 |
| df.mean() | 计算每列的平均值。 |
| df.median() | 计算每列的中位数。 |
| df.mode() | 计算每列的众数。 |
| df.count() | 计算每列非缺失值的数量。 |
UPDATE TIME: 星期二 2023年9月19日